地址:飞桨AI Studio星河社区-人工智能学习与实训社区
课程地址:飞桨AI Studio星河社区-人工智能学习与实训社区
课程地址:飞桨AI Studio星河社区-人工智能学习与实训社区
课程地址:飞桨AI Studio星河社区-人工智能学习与实训社区
AI Studio的Notebook项目的基本操作
- 项目启停
- 执行和调试
- 多文件代码编辑
- 上传Notebook
- Notebook快捷键
- 暗黑模式
- 字号调节
- Notebook中使用Shell命令
使用pip来安装自己需要的package (但不支持apt-get)
查看当前环境中安装的package
持久化安装
使用git命令来同步代码 (暂时需要Paddle 1.4.1以上)
文件下载
- Python代码执行与调试
- 变量监控
- Magic命令
%env:设置环境变量
%run: 运行python代码
%%writefile and %pycat: 导出cell内容/显示外部脚本的内容
- 关于快速查看某个对象/方法/接口的用法
- 关于变量监控
- 关于调试代码
项目启停
当进入自己项目的详情页面时, 用户可以选择"运行"项目, 也就是准备项目环境.
同样的, 当不想继续时, 可以此页面点击"停止"以终止项目.

执行和调试

插入断点则需要使用Python自带Debugger: PDB.
Python自带一个调试器, 在Python 3.7之后甚至成为内置调试器. 这就是PDB. 这是使用Python的用户需要掌握的基本技能.
对应代码如下:
import pdb class MyScrapy: urls = [] def start_url(self, urls): pdb.set_trace() for url in urls: print(url) self.urls.append(url) def parse(self): pdb.set_trace() for url in self.urls: result = self.request_something(url) def request_something(self, url): print('requesting...') data = '''<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> </body> </html>''' return data scrapy= MyScrapy() scrapy.start_url(["http://www.zone7.cn", "http://www.zone7.cn", "http://www.zone7.cn", "http://www.zone7.cn", ]) scrapy.parse()详细使用说明的主要内容参考 howchoo
多文件代码编辑
- 支持多文件编辑
- 可使用命令
!cat <<newfile > newfile.py在项目空间内直接创建文件,之后双击进行编辑。
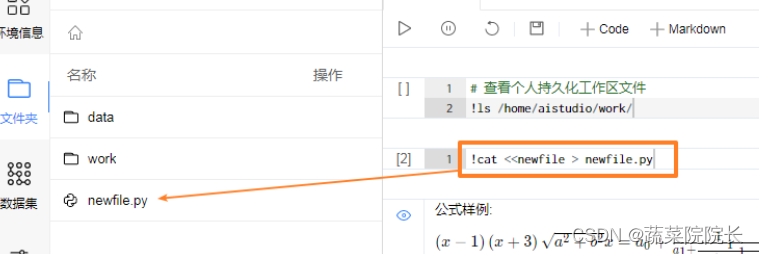
上传Notebook

Notebook快键键
快键键分为两种状态下:1.命令模式;2.编辑模式

暗黑模式

字号调节
Notebook中使用Shell命令
通过在Shell命令前添加! (感叹号), 就可以执行部分Shell命令. 包括诸如 !pip install这样的命令. 不过, !apt-get这种可能引发用户进一步操作的命令是不支持的.

使用pip来安装自己需要的package(但不支持apt-get)
! pip install package名
#查看当前环境中安装的package
!pip list --format=columns
#查看预装软件
!apt list持久化安装
需要进行持久化安装就需要使用持久化路径,例:
!mkdir /home/aistudio/external-libraries
!pip install beautifulsoup4 -t /home/aistudio/external-libraries同时添加如下代码,这样每次环境(kernel)启动时只要运行下方代码即可:
import sys
sys.path.append('/home/aistudio/external-libraries')使用git命令来同步代码 (暂时需要Paddle 1.4.1以上)
%env:设置环境变量
%run: 运行python代码

%%writefile and %pycat: 导出cell内容/显示外部脚本的内容
%%writefile magic可以把cell的内容保存到外部文件里。 而%pycat则可把外部文件展示在Cell中
%%writefile SaveToPythonCode.py
from math import sqrt
for i in range(2,10):
flag=1
k = int(sqrt(i))
for j in range(2,k+1):
if i%j == 0:
flag = 0
break
if(flag):
print(i)
因为没有指定路径, 所以文件被保存到了根目录下. 但至少it works.
然后再来尝试从中读文件内容:
%pycat SaveToPythonCode.py调试器:
import pdb
class MyScrapy:
urls = []
def start_url(self, urls):
pdb.set_trace()
for url in urls:
print(url)
self.urls.append(url)
def parse(self):
pdb.set_trace()
for url in self.urls:
result = self.request_something(url)
def request_something(self, url):
print('requesting...')
data = '''<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
</body>
</html>'''
return data
scrapy= MyScrapy()
scrapy.start_url(["http://www.zone7.cn", "http://www.zone7.cn", "http://www.zone7.cn", "http://www.zone7.cn", ])
scrapy.parse() 运行结果:
Python附带了一个名为pdb的有用模块,它基本上是一个交互式源代码调试器。
一旦开始运行, 会出现交互框
如下图所示:

在这个输入框里敲入命令, 即可开始调试.
通常这些命令都是一个字母, 因此毋庸担心.
- 下一行->n:在输入框里, 输入n, 可转到下一行
- 打印->p
- 动态添加断电->b:在调试会话开始后在程序的特定位置添加断点
- 动态分配变量
- 退出->q:可以在任何时候退出
- ENTER :重复上次命令
- c :继续
- l :查找当前位于哪里
- s :进入子程序,如果当前有一个函数调用,那么 s 会进入被调用的函数体
- n(ext) :让程序运行下一行,如果当前语句有一个函数调用,用 n 是不会进入被调用的函数体中的
- r :运行直到子程序结束)
- !<python 命令>
- h :帮助
- a(rgs) :打印当前函数的参数
- j(ump) :让程序跳转到指定的行数
- l(ist) :可以列出当前将要运行的代码块
- p(rint) :最有用的命令之一,打印某个变量
- q(uit) :退出调试
- r(eturn) :继续执行,直到函数体返回
#如发现环境中未安装, 可以运行下方代码来安装ipdb
!pip install ipdb -i https://pypi.tuna.tsinghua.edu.cn/simple









