缓冲区管理器、存储和后端进程之间的关系
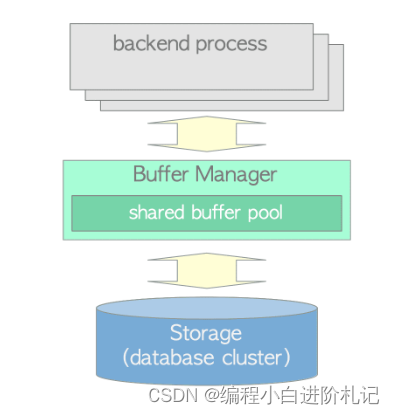
缓存管理结构
PostgreSQL 缓冲区管理器由buffer table、buffer descriptors和buffer pool组成。buffer pool层存储表和索引等数据文件页,以及空闲空间映射和可见性映射。buffer pool是一个数组,每个槽存储数据文件的一个页面。缓冲池数组的索引称为 buffer_ids。
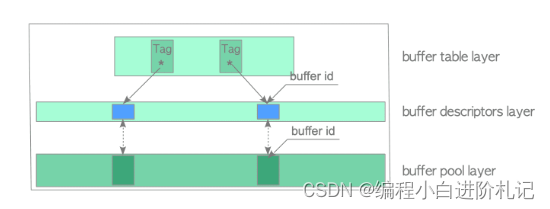
- Buffer pool:存储数据文件页面的数组。数组中的每个槽称为缓冲区_ids。
- Buffer descriptors:缓冲区描述符数组。每个描述符与一个缓冲池插槽一一对应,并保存相应插槽中存储页面的元数据。
- Buffer table:哈希表,用于存储已存储页面的缓冲区标签(buffer_tags)与保存已存储页面各自元数据的描述符缓冲区标识(buffer_ids)之间的关系。
Buffer table
缓冲表在逻辑上可分为三个部分:hash function、hash bucket slots和data entries
内置hash function将buffer_tags映射到hash bucket slots。尽管hash bucket的数量多于bucket slots的数量,但仍可能发生碰撞。因此,缓冲区表使用单独的链表方法来解决碰撞问题。当数据条目被映射到同一个缓冲区槽时,这种方法会将条目存储在同一个链表中。
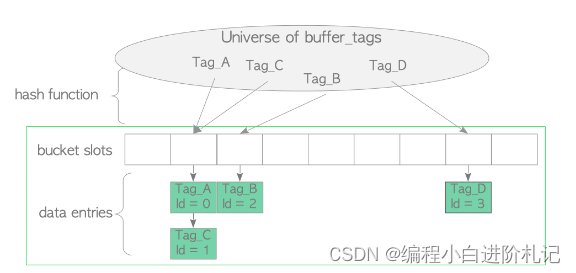
data entries由两个值组成:页面的缓冲区标签(buffer_tag)和保存页面元数据的描述符的缓冲区 ID
Buffer_tag
/*
* Buffer tag identifies which disk block the buffer contains.
*
* Note: the BufferTag data must be sufficient to determine where to write the
* block, without reference to pg_class or pg_tablespace entries. It's
* possible that the backend flushing the buffer doesn't even believe the
* relation is visible yet (its xact may have started before the xact that
* created the rel). The storage manager must be able to cope anyway.
*
* Note: if there's any pad bytes in the struct, InitBufferTag will have
* to be fixed to zero them, since this struct is used as a hash key.
*/
typedef struct buftag
{
Oid spcOid; /* tablespace oid */
Oid dbOid; /* database oid */
RelFileNumber relNumber; /* relation file number */
ForkNumber forkNum; /* fork number */
BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag;
在 PostgreSQL 中,所有数据文件的每个页面都可以分配一个唯一的标签,即缓冲区标签。当缓冲区管理器收到请求时,PostgreSQL 会使用所需页面的缓冲区标签。
- specOid: 包含目标页面的关系所属表空间的 OID。
- dbOid: 包含目标页面的关系所属数据库的 OID。
- relNumber: 包含目标页面的关系文件的编号。
- blockNum: 目标页面在关系中的块编号。
- forkNum:分叉编号: 页面所属关系的 fork 编号。表、自由空间映射和可见性映射的叉号分别定义为 0、1 和 2。
Buffer Descriptor
/*
* Flags for buffer descriptors
*
* Note: BM_TAG_VALID essentially means that there is a buffer hashtable
* entry associated with the buffer's tag.
*/
#define BM_LOCKED (1U << 22) /* buffer header is locked */
#define BM_DIRTY (1U << 23) /* data needs writing */
#define BM_VALID (1U << 24) /* data is valid */
#define BM_TAG_VALID (1U << 25) /* tag is assigned */
#define BM_IO_IN_PROGRESS (1U << 26) /* read or write in progress */
#define BM_IO_ERROR (1U << 27) /* previous I/O failed */
#define BM_JUST_DIRTIED (1U << 28) /* dirtied since write started */
#define BM_PIN_COUNT_WAITER (1U << 29) /* have waiter for sole pin */
#define BM_CHECKPOINT_NEEDED (1U << 30) /* must write for checkpoint */
#define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged,
* or init fork) */
#define PG_HAVE_ATOMIC_U32_SUPPORT
typedef struct pg_atomic_uint32
{
volatile uint32 value;
} pg_atomic_uint32;
typedef struct BufferDesc
{
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state;
int wait_backend_pgprocno; /* backend of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc;
- tag :是相应缓冲池插槽中存储页面的缓冲区标签。
- buf_id :标识描述符。
- content_lock :是一个轻量级锁,用于控制对相关存储页面的访问。
- freeNext :是指向生成自由列表的下一个描述符的指针。
- states :可以保存相关存储页面的多个状态和变量,如 refcount 和 usage_count。
descriptor states
- Empty:当相应的缓冲池槽没有存储页面时(即 refcount 和 usage_count 为 0),该描述符的状态为空。
- Pinned:当相应的缓冲池槽存储了一个页面,且有任何 PostgreSQL 进程正在访问该页面(即 refcount 和 usage_count 大于或等于 1)时,该缓冲区描述符的状态就会被钉住。
- Unpinned:当相应的缓冲池插槽存储了一个页面,但没有 PostgreSQL 进程访问该页面(即 usage_count 大于或等于 1,但 refcount 为 0)时,该缓冲区描述符的状态为Unpinned。
Buffer Descriptors Layer
Buffer Descriptors集合构成一个数组,在本文档中称为Buffer Descriptors Layer。
服务器启动时,所有缓冲区描述符的状态都是空的。在 PostgreSQL 中,这些描述符由一个称为 freelist 的链表组成
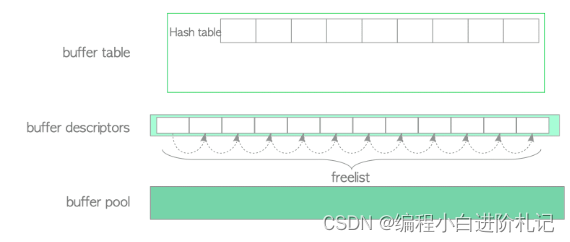
加载第一页步骤:
(1) 从自由列表顶端读取一个空描述符,并将其固定(即将其 refcount 和 usage_count 增加 1)。
(2) 在缓冲区表中插入一个新条目,将第一页的标签映射到检索到的描述符的缓冲区 ID。
(3) 将新页面从存储器加载到相应的缓冲池插槽中。
(4) 将新页面的元数据保存到检索到的描述符中。
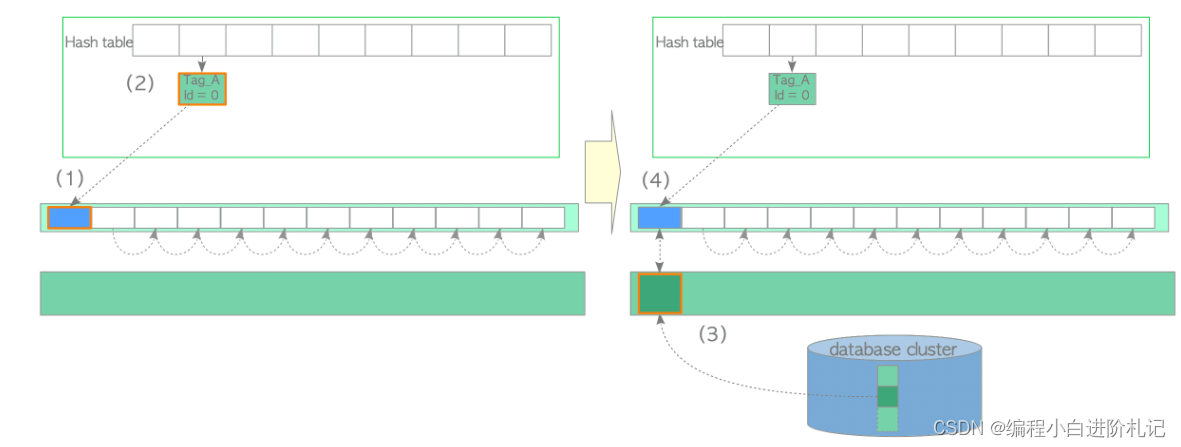
从freelist中获取的描述符始终保留页面的元数据。换句话说,非空描述符一旦被使用,就不会返回freelist。但是,当出现以下情况之一时,相应的描述符会被再次添加到自由列表中,描述符状态也会被设置为 “NULL”:
- 表或索引被删除。
- 数据库被删除。
- 使用 VACUUM FULL 命令清理表或索引。
buffer pool
缓冲池是一个简单数组,用于存储表和索引等数据文件页。缓冲池数组的索引称为 buffer_ids。
缓冲池槽的大小为 8 KB,相当于一个页面的大小。因此,每个槽可以存储整个页面。
Buffer Manager Works
Accessing a Page Stored in the Buffer Pool
- 创建所需页面的缓冲区标签,并使用哈希函数计算包含已创建缓冲区标签相关条目的哈希桶槽。
- 以共享模式获取覆盖所获哈希桶槽的 BufMappingLock 分区(该锁将在步骤 (5) 中释放)。
- 查找标签为 "Tag_C "的条目,并从条目中获取缓冲区 ID。在本例中,缓冲区 ID 为 2
- 将 buffer_id 2 的缓冲区描述符钉住,同时将该描述符的 refcount 和 usage_count 增加 1
- 释放 BufMappingLock。
- 访问缓冲区标识为 2 的缓冲区池插槽。
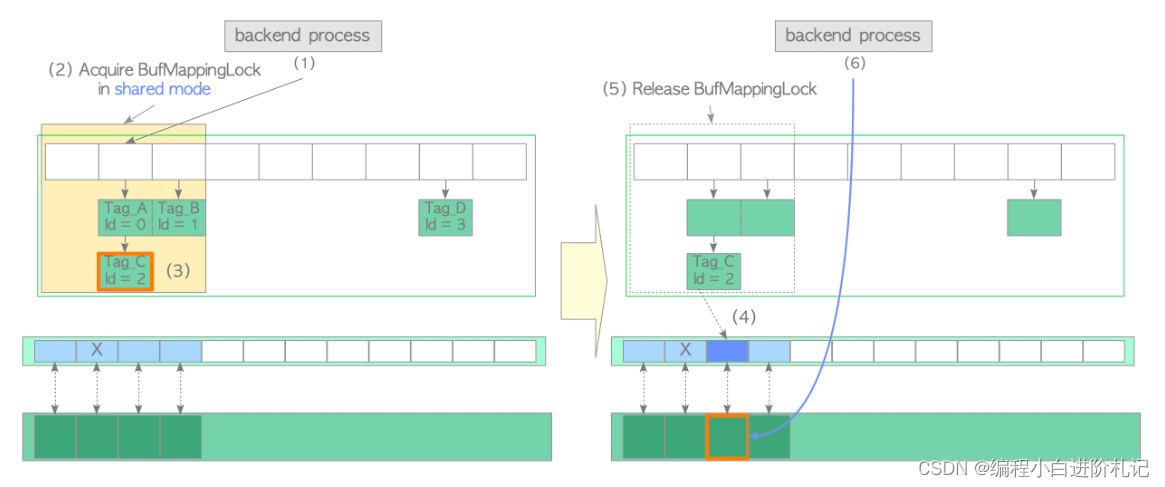
然后,当从缓冲池插槽中的页面读取行时,PostgreSQL 进程会获取相应缓冲区描述符的共享 content_lock。因此,缓冲池插槽可同时被多个进程读取。
当向页面插入(以及更新或删除)记录时,PostgreSQL 进程会获取相应缓冲区描述符的独占内容锁。(注意,页面的 dirty 位必须设置为 “1”)。
访问页面后,相应缓冲区描述符的 refcount 值将减少 1。
Loading a Page from Storage to Empty Slot
将页面从存储器加载到空槽
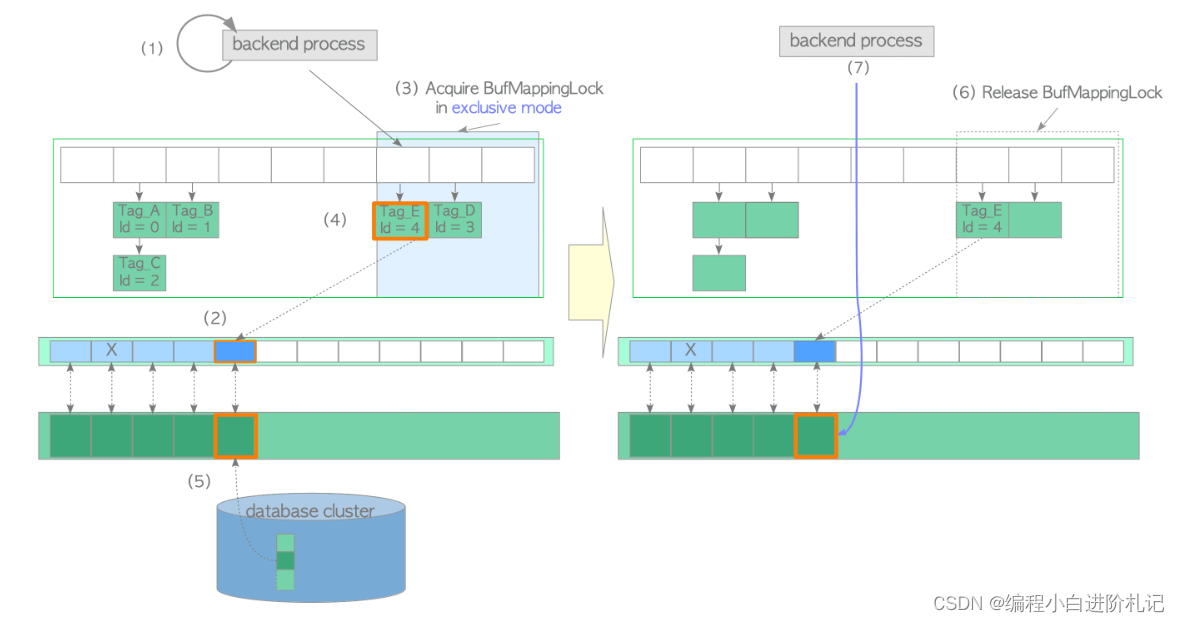
(1) 查找缓冲区表(假设未找到)。
- 创建所需页面的缓冲区标记(本例中缓冲区标记为 “Tag_E”)并计算哈希桶槽。
- 以共享模式获取 BufMappingLock 分区。
- 查找缓冲区表。(根据假设未找到)。
- 释放 BufMappingLock。
(2) 从 freelist 中获取空缓冲区描述符,并将其固定。在本例中,获取的描述符的 buffer_id 为 4。
(3) 以独占模式获取 BufMappingLock 分区。(该锁将在步骤 (6) 中释放)。
(4) 创建一个包含缓冲区标记 "Tag_E "和缓冲区 ID 4 的新数据条目。 将创建的条目插入缓冲区表。
(5) 将所需的页面数据从存储器加载到缓冲区池插槽中,缓冲区标识为 4,具体步骤如下:
- 在 9.5 或更早版本中,获取相应描述符的独占 io_in_progress_lock 2.
- 将相应描述符的 io_in_progress 位设置为 “1”,以防止其他进程访问。
- 将所需的页面数据从存储器加载到缓冲池插槽。
- 更改相应描述符的状态:将 io_in_progress 位设置为 “0”,将有效位设置为 “1”。
- 在 9.5 或更早版本中,释放 io_in_progress_lock 。
(6) 释放 BufMappingLock。
(7) 访问 buffer_id 为 4 的缓冲池插槽。
Loading a Page from Storage to a Victim Buffer Pool Slot
假设所有缓冲池插槽都被页面占用,但所需页面未被存储。缓冲区管理器执行以下步骤:
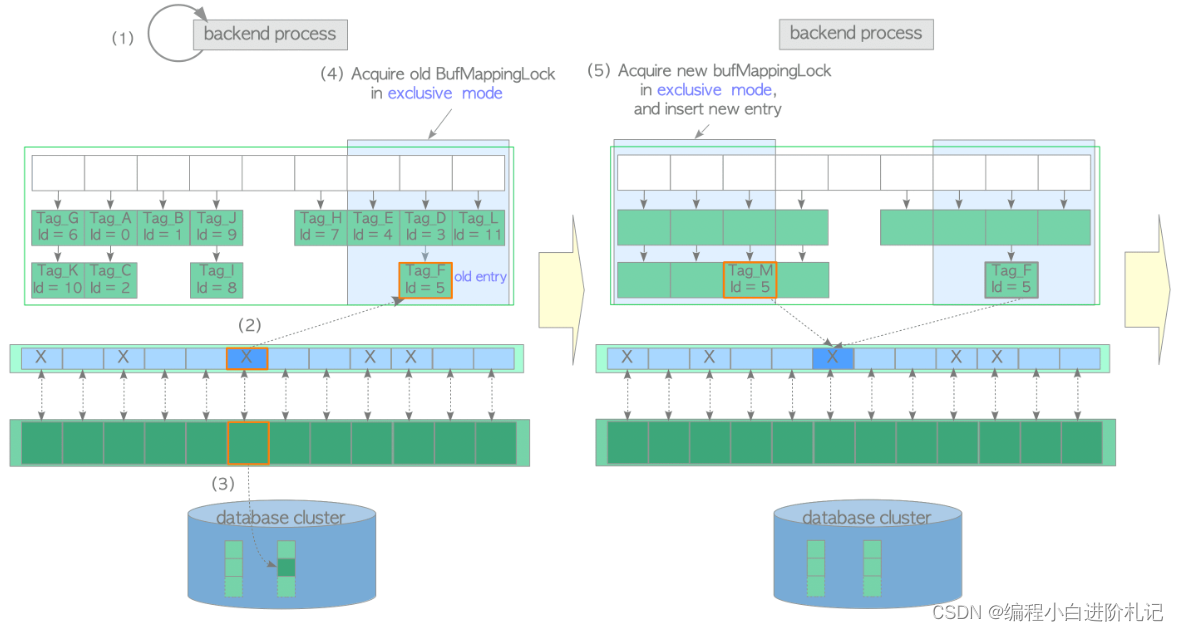
(1)创建所需页面的缓冲区标签,并查找缓冲区表。
(2)使用时钟扫描算法选择一个victim buffer pool slot。从缓冲区表中获取包含victim pool slot buffer_ID 的旧条目,并将victim buffer pool slot固定在缓冲区描述符层中。
(3)如果是脏数据,则清除(写入并同步)受害页数据;否则继续执行步骤 (4)。
在用新数据覆盖之前,必须先将脏页写入存储器。刷新脏页的步骤如下:
- 获取具有 5 的描述符的共享context_lock和独占的 io_in_progress 锁(在步骤 6 中释放)。
- 更改相应描述符的状态;将 io_in_progress 位设置为 “1”,将 just_dirtied 位设置为 “0”。
- 根据情况调用 XLogFlush() 函数,将 WAL 缓冲区中的 WAL 数据写入当前的 WAL 段文件。
- 将victim页面数据刷新到存储中。
- 更改相应描述符的状态;将 io_in_progress 位设置为 “0”,将 valid 位设置为 “1”。
- 释放 io_in_progress 和 content_lock 锁。
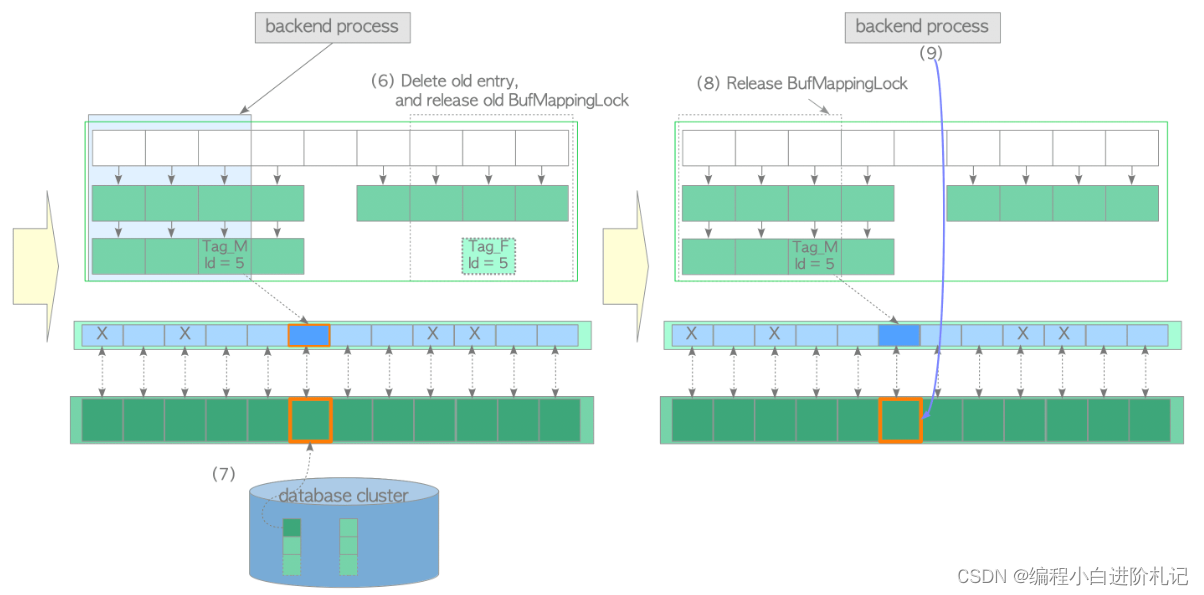
(4)以独占模式获取包含旧条目插槽的旧 BufMappingLock 分区。
(5)获取新的 BufMappingLock 分区,并在缓冲区表中插入新条目
- 创建由新缓冲区标签 "Tag_M "和victim buffer_ID 组成的新条目。
- 获取新的 BufMappingLock 分区,该分区以独占模式覆盖了包含新条目的插槽。
- 将新条目插入缓冲区表。
(6) 从缓冲区表中删除旧条目,并释放旧的 BufMappingLock 分区。
(7) 将所需的页面数据从存储器加载到受害者缓冲区插槽。然后,更新带有 buffer_id 5 的描述符的标志;将 dirty 位设置为 0,并初始化其他位。
(8) 释放新的 BufMappingLock 分区。
(9) 访问带有 buffer_id 5 的缓冲池槽。
Page Replacement Algorithm: Clock Sweep
将缓冲区描述符想象成一个循环列表。nextVictimBuffer 是一个无符号 32 位整数,始终指向其中一个缓冲区描述符,并顺时针旋转。算法的伪代码和说明如下:
WHILE true
(1) Obtain the candidate buffer descriptor pointed by the nextVictimBuffer
(2) IF the candidate descriptor is unpinned THEN
(3) IF the candidate descriptor's usage_count == 0 THEN
BREAK WHILE LOOP /* the corresponding slot of this descriptor is victim slot. */
ELSE
Decrease the candidate descriptpor's usage_count by 1
END IF
END IF
(4) Advance nextVictimBuffer to the next one
END WHILE
(5) RETURN buffer_id of the victim
(1) 获取 nextVictimBuffer 指向的候选缓冲区描述符。
(2) 如果候选缓冲区描述符未锁定,则执行步骤 (3)。否则,进入步骤 (4)。
(3) 如果候选描述符的使用次数为 0,则选择该描述符的相应槽作为victim,并继续执行步骤 (5)。否则,将该描述符的使用次数减 1,并继续执行步骤 (4)。
(4) 将 nextVictimBuffer 提前到下一个描述符(如果在末尾,则绕一圈),然后返回步骤 (1)。重复上述步骤,直到找到victim。
(5) 返回victim的buffer_ID。
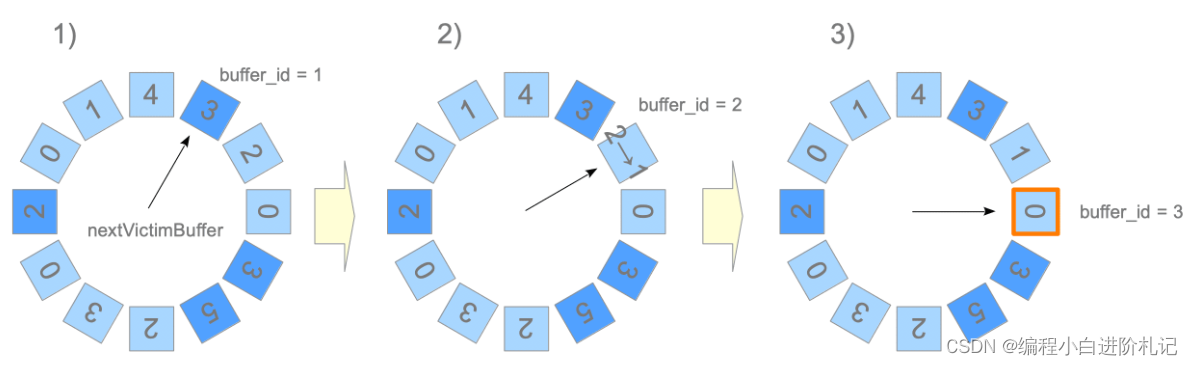
- nextVictimBuffer 指向第一个描述符(buffer_id 1)。但是,由于该描述符已被钉住,因此会被跳过。
- nextVictimBuffer 指向第二个描述符(buffer_id 2)。因此,使用次数减少 1,nextVictimBuffer 进入第三个候选对象。
- nextVictimBuffer 指向第三个描述符(buffer_id 3)。因此,它是本轮的victim。
每当 nextVictimBuffer 扫描一个未固定的描述符时,其 usage_count 就会减少 1。 因此,如果缓冲池中存在未固定的描述符,该算法总能通过旋转 nextVictimBuffer 找到一个 usage_count 为 0 的受害者。







