
目录
一、环境说明
系统环境描述:本教程基于CentOS 8.0版本虚拟机
Hadoop集群:
| 节点 | NN | NN | JN | ZKFC | ZK | DN | RM | NM | IP |
| master | * | * | * | 192.168.31.215 | |||||
| node1 | * | * | * | * | 192.168.31.8 | ||||
| node2 | * | * | 192.168.31.9 | ||||||
| node3 | * | * | * | * | * | 192.168.31.167 | |||
| node4 | * | * | * | * | 192.168.31.154 |
Hbase 集群规划:
| 节点 | HMaster | HRegionServer | ZK | IP |
| master | * | 192.168.31.215 | ||
| node1 | * | 192.168.31.8 | ||
| node2 | * | * | 192.168.31.9 | |
| node3 | * | * | 192.168.31.167 | |
| node4 | * | * | 192.168.31.154 |
软件版本:
| 软件 | 版本 |
| jdk | 1.8.0_211 |
| zookeeper | 3.8.2 |
| Hbase | 2.5.5 |
| Hdoop | 3.3.4 |
提示:Hbase 是基于Hadoop的,在开始Hbase之前,需要确保你的Hadoop集群是可用的。同时,本次部署需要的zookeeper,我使用的是Hadoop集群中的,关于zookeeper的部署,这里不做描述。因为该文章是基于部署Hadoop之后,所以一些机器的基本配置这里不做描述,比如机器的免密登录,机器的hosts文件设置,包括基本的JDK安装等,如果对于这些部分有操作上的疑问,欢迎查看之前Hadoop的系列文章。具体可参考:一篇文章带你学会Hadoop-3.3.4集群部署_夜夜流光相皎洁_小宁的博客-CSDN博客
二、部署Hbase
2.1 解压Hbase
tar -zxvf hbase-2.5.5-bin.tar.gz2.2 移动解压包
mv hbase-2.5.5 /usr/local/2.3 修改 hbase-env.sh文件
cd /usr/local/hbase-2.5.5/conf
vim hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_2112.4 修改环境变量
vim /etcprofile
export HBASE_HOME=/usr/local/hbase-2.5.5
export PATH=$PATH:$HBASE_HOME/bin2.5 修改hbase-site.xml文件
vim hbase-site.xml
<!-- hbase是否部署为集群模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--zookeeper 集群ip -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<!--zookeeper data dir -->
<property>
<name>hbase.zoopkeeper.property.dataDir</name>
<value>/usr/local/hbase-2.5.5/data/zookeeper</value>
</property>
<!--要把hbase的数据存储hdfs上的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--hbase 数据目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase-2.5.5/data/hbase/tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- Flink Secondary Index -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.column.max.version</name>
<value>2</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.2</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.8</value>
</property>
<!-- 实际的Block Size = Heap size * hfile.block.cache.size, 需要重启才能生效,HDFS读较多时,可以增加zhe -->
<property>
<name>hfile.block.cache.size</name>
<value>0.2</value>
</property>
<!--bytes,每个用户写缓存数,默认2097152; 总消耗内存=hbase.client.write.buffer * hbase.regionserver.handler.count -->
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<!--RPC handler,default 30-->
<property>
<name>dfs.namenode.service.handler.count</name>
<value>48</value>
</property>
<!-- Phoenix error-->
<property>
<name>phoenix.coprocessor.maxServerCacheTimeToLiveMs</name>
<value>300000</value>
</property>
<!-- Region Split Policy -->
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy</value>
</property>
<!-- Compacting 604800000 -->
<property>
<name>hbase.hstore.compactionthreshold</name>
<value>5</value>
</property>
<property>
<name>hbase.hstore.compaction.max</name>
<value>10</value>
</property>
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>16</value>
</property>
<property>
<name>hbase.hregion.majorcompaction</name>
<value>0</value>
</property>
<property>
<name>hbase.hstore.compaction.throughput.higher.bound</name>
<value>20971520</value>
<description>The default is 20 MB/sec</description>
</property>
<property>
<name>hbase.hstore.compaction.throughput.lower.bound</name>
<value>10485760</value>
<description>The default is 10 MB/sec</description>
</property>2.6 修改regionservers 文件
配置你希望启动HRegionserver服务的节点
vim regionservers
node1
node3
node42.7 分发hbase
2.7.1 分发hbase包
scp -r /usr/local/hbase-2.5.5/ root@node1:/usr/local/
scp -r /usr/local/hbase-2.5.5/ root@node2:/usr/local/
scp -r /usr/local/hbase-2.5.5/ root@node3:/usr/local/
scp -r /usr/local/hbase-2.5.5/ root@node4:/usr/local/2.7.2 分发环境配置
scp /etc/profile root@node1:/etc/profile
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
scp /etc/profile root@node4:/etc/profile提示:注意执行source /etc/profile 使环境生效
2.8 启动hbase服务
2.8.1 环境生效
执行source /etc/profile 使环境生效(所有节点)
source /etc/profile2.8.2 master节点执行
start-hbase.sh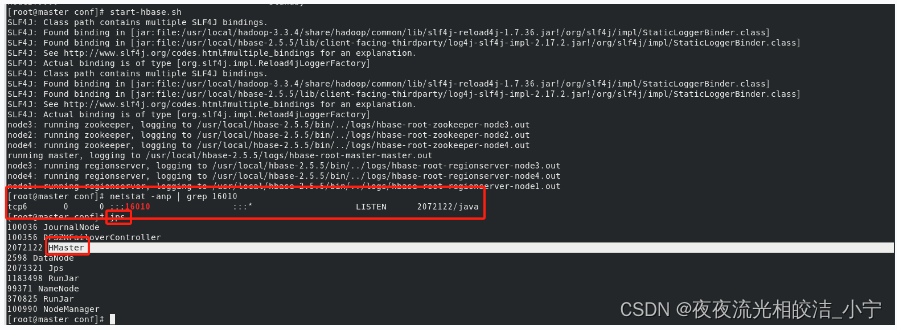
可以通过netstat -anp | grep 16010 探测端口是否被启用,通过jps 查看master 是否有HMaster 服务启动,有则证明启动成功
注意:启动服务之前,需要先启动zookeeper
2.8.3 node2节点执行
hbase-daemon.sh start master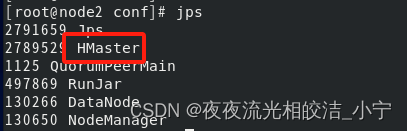
通过jps 指令查看node2节点,是否有HMaster服务启动,有则证明启动成功。
注意:启动服务之前,需要先启动zookeeper
2.8.4 访问
浏览器访问服务:

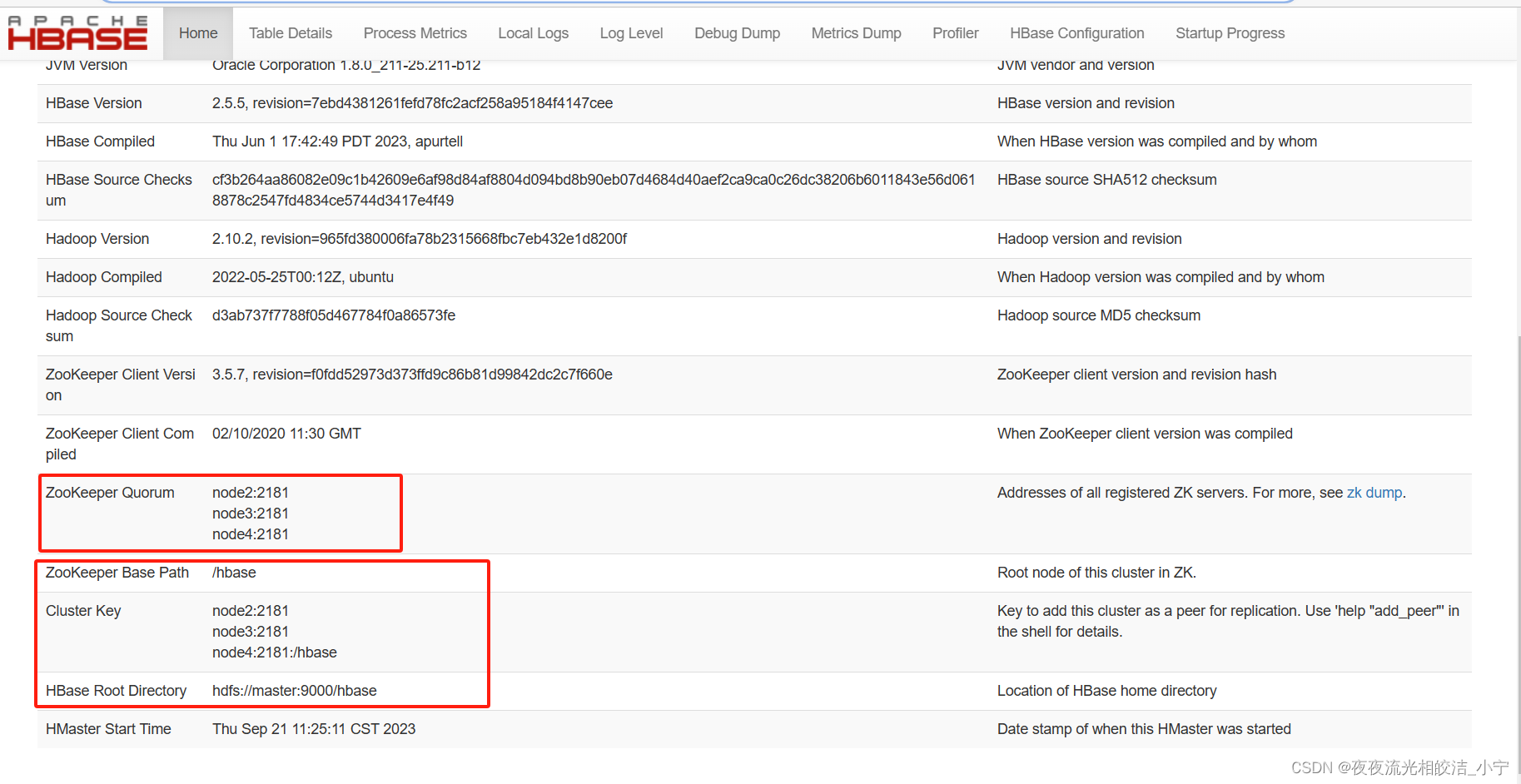
能成功访问到HBase的页面,查看信息和我们配置的没有出入,符合预期,说明本次HBase集群服务部署成功了。
好了,今天HBase分布式集群部署的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!







