目录
一、问题描述
Java 后端使用雪花算法生成 Long 类型的主键 ID,在返回前端后,会出现后三位精度丢失的问题。


我们写一个 ControllerAdvice 打印一下返回结果看下:

我们可以看到返回结果是没有问题的,但是返回到前端就会丢失两位精度。
二、问题复现
这里主要描述问题的复现过程和代码,不需要的可以直接跳过。
1.Maven依赖
<!-- Hutool,用于生成雪花算法ID -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
<!-- Thymeleaf,用于展示页面 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
2.application.yml 配置
server:
port: 8080
spring:
mvc:
view:
prefix: /templates/
suffix: .html
3.DemoController.java
import cn.hutool.core.util.IdUtil;
import com.demo.common.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
/**
* <p> @Title DemoController
* <p> @Description 测试Controller
*
* @author ACGkaka
* @date 2023/4/24 18:02
*/
@Slf4j
@Controller
@RequestMapping("/demo")
public class DemoController {
@GetMapping("/snowflakePage")
public String snowflakePage() {
return "snowflakePage";
}
@GetMapping("/snowflakeId")
@ResponseBody
public Result<Object> snowflakeId() {
return Result.succeed().setData(IdUtil.getSnowflakeNextId());
}
}
4.snowflakePage.html 页面
页面文件在 resources/templates/ 路径下。
<!DOCTYPE html>
<html>
<head>
<title>调用接口并打印返回值</title>
</head>
<body>
<button onclick="getSnowflakeId()">调用接口</button>
<script>
function getSnowflakeId() {
fetch('/demo/snowflakeId')
.then(response => response.json())
.then(data => {
console.log(data.data);
document.body.innerHTML += `<p>${data.data}</p>`;
})
.catch(error => console.log(error));
}
</script>
</body>
</html>
5.DemoControllerAdvice.java 监听
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;
/**
* <p> @Title DemoControllerAdvice
* <p> @Description Controller增强
*
* @author ACGkaka
* @date 2023/4/25 21:07
*/
@ControllerAdvice
public class DemoControllerAdvice implements ResponseBodyAdvice {
@Override
public boolean supports(MethodParameter methodParameter, Class aClass) {
return true;
}
@Override
public Object beforeBodyWrite(Object body, MethodParameter methodParameter, MediaType mediaType, Class aClass, ServerHttpRequest serverHttpRequest, ServerHttpResponse serverHttpResponse) {
System.out.println("body is: " + body);
return body;
}
}
6.问题复现
请求地址:http://localhost:8080/demo/snowflakePage
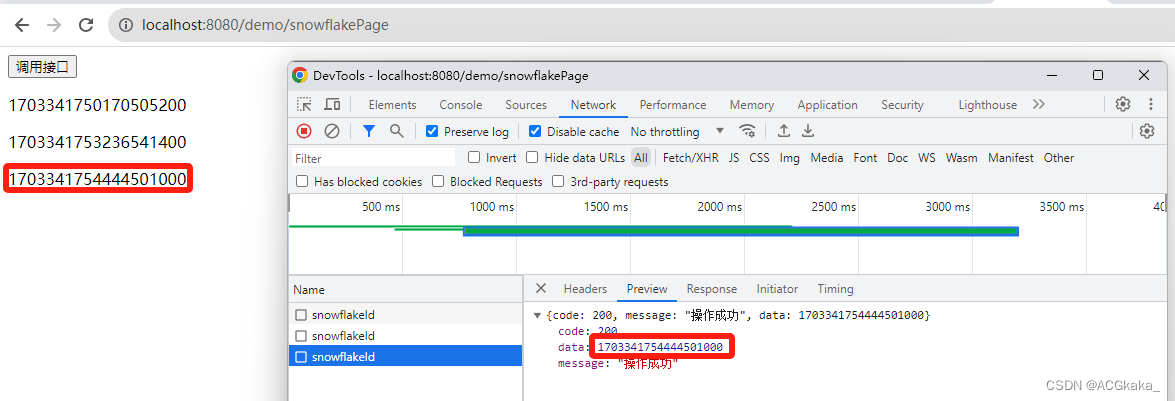

精度丢失问题复现,下面我们来分析下导致问题的原因。
三、原因分析
- 后端返回:
1703327682407702528 - 前端接收:
1703327682407702500
这是因为 JS 是弱语言,前端接收数字类型参数为 number,最大接受长度为 16 位,超出长度则会丢失精度。而 Java 的 Long 类型长度是 19 位,所以传输到前端的后三位精度丢失。
解决问题的思路:把 Java 中 Long 类型转换为 String 类型返回给前端。
四、问题解决
方案一
将所有 ID 使用 String 类型存储,缺点是字符串做 ID 查询效率比较低。
方案二
使用注解、配置类,改变序列化过程。
注解方式,适用于 pojo 的 id 属性上。
import com.baomidou.mybatisplus.annotation.TableId;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
/**
* 主键
*/
@TableId
@JsonSerialize(using = ToStringSerializer.class)
private Long id;
配置类方式,适用于全局配置。
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
@Configuration
public class JacksonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder)
{
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
// 全局配置序修改列化返回 Json 处理方案
SimpleModule simpleModule = new SimpleModule();
// Json Long --> String
simpleModule.addSerializer(Long.class, ToStringSerializer.instance);
objectMapper.registerModule(simpleModule);
return objectMapper;
}
}
根据问题复现代码,再次请求地址:http://localhost:8080/demo/snowflakePage
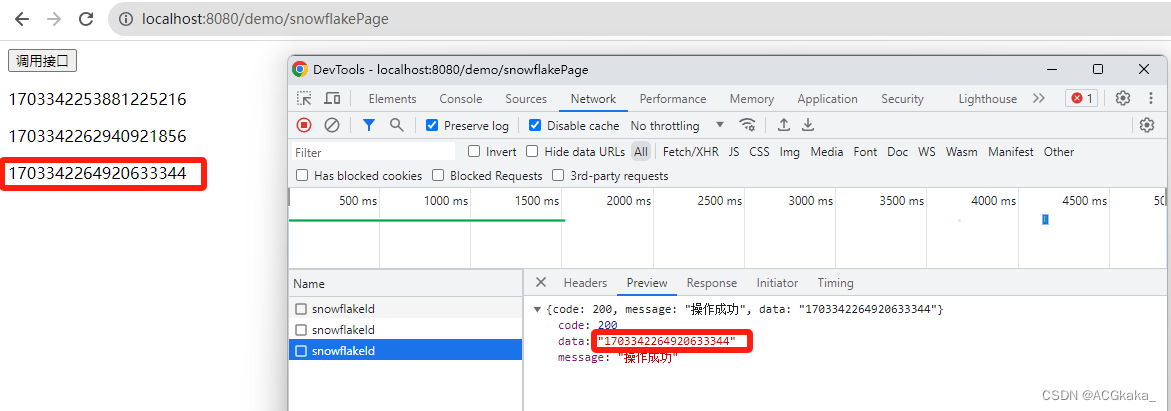

精度丢失问题已修复。
整理完毕,完结撒花~ 🌻
参考地址:
1.解决雪花算法生成的ID传输前端后精度丢失,https://blog.csdn.net/weixin_48841931/article/details/127966871






