目录
背景:LeNet-5是一个经典的CNN,由Yann LeCun在1998年提出,旨在解决手写数字识别问题。

一、知识点
1. iter()+next()
iter():返回迭代器
next():使用next()来获取下一条数据
data = [1, 2, 3]
data_iter = iter(data)
print(next(data_iter)) # 1
print(next(data_iter)) # 2
print(next(data_iter)) # 32. enumerate
enumerate(sequence,[start=0]) 函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
start--下标起始位置的值。
data = ['zs', 'ls', 'ww']
print(list(enumerate(data)))
# [(0, 'zs'), (1, 'ls'), (2, 'ww')]3. torch.no_grad()
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
当requires_grad设置为False时,在反向传播时就不会自动求导了,可以节约存储空间。
4. torch.max(input,dim)
input -- tensor类型
dim=0 -- 行比较
dim=1 -- 列比较
import torch
data = torch.Tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
x = torch.max(data, dim=0)
print(x)
# values=tensor([7., 8., 9.]),
# indices=tensor([2, 2, 2])
x = torch.max(data, dim=1)
print(x)
# values=tensor([3., 6., 9.]),
# indices=tensor([2, 2, 2])
5. torch.eq:对两个张量Tensor进行逐个元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。
注意:item返回一个数。
import torch
data1 = torch.tensor([1, 2, 3, 4, 5])
data2 = torch.tensor([2, 3, 3, 9, 5])
x = torch.eq(data1, data2)
print(x) # tensor([False, False, True, False, True])
sum = torch.eq(data1, data2).sum()
print(sum) # tensor(2)
sum_item = torch.eq(data1, data2).sum().item()
print(sum_item) # 26. squeeze(input,dim)函数
squeeze(0):若第一维度值为1,则去除第一维度
squeeze(1):若第二维度值为2,则去除第二维度
squeeze(-1):去除最后维度值为1的维度
7. unsqueeze(input,dim)
增加大小为1的维度,即返回一个新的张量,对输入的指定位置插入维度 1且必须指明维度。
二、代码
model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) # output(16,28,28)
self.pool1 = nn.MaxPool2d(2, 2) # output(16,14,14)
self.conv2 = nn.Conv2d(16, 32, 5) # output(32,10,10)
self.pool2 = nn.MaxPool2d(2, 2) # output(32,5,5)
self.fc1 = nn.Linear(32 * 5 * 5, 120) # output:120
self.fc2 = nn.Linear(120, 84) # output:84
self.fc3 = nn.Linear(84, 10) # output:10
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 32 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
train.py
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from model import LeNet
def main():
# preprocess data
transform = transforms.Compose([
# Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
transforms.ToTensor(),
# (mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 训练集 如果数据集已经下载了,则download=False
train_data = torchvision.datasets.CIFAR10('./data', train=True, transform=transform, download=False)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=36, shuffle=True, num_workers=0)
# 验证集
val_data = torchvision.datasets.CIFAR10('./data', train=False, download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=10000, shuffle=False, num_workers=0)
# 返回迭代器
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# loop over the dataset multiple times
for epoch in range(5):
epoch_loss = 0
for step, data in enumerate(train_loader, start=0):
# get the inputs from train_loader;data is a list of[inputs,labels]
inputs, labels = data
# 在处理每一个batch时并不需要与其他batch的梯度混合起来累积计算,因此需要对每个batch调用一遍zero_grad()将参数梯度设置为0
optimizer.zero_grad()
# 1.forward
outputs = net(inputs)
# 2.loss
loss = loss_function(outputs, labels)
# 3.backpropagation
loss.backward()
# 4.update x by optimizer
optimizer.step()
# print statistics
# 使用item()取出的元素值的精度更高
epoch_loss += loss.item()
# print every 500 mini-batches
if step % 500 == 499:
with torch.no_grad():
outputs = net(val_image)
predict_y = torch.max(outputs, dim=1)[1] # [0]取每行最大值,[1]取每行最大值的索引
val_accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[epoch:%d step:%5d] train_loss:%.3f test_accuracy:%.3f' % (
epoch + 1, step + 1, epoch_loss / 500, val_accuracy))
epoch_loss = 0
print('Train finished!')
sava_path = './model/LeNet.pth'
torch.save(net.state_dict(), sava_path)
if __name__ == '__main__':
main()

predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(), # CHW格式
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
net = LeNet()
net.load_state_dict(torch.load('./model/LeNet.pth'))
image = Image.open('./predict/2.png') # HWC格式
image = transform(image)
image = torch.unsqueeze(image, dim=0) # 在第0维加一个维度 #[N,C,H,W] N:Batch批处理大小
with torch.no_grad():
outputs = net(image)
predict = torch.max(outputs, dim=1)[1]
print(classes[predict])
if __name__ == '__main__':
main()
2.png


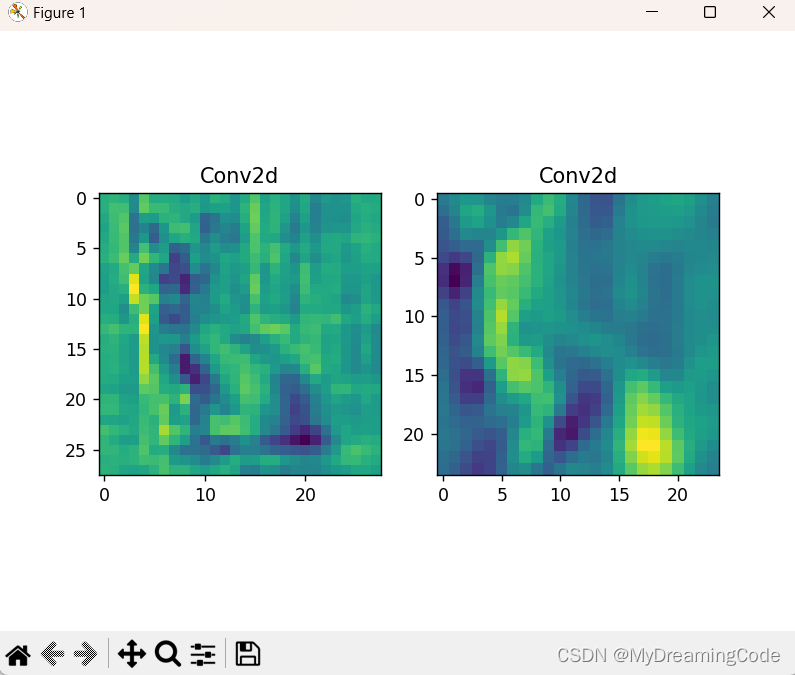
三、查看卷积层的feature map
1. 查看每层信息
for i in net.children():
print(i) 2. show_featureMap.py
2. show_featureMap.py
import torch
import torch.nn as nn
from model import LeNet
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
def main():
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(), # CHW格式
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
image = Image.open('./predict/2.png') # HWC格式
image = transform(image)
image = torch.unsqueeze(image, dim=0) # 在第0维加一个维度 #[N,C,H,W] N:Batch批处理大小
net = LeNet()
net.load_state_dict(torch.load('./model/LeNet.pth'))
conv_weights = [] # 模型权重
conv_layers = [] # 模型卷积层
counter = 0 # 模型里有多少个卷积层
# 1.将卷积层以及对应权重放入列表中
model_children = list(net.children())
for i in range(len(model_children)):
if type(model_children[i]) == nn.Conv2d:
counter += 1
conv_weights.append(model_children[i].weight)
conv_layers.append(model_children[i])
outputs = []
names = []
for layer in conv_layers[0:]:
# 2.每个卷积层对image进行计算
image = layer(image)
outputs.append(image)
names.append(str(layer))
# 3.进行维度转换
print(outputs[0].shape) # torch.Size([1, 16, 28, 28]) 1-batch 16-channel 28-H 28-W
print(outputs[0].squeeze(0).shape) # torch.Size([16, 28, 28]) 去除第0维
# 将16颜色通道的feature map加起来,变为一张28×28的feature map,sum将所有灰度图映射到一张
print(torch.sum(outputs[0].squeeze(0), 0).shape) # torch.Size([28, 28])
processed_data = []
for feature_map in outputs:
feature_map = feature_map.squeeze(0) # torch.Size([16, 28, 28])
gray_scale = torch.sum(feature_map, 0) # torch.Size([28, 28])
# 取所有灰度图的平均值
gray_scale = gray_scale / feature_map.shape[0]
processed_data.append(gray_scale.data.numpy())
# 4.可视化特征图
figure = plt.figure()
for i in range(len(processed_data)):
x = figure.add_subplot(1, 2, i + 1)
x.imshow(processed_data[i])
x.set_title(names[i].split('(')[0])
plt.show()
if __name__ == '__main__':
main()