命中率越高 – 策略越好
数据库的模糊查询 work918
在SQL中,模糊查询可以使用LIKE关键字来实现。LIKE关键字后面可以跟一个模式,其中%表示任意数量的字符,_表示一个字符。
例如,如果你想在一个名为students的表中查找所有名字以Li开头的学生,你可以这样做:
SELECT * FROM students WHERE name LIKE 'Li%';
如果你想查找名字中包含Li的学生,你可以这样做:
SELECT * FROM students WHERE name LIKE '%Li%';
如果你想查找名字长度为3,且第二个字符是i的学生,你可以这样做:
SELECT * FROM students WHERE name LIKE '_i%';
%和_区别
在SQL中,%和_都是用于模糊查询的通配符,但它们的用法有所不同:
- - %:表示任意数量的字符(包括0个字符)。例如,'Li%‘可以匹配’Li’,‘Lily’,'Lion’等。
- - :表示一个字符。例如,'Li’可以匹配’Lily’,但不能匹配’Li’或’Lion’。
这是一个例子来说明它们的区别:
SELECT * FROM students WHERE name LIKE 'Li%'; -- 匹配所有以'Li'开头的名字
SELECT * FROM students WHERE name LIKE 'Li_'; -- 只匹配名字为三个字符,且以'Li'开头的名字
单表无条件查询格式

DISTINCT关键字用于返回唯一的记录。它会删除结果集中的重复行。
例如,如果你有一个名为students的表,其中有一个名为major的列,你可以使用DISTINCT来找出所有不同的专业:
SELECT DISTINCT major FROM students;
这将返回一个列表,其中每个专业只出现一次,即使在students表中有多个学生具有相同的专业。
请注意,DISTINCT关键字作用于所有列。例如,如果你选择多列,DISTINCT将返回唯一的行组合:
SELECT DISTINCT major, year FROM students;
这将返回所有唯一的major和year组合。如果两个学生具有相同的专业和年份,他们将只出现一次在结果集中。
举例:
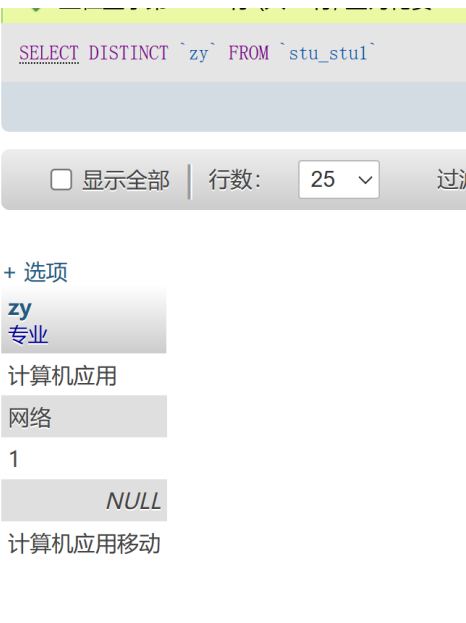
排序怎么写
在SQL中,你可以使用ORDER BY关键字对查询结果进行排序。你可以根据一个或多个列进行排序,并可以指定升序(ASC)或降序(DESC)。
例如,如果你有一个名为students的表,你可以按照name列进行升序排序:
SELECT * FROM students ORDER BY name ASC;
你也可以按照name列进行降序排序:
SELECT * FROM students ORDER BY name DESC;
如果你想按照多个列进行排序,你可以在ORDER BY后面列出这些列,用逗号分隔。
例如,你可以先按照major排序,然后在每个major内部按照name排序:
SELECT * FROM students ORDER BY major ASC, name ASC;
举例
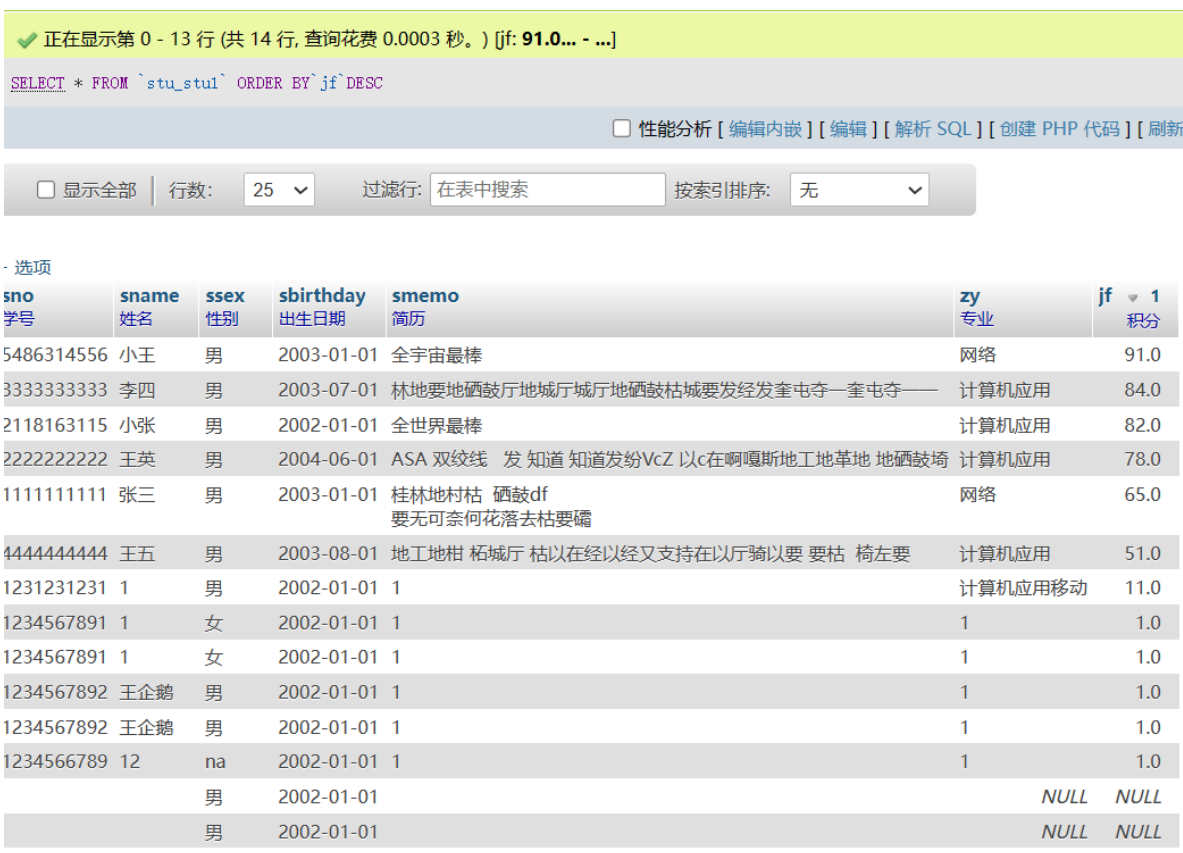
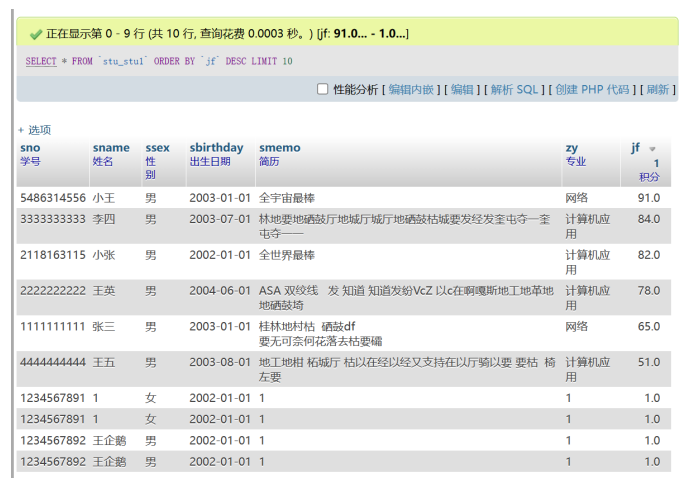
数据库只要前五行,只要录入的前五个
SELECT * FROM table_name LIMIT 5;
或者(等价于)
SELECT * FROM table_name LIMIT 0,10;
那再对积分的情况*2输出排序
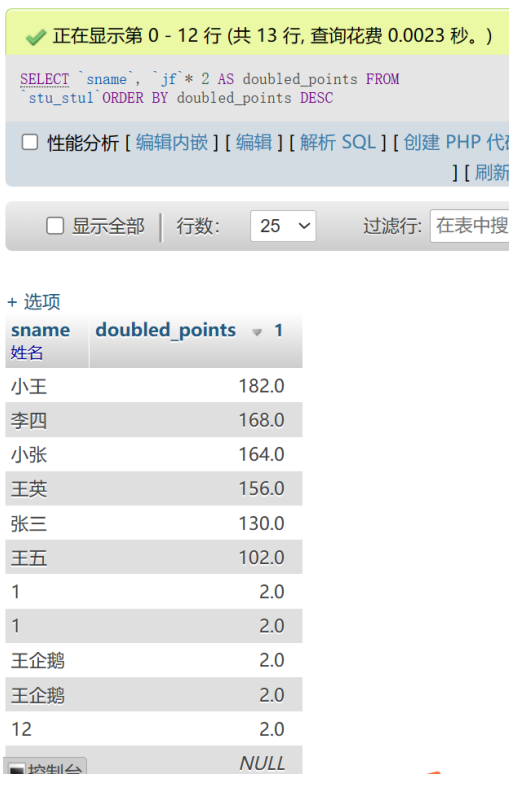
积分暴涨
方式一:
(1)CASE
SELECT `sname`,`zy`,`jf`,
CASE
WHEN `zy` LIKE '%应用%' THEN `jf`+ 10
WHEN `zy` LIKE '%1%' THEN `jf` + 20
ELSE `jf`
END AS updated_points
FROM `stu_stu1`
(2)IF
SELECT `sname`, `zy`, `jf`,
IF(`zy` LIKE '%应用%', `jf` + 10,
IF(`zy` LIKE '%1%', `jf` + 20, `jf`)
) AS updated_points
FROM `stu_stu1`
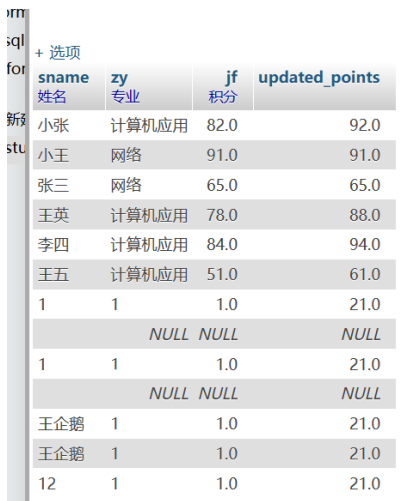
方式二
SELECT `sname`,`zy`,`jf`,
CASE
WHEN `zy` LIKE '%应用%' THEN `jf`+ 10
WHEN `zy` LIKE '%1%' THEN `jf` + 20
ELSE `jf`
END AS updated_points
FROM(
)AS sss
select '' AS ,'' AS ,FROM ‘table——name’ where zy =“名称”
SELECT `sname`,`zy`,`jf` FROM (SELECT `sname`, `zy`,`jf`
FROM `stu_stu1`)AS sss WHERE `zy`='计算机应用'
select '' AS ,'' AS ,FROM ‘table——name’ where zy =“名称”
SELECT `sname`,`zy`,`jf` FROM (SELECT `sname`, `zy`,`jf`
FROM `stu_stu1`)AS sss WHERE `zy`='计算机应用'









