
一、说明
GAN是生成对抗网络(Generative Adversarial Network)的缩写,是一种无监督学习算法,由Goodfellow等人于2014年提出。GAN由一个生成器网络和一个判别器网络组成,通过二者之间的对抗来训练生成器网络生成与真实样本相似的假样本。生成器和判别器互相对抗,不断改善自己的性能。GAN广泛应用于图像、语音、自然语言等领域中的生成任务。
二、生成 AI & GAN概述
GAN 是一类机器学习,可以使用用于训练模型的原始数据集生成新示例。这里有两个神经网络:生成器和鉴别器。在这里,代理人以零和博弈的形式相互对抗,一个代理人的胜利是另一个代理人的损失。生成器的目标是创建与真实数据一样逼真的假数据,而鉴别器的目标是从真实数据中识别假数据。两个网络玩猫捉老鼠的游戏,直到生成器创建鉴别器无法与真实数据区分开来的数据
尽管存在许多AI算法,但一种在行业中引起轰动的AI是生成AI。随着 ChatGPT 和 Midjourney 等生成式 AI 工具的日益普及,用户现在可以比以往更快地生成新的想法、内容和解决方案。
2.1 什么是生成人工智能?
生成人工智能是人工智能的一个子领域,利用无监督和半监督机器学习技术。生成式 AI 描述了可用于创建全新内容的算法和模型,包括音频、视频、文本,甚至模拟等。
它具有大量的实际用途,从提高图片分辨率和创建新的商业模式到用于开发医学领域的新药。
与其他形式的 AI 不同,例如经过训练以进行预测或对数据进行分类的预测或分类模型,生成 AI 模型旨在创建类似于原始输入数据的新数据。
2.2 生成人工智能的模型?
生成人工智能的一些突出框架或模型是:
- 1. 生成对抗网络
- 2. 基于变压器的模型
- 3. 变速自动编码器
- 4. 伯特
- 5. 自回归模型
- 4. 伯特
- 3. 变速自动编码器
- 2. 基于变压器的模型
三、生成对抗网络 (GAN)
3.1 了解 GAN的组分
生成对抗网络 (GAN) 是机器学习和深度学习中的一种人工神经网络架构,由生成器和鉴别器两个神经网络组成,它们在竞争过程中一起训练。生成器尝试生成与真实数据无法区分的数据(例如图像、文本或音频),而鉴别器的任务是区分真实数据和生成的数据。这种对抗性训练过程有助于生成器不断提高其创建越来越逼真的数据的能力。
想象一下,你想创作逼真的风景画。您决定为此目的使用 GAN。
- 生成器(艺术家):生成器就像一个从空白画布开始的艺术家。最初,它会随机生成一个根本不像风景的图像。
- 鉴别器(艺术评论家):鉴别器就像艺术评论家。它显示了真实的风景画(来自数据集)和生成器创建的假风景。一开始,鉴别器在区分真画和假画方面很糟糕,因为生成器的工作太糟糕了。
- 培训流程:
- 生成器创造了一个虚假的景观。
- 鉴别器对其进行评估。如果它检测到它是假的,它会向生成器提供反馈。
- 生成器使用此反馈来尝试创建更令人信服的景观。
- 此过程在循环中重复。随着时间的推移,生成器在制作逼真的风景方面变得更好,而鉴别器在分辨真假方面变得更加熟练。
最终结果:经过多次迭代,生成器变得非常擅长创建风景,以至于鉴别器几乎无法区分真实和生成的绘画。您现在有一个可以制作高度逼真的风景画的 GAN!
3.2 FAN的架构。

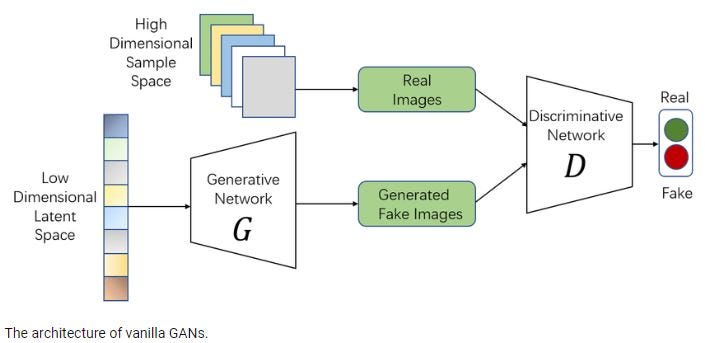
GAN 是一种深度学习架构,由两个协同工作的神经网络组成:生成器和鉴别器。生成器和鉴别器在一个称为对抗训练的过程中一起训练。在训练期间,生成器将随机噪声作为其输入,并将该噪声转换为有意义的输出,即类似于真实数据的假数据。
至于鉴别器,它接受生成器的输出和真实数据作为输入,如果输入是真的还是假的,则输出概率分数。两个网络一起训练。生成器从鉴别器接收概率分数,作为有关如何提高生成数据质量的反馈,并且循环继续。使用反向传播训练鉴别器以调整其权重和偏差,以最大程度地减少其分类误差。随着生成器的改进,鉴别器性能会下降,因为它不容易区分数据。
当鉴别器无法确定数据是来自生成器还是实际数据集时,则达到最佳阶段。
3.3 GAN 的生成器和评判器
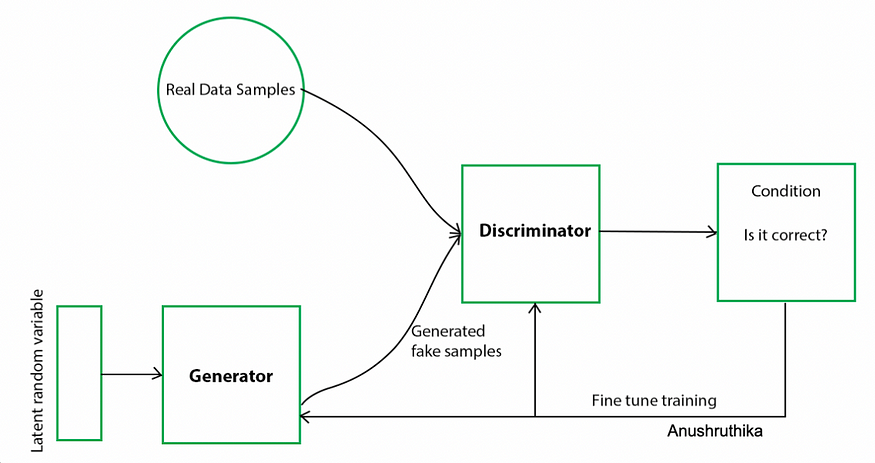
在每个GAN中,您提供一个随机噪声种子或潜在向量,它可以是作为噪声作为输入发送到生成器的维度或二维数组。生成器网络放大此阵列以创建伪造的二维图像。现在,假图像和真实图像都被发送到鉴别器网络,该网络经过训练以对真实和虚假图像进行分类。
根据生成器损耗和鉴别器损耗,对最大周期数进行微调。
3.4 实现 GAN 的 5 个步骤
- 根据应用定义GAN架构
- 训练鉴别器区分真假
- 训练生成器伪造数据,这可以欺骗鉴别器并看起来逼真
- 继续对多个时期进行鉴别器和生成器训练。
- 保存生成器模型以创建新的假数据。
在生成器的训练期间,将鉴别器值保持为常量,而训练鉴别器将生成器值保持为常量。每个人都应该在静态对手下接受训练。
应用
- 生成假数据以增强其他机器学习算法
- 生成人脸
- 图像到图像转换
- 文本到图像的翻译
- 超分辨率:获得更高分辨率的图片。
四、GAN的应用。
GAN 具有广泛的应用,包括以下内容:
1.图像和视频:GAN可以创建逼真的视频和图像,可用于图形和动画。
2. 图像超分辨率:使用超分辨率生成对抗网络 (SRGAN) 提高图像的分辨率
3. 文本到语音转换:GAN 可用于使用 GAN-TTS(文本到语音的生成对抗网络)从提供的文本生成语音
生成对抗网络是AIML中的强大工具,它彻底改变了机器与数据交互的方式。随着GAN的不断发展和进步,它们将对塑造AI的未来和推动创新产生更大的影响。生成式AI的增长证明了GAN的巨大潜力和影响。
五、表格 GAN(生成 AI)
表格 GAN 是一种生成对抗网络 (GAN),专门设计用于生成合成表格数据。与图像数据不同,表格数据通常表示为要素矩阵,其中每行表示一个实例或观测值,每列表示一个要素或属性。
表格 GAN 使用更适合表格数据的架构,例如多层感知器 (MLP) 或带有 1D 过滤器的卷积神经网络 (CNN)。生成器网络将随机噪声向量作为输入,并生成合成表格数据集作为输出。鉴别器网络试图通过输出二元分类分数来区分真实数据和合成数据。
表格 GAN 的训练过程涉及以对抗方式更新生成器和鉴别器网络,其中生成器尝试生成可以欺骗鉴别器的合成数据,鉴别器尝试正确区分真实数据和合成数据。生成器的目标是最小化鉴别器对合成数据的损失,而判别器的目标是最大化合成数据的损失,最小化真实数据的损失。
表格 GAN 具有多种应用,例如生成用于数据增强的合成数据集、插补数据集中的缺失值以及生成用于测试和验证目的的数据。但是,它们也有一些局限性,例如,如果训练数据不能代表真实总体,则存在生成有偏见或不切实际的数据的风险。
#GANs #GenerativeAI
六、生成式 AI:GAN 的验证技术
生成对抗网络 (GAN) 有几种验证技术,用于评估生成样本的质量和性能。GAN的一些最常见的验证技术是:
- 初始分数 (IS):此技术使用预先训练的初始模型来计算用于测量生成图像的多样性和质量的分数。分数是根据生成的图像与真实图像在类分布和视觉质量方面的相似性计算的。
- Frechet Inception Distance(FID):该技术还使用预先训练的Inception模型,但计算高维特征空间中真实图像和生成图像的特征表示之间的距离。较低的FID分数表示生成的图像与真实图像更相似。
- 精度和召回率(PR):该技术评估生成的样本相对于真实样本的精度和召回率。精度测量与实际样本相似的生成样本的百分比,而召回率测量与生成样本相似的实际样本的百分比。
- 目视检查:该技术涉及目视检查生成的样品并将其与真实样品进行比较。这是一种主观技术,但可以为生成的样本的视觉质量和多样性提供有价值的见解。
- 用户研究:该技术涉及进行用户研究,以评估生成样本的感知质量和多样性。这种技术更加主观,可能会根据参与者的偏好和偏见而有所不同。





