
前言:Hello大家好,我是小哥谈。RepVGG 重参数化模块是一种用于深度卷积神经网络的模块化设计方法,旨在通过将卷积层和全连接层统一为卷积层来简化网络结构并提高计算效率。该方法通过重参数化,将常规的卷积层分解为一个轻量级的卷积层和一个恒等映射层,从而达到降低计算复杂度的目的。本节课就简单介绍一下如何在YOLOv5中引入RepVGG 重参数化模块!🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
YOLOv5算法改进(10)— 替换主干网络之GhostNet
YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2
YOLOv5算法改进(12)— 替换主干网络之Swin Transformer
YOLOv5算法改进(13)— 替换主干网络之PP-LCNet
YOLOv5算法改进(17)— 更换损失函数(EIoU、AlphaIoU、SIoU和WIoU)
YOLOv5算法改进(18)— 更换激活函数(SiLU、ReLU、ELU、Hardswish、Mish、Softplus等)
YOLOv5算法改进(19)— 更换NMS(DIoU-NMS、CIoU-NMS、EIoU-NMS、GIoU-NMS 、SIoU-NMS和Soft-NMS)
目录
💥💥步骤1:在common.py中添加RepVGG 重参数化模块

🚀1.RepVGG 重参数化模块介绍
RepVGG 重参数化模块是一种用于深度卷积神经网络的模块化设计方法,旨在通过将卷积层和全连接层统一为卷积层来简化网络结构并提高计算效率。该方法通过重参数化,将常规的卷积层分解为一个轻量级的卷积层和一个恒等映射层,从而达到降低计算复杂度的目的。
在RepVGG中,每个重参数化模块由两个部分组成:卷积层和恒等映射层。卷积层用于学习输入特征的高级表示,而恒等映射层则保留了输入特征的原始信息。通过将这两个部分连接在一起,可以实现卷积层和全连接层的统一,并且只需要进行一次卷积操作即可得到输出。
重参数化模块的主要优势是减少了网络中的参数数量和计算复杂度,从而提高了模型的训练速度和推断速度,并且不会显著影响模型的性能。此外,由于模块化设计的特性,RepVGG还具有较好的可解释性和可扩展性。

论文题目:《RepVGG: Making VGG-style ConvNets Great Again》
🚀2.RepVGG 模型架构及优点
💥💥2.1 RepVGG 模型架构
网络重参数化可以认为是模型压缩领域的一种新技术,它的主要思想是把一个K x K的卷积层等价转换为若干种特定网络层的并联或串联,转换后的网络更复杂、参数更多,因此转换的网络在训练阶段有希望达到更好的效果,在推理阶段,又可以把大网络的参数等价转换到原来的K x K卷积层中,使得网络兼具了训练阶段大网络的更好的学习能力和推理阶段小网络的更高的计算速度。
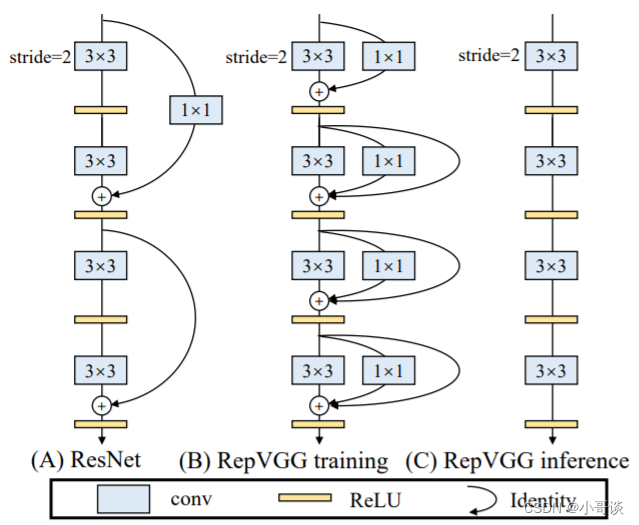
RepVGG沿用ResNet的残差边,只不过RepVGG在每一层都使用了残差连接,3x3卷积接上一个identity和1x1的卷积。如下图所示,图中B代表在训练时所使用的模型结构,图中C代表推理时所用的模型结构,在训练模型当中,在每一分支输出前加一个BN层,如何将B->C就是重参数化的重要体现。✅
💥💥2.2 RepVGG 优点
🍀(1)Fast,使用重参数化后,在推理上速度会有非常大的提升,并且有助于模型部署提高实用性。
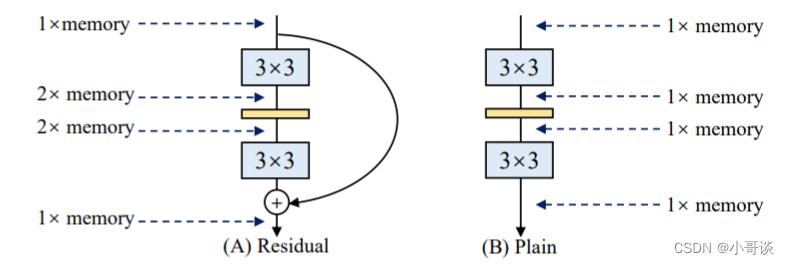
🍀(2)节省内存,采用多分支模型,在每次计算都需要多份内存分别保存每条分支的结果,所以导致内存消耗大。
🍀(3)修改模型会更加方便,使用多分支存在一个问题,就是每条分支的输入通道和输出通道要保持一致,那么对模型的修改产生不便,如果是单路径就不存在这个问题。
💥💥2.3 实验对比
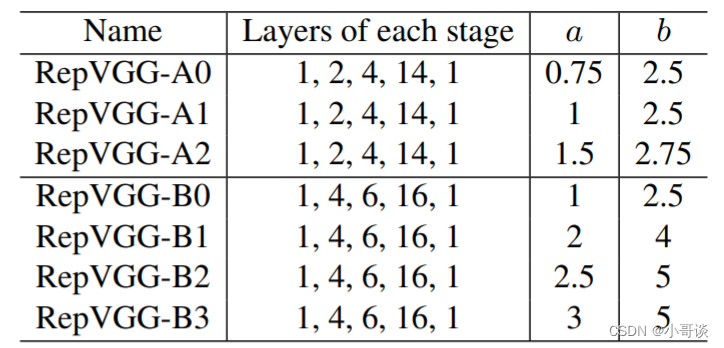
在论文中,作者提出7个模型和主流模型在Imagenet上进行对比,对比试验结果如下:
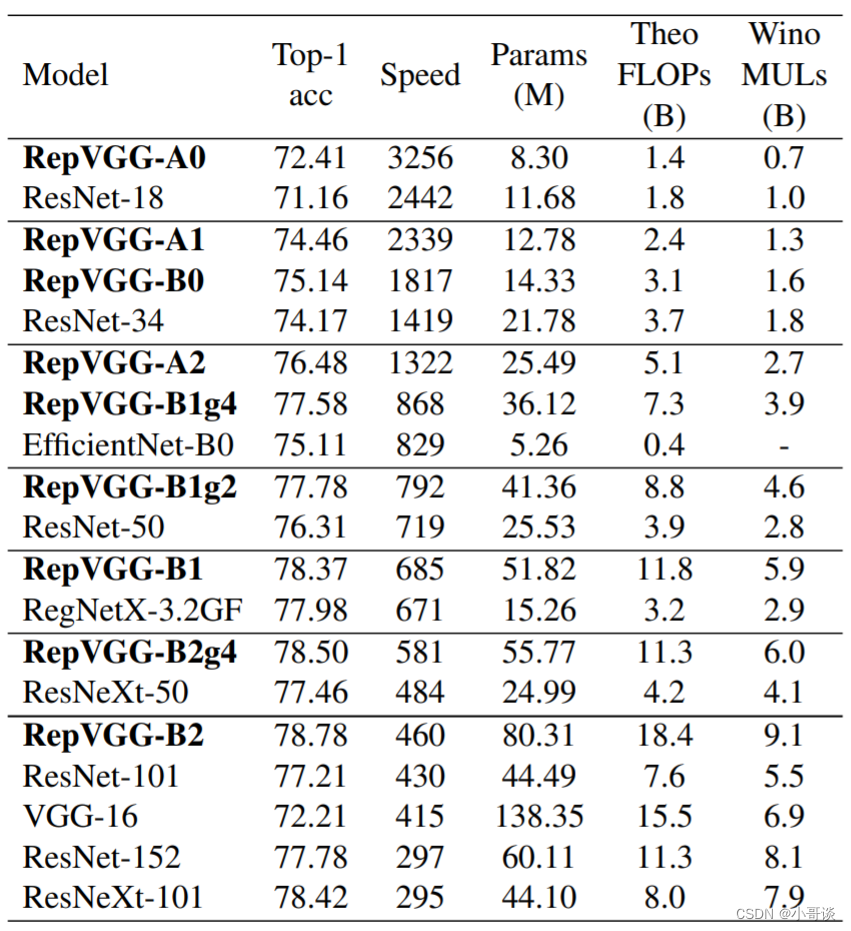
从实验可以看出,RepVGG的推理速度是比较快的,虽然参数比ResNet大,但是使用重参数化替换成推理模型,说明这个工作是非常有效果的。
总之,RepVGG当中的结构重参数化这个方法值得我们去学习,对模型的部署非常友好,在未来的发展中,重参数化会越来越受欢迎(YOLOv6使用了这个方式)。🐳
🚀3.YOLOv5结合RepVGG 重参数化模块
💥💥步骤1:在common.py中添加RepVGG 重参数化模块
将下面RepVGG 重参数化模块的代码复制粘贴到common.py文件的末尾。
# build repvgg block
# -----------------------------
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class SEBlock(nn.Module):
def __init__(self, input_channels, internal_neurons):
super(SEBlock, self).__init__()
self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1,
bias=True)
self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1,
bias=True)
self.input_channels = input_channels
def forward(self, inputs):
x = F.avg_pool2d(inputs, kernel_size=inputs.size(3))
x = self.down(x)
x = F.relu(x)
x = self.up(x)
x = torch.sigmoid(x)
x = x.view(-1, self.input_channels, 1, 1)
return inputs * x
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.SiLU()
# self.nonlinearity = nn.ReLU()
if use_se:
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def fusevggforward(self, x):
return self.nonlinearity(self.rbr_dense(x))
# repvgg block end
# -----------------------------
此时出现报错❌,具体如下图所示:

解决方法:
需要导入包
import torch.nn.functional as F导入后,则报错消失。✅
💥💥步骤2:修改yolo.py文件
修改yolo.py文件,在yolo.py文件中找到 def fuse(self): ,用如下代码替换:
# --------------------------repvgg refuse---------------------------------
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is RepVGGBlock:
if hasattr(m, 'rbr_1x1'):
kernel, bias = m.get_equivalent_kernel_bias()
rbr_reparam = nn.Conv2d(in_channels=m.rbr_dense.conv.in_channels,
out_channels=m.rbr_dense.conv.out_channels,
kernel_size=m.rbr_dense.conv.kernel_size,
stride=m.rbr_dense.conv.stride,
padding=m.rbr_dense.conv.padding, dilation=m.rbr_dense.conv.dilation,
groups=m.rbr_dense.conv.groups, bias=True)
rbr_reparam.weight.data = kernel
rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
m.rbr_dense = rbr_reparam
m.__delattr__('rbr_1x1')
if hasattr(m, 'rbr_identity'):
m.__delattr__('rbr_identity')
if hasattr(m, 'id_tensor'):
m.__delattr__('id_tensor')
m.deploy = True
delattr(m, 'se')
m.forward = m.fusevggforward # update forward
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
# --------------------------end repvgg & shuffle refuse--------------------------------
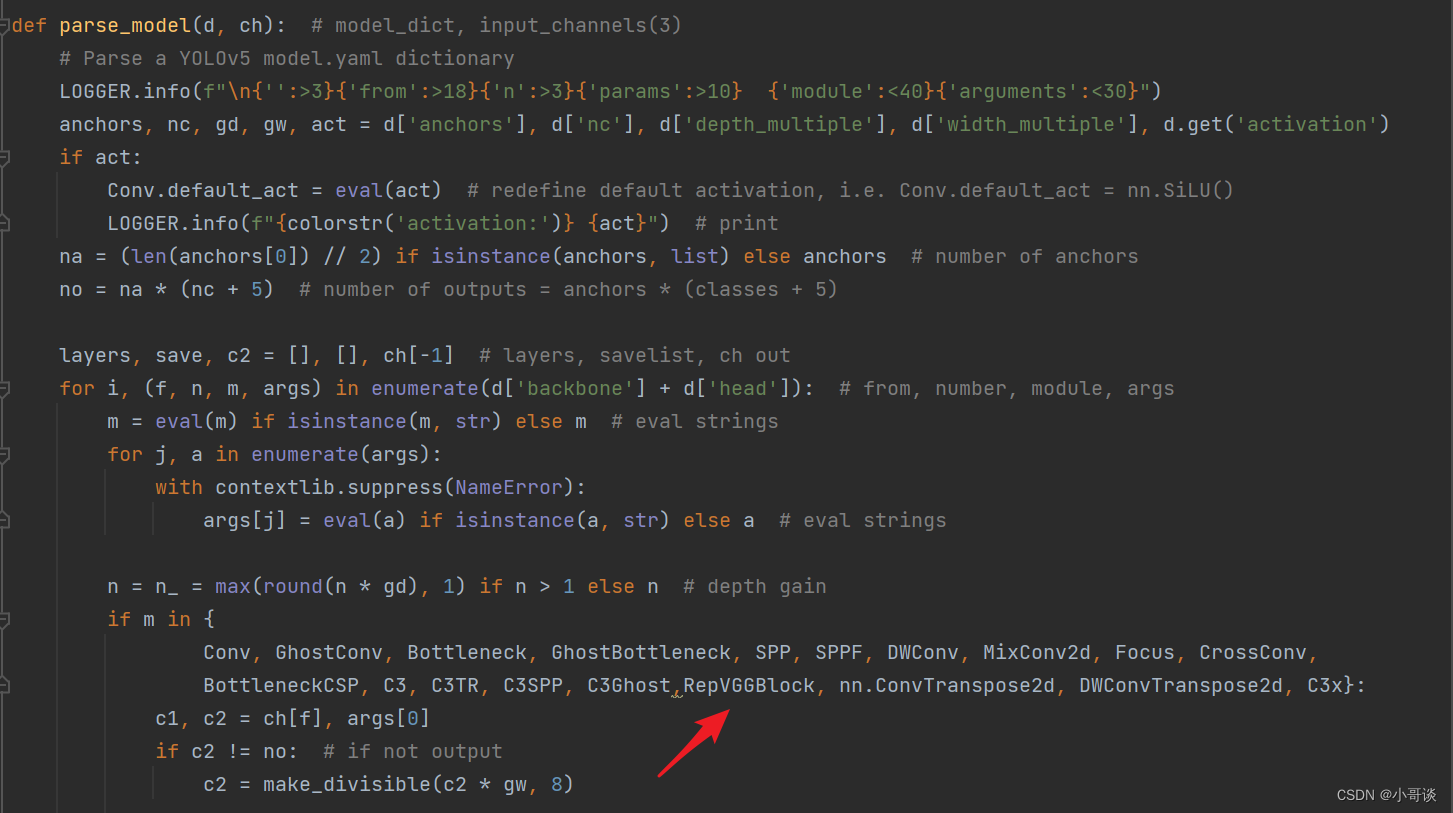
💥💥步骤3:添加RepVGGBlock
在yolo.py文件中,找到parse_model函数,将RepVGGBlock添加到如下位置:
💥💥步骤4:创建自定义的yaml文件
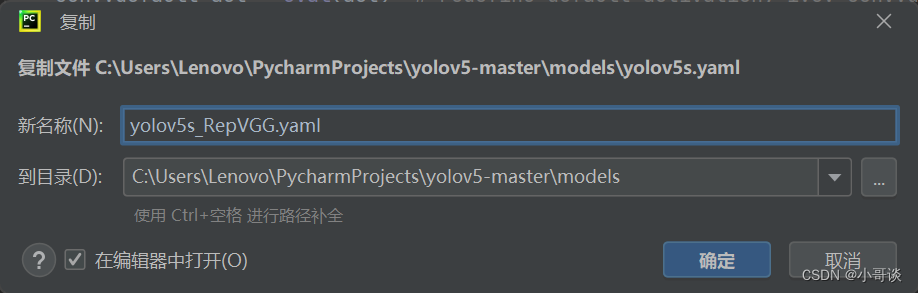
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_RepVGG.yaml。
yaml文件完整代码如下:
# create by pogg
# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5-repvgg backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [32, 3]], # 0-P1/2
[-1, 1, RepVGGBlock, [64, 3, 2]], # 1-P2/4
[-1, 1, C3, [64]],
[-1, 1, RepVGGBlock, [128, 3, 2]], # 3-P3/8
[-1, 3, C3, [128]],
[-1, 1, RepVGGBlock, [256, 3, 2]], # 5-P4/16
[-1, 3, C3, [256]],
[-1, 1, RepVGGBlock, [512, 3, 2]], # 7-P4/16
[-1, 1, SPP, [512, [5, 9, 13]]],
[-1, 1, C3, [512, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [128, False]], # 13
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [128, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [128, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [128, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
💥💥步骤5:验证是否加入成功
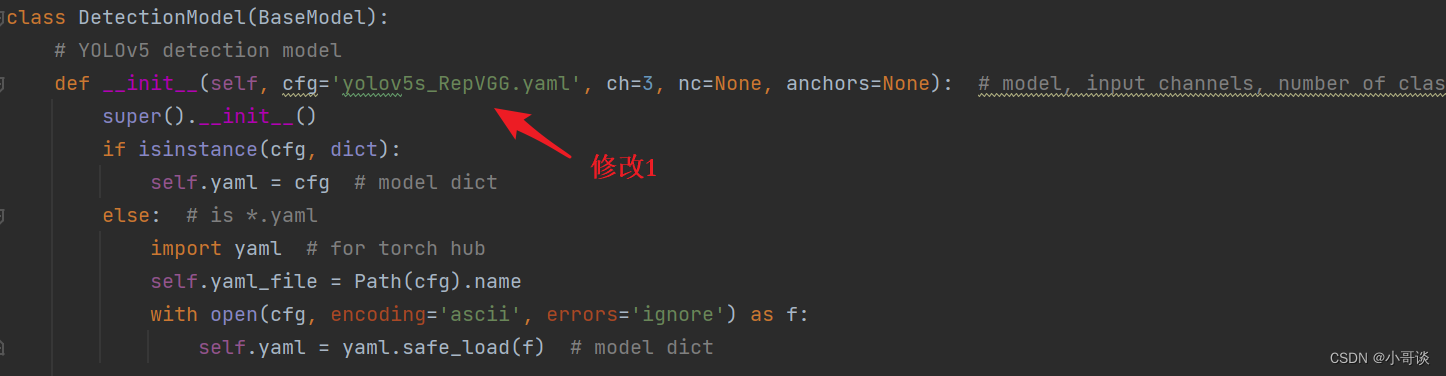
在yolo.py文件里,配置我们刚才自定义的yolov5s_RepVGG.yaml。
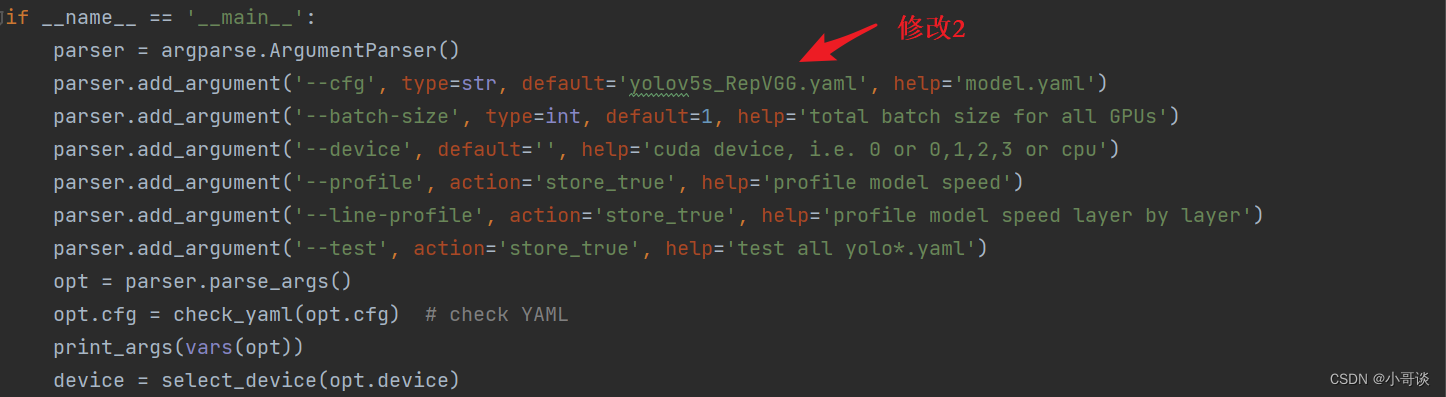
然后运行yolo.py,得到结果。
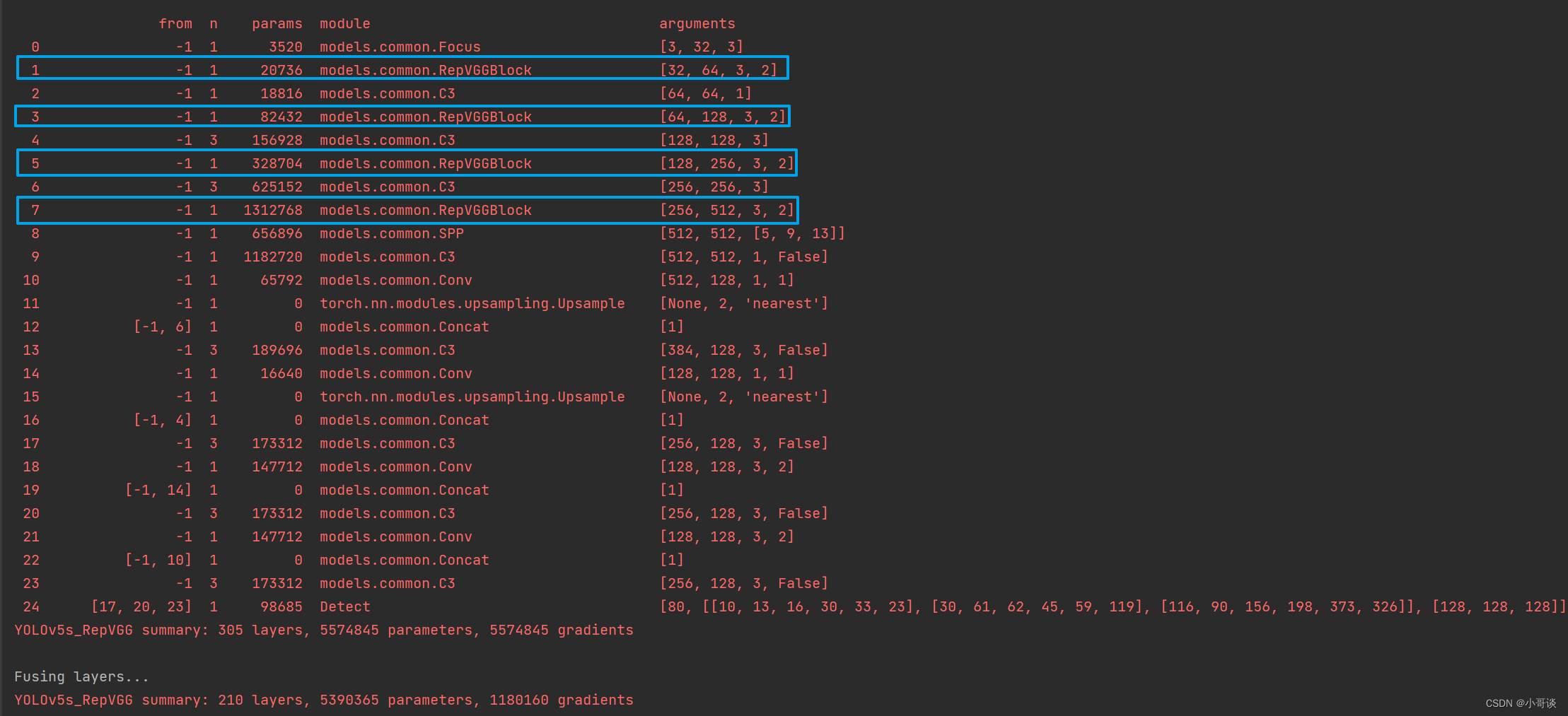
这样就算添加成功了!~🎉🎉🎉










