引言
实际上,在服务端程序开发和爬虫程序开发时,我们的大多数业务都是IO密集型业务,什么是IO密集型业务,通俗地说就是CPU运行时间只占整个业务执行时间的一小部分,而剩余的大部分时间都在等待IO操作。
IO操作包括http请求、数据库查询、文件读取、摄像设备录音设备的输入等等。这些IO操作会引起中断,使业务线程暂时放弃cpu,暂时停止运行,等待IO操作完成后在重新获得cpu、继续运行下去。
比如下面这段代码,我执行了一个很简单的IO操作,就是请求百度的主页面。在IO操作之后我又执行了一个一千万数量级的循环,用来模拟cpu计算业务。
func main() {
t := time.Now().UnixMilli()
// 发起http请求病接收响应
res, _ := http.Get("https://www.baidu.com")
fmt.Printf("https请求结束,耗时%dms\n", time.Now().UnixMilli()-t)
// 进行1e7次计算操作,用来模拟业务处理时cpu计算内容
body, _ := io.ReadAll(res.Body)
res.Body.Close()
for i := 1; i <= 1e7; i++ {
_ = i * i
_ = i + i
}
fmt.Printf("程序运行结束,总耗时%dms, 数据长度为%d", time.Now().UnixMilli()-t, len(body))
}
这段程序在我的电脑上的输出结果是:
https请求结束,耗时250ms
程序运行结束,总耗时256ms, 数据长度为227
不难看出,向百度发起请求耗费了250ms,而一千万次cpu计算仅耗费6ms。(实际情况中,大多数业务的cpu计算量甚至远远达不到1e7级别)
我们为什么要引入并发呢,正如操作系统课程上讲的那样,目的就是为了提高cpu的利用率,如果某个线程正处在等待IO的状态,此时cpu是空闲的,那么我们就应该用cpu去执行别的线程,而不是傻傻的等待这个进程结束再去进行别的操作。
并发样例
假设现在有一个爬虫项目,它的业务流程如下图所示,我大致描述一下流程:
- 首先要爬取A和B的页面,并解析页面结果
- 然后根据B页面的解析结果,设定好相关参数,对C、D、F页面进行爬取;同样的根据A页面的解析结果,设定好相关参数,对E页面进行爬取
- 接下来根据C、D页面的解析结果,设定好相关参数,对G页面进行爬取
- 最后,对E、F、G三个页面进行解析,得到我们需要的最终数据
虽然只是假设,但类似的业务流程在爬虫项目中是很常见的。
除此之外,类似的业务流程在后端程序开发中也很常见,对于前端的一个请求,后端很可能需要多次访问数据库、向下游服务器发送请求、访问内存外的缓存数据等等。
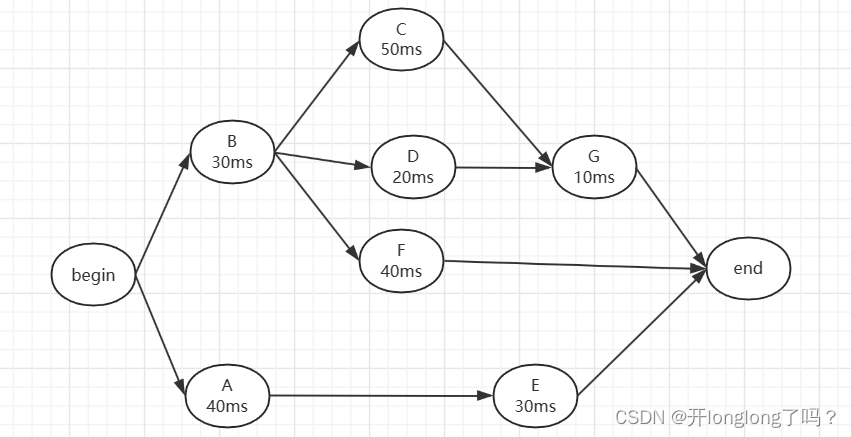
每个页面爬取耗费的时间如图中所示,由于cpu计算耗费时间很短,所以在这里就忽略不计。我们用sleep函数来模拟发起请求耗费的时间,代码如下图所示,每个task函数代表爬取一个页面:
func taskA() string {
time.Sleep(time.Millisecond * 40)
return "AAA"
}
func taskB() string {
time.Sleep(time.Millisecond * 30)
return "BBB"
}
func taskC(resultOfB string) string {
time.Sleep(time.Millisecond * 30)
return "CCC"
}
func taskD(resultOfB string) string {
time.Sleep(time.Millisecond * 30)
return "DDD"
}
func taskF(resultOfB string) string {
time.Sleep(time.Millisecond * 30)
return "FFF"
}
func taskE(resultOfA string) string {
time.Sleep(time.Millisecond * 30)
return "EEE"
}
func taskG(resultOfC, resultOfD string) string {
time.Sleep(time.Millisecond * 30)
return "GGG"
}
串行
串行,也就是不使用并发的代码如下所示:
串行的代码非常好写,从前往后把task函数顺序执行就行了,之所以在这里把串行代码和运行结果列出了,主要是为了和下面的并发做对比。
func main() {
t := time.Now().UnixMilli()
// 按照任务执行的先后要求,顺序执行所有任务
resultOfA := taskA()
fmt.Printf(" %dms: A over\n", time.Now().UnixMilli()-t)
resultOfB := taskB()
fmt.Printf(" %dms: B over\n", time.Now().UnixMilli()-t)
resultOfC := taskC(resultOfB)
fmt.Printf(" %dms: C over\n", time.Now().UnixMilli()-t)
resultOfD := taskD(resultOfB)
fmt.Printf(" %dms: D over\n", time.Now().UnixMilli()-t)
resultOfE := taskE(resultOfA)
fmt.Printf(" %dms: E over\n", time.Now().UnixMilli()-t)
resultOfF := taskF(resultOfB)
fmt.Printf(" %dms: F over\n", time.Now().UnixMilli()-t)
resultOfG := taskG(resultOfC, resultOfD)
fmt.Printf(" %dms: G over\n", time.Now().UnixMilli()-t)
// 打印E、F、G的运行结果,至此程序就运行结束了,打印程序运行所耗费的时间
fmt.Printf(" %dms: all over, %s, %s, %s\n", time.Now().UnixMilli()-t, resultOfE, resultOfF, resultOfG)
}
程序的执行结果如下所示,可以看到效率很慢很慢,总执行时间等于所有任务执行时间之和。
41ms: A over
73ms: B over
118ms: C over
164ms: D over
194ms: E over
240ms: F over
285ms: G over
286ms: all over, EEE, FFF, GGG
并发
本文的重点来了,如何并发地执行上面假设的爬虫程序?怎样才能让cpu的利用效率最高?
go为我们提供了非常好用的goroutine和chan,前者叫做协程也可以简单地认为是小型线程,能够以极小的开销和极快的速度启动一个并发任务;后者叫做通道,也可以叫管道,是协程和协程间通信的工具,不仅能够传递数据,还能够阻塞和唤醒协程从而实现协程间的同步。
在下面的代码中,我们使用通道来进行任务与任务之间的通信,我们为每一个任务都开一个协程,如果该任务没有前置依赖,那么就之间执行,然后把执行结果放到对应的通道中;如果该任务有前置依赖任务,那么先从通道中读取自己所需要的数据,然后再执行相应任务。
代码如下所示,逻辑很简单,主要是体现了一种并发的思想和并发执行任务的思路,现实情况中并发业务的代码肯定要复杂得多。
func main() {
t := time.Now().UnixMilli()
// AtoE代表A把自己的运行结果交给E的所经过的通道,下面同理
AtoE := make(chan string, 1)
BtoC := make(chan string, 1)
BtoF := make(chan string, 1)
BtoD := make(chan string, 1)
CtoG := make(chan string, 1)
DtoG := make(chan string, 1)
GtoEnd := make(chan string, 1)
FtoEnd := make(chan string, 1)
EtoEnd := make(chan string, 1)
// 每个go func代表着给某个任务开一个协程
// 为A任务开个协程
go func() {
resultOfA := taskA()
AtoE <- resultOfA
fmt.Printf(" %dms: A over\n", time.Now().UnixMilli()-t)
}()
// 为B任务开个协程
go func() {
resultOfB := taskB()
BtoF <- resultOfB
BtoC <- resultOfB
BtoD <- resultOfB
fmt.Printf(" %dms: B over\n", time.Now().UnixMilli()-t)
}()
// 为C任务开个协程
go func() {
resultOfB := <-BtoC
resultOfC := taskC(resultOfB)
CtoG <- resultOfC
fmt.Printf(" %dms: C over\n", time.Now().UnixMilli()-t)
}()
// 为D任务开个协程
go func() {
resultOfB := <-BtoD
resultOfD := taskC(resultOfB)
DtoG <- resultOfD
defer fmt.Printf(" %dms: D over\n", time.Now().UnixMilli()-t)
}()
// 为F任务开个协程
go func() {
resultOfB := <-BtoF
resultOfF := taskF(resultOfB)
FtoEnd <- resultOfF
fmt.Printf(" %dms: F over\n", time.Now().UnixMilli()-t)
}()
// 为E任务开个协程
go func() {
resultOfA := <-AtoE
resultOfE := taskC(resultOfA)
EtoEnd <- resultOfE
fmt.Printf(" %dms: E over\n", time.Now().UnixMilli()-t)
}()
// 为G任务开个协程
go func() {
resultOfC := <-CtoG
resultOfD := <-DtoG
resultOfG := taskG(resultOfC, resultOfD)
GtoEnd <- resultOfG
fmt.Printf(" %dms: G over\n", time.Now().UnixMilli()-t)
}()
// 接收E、F、G的运行结果,至此程序就运行结束了,打印程序运行所耗费的时间
resultOfE, resultOfF, resultOfG := <-EtoEnd, <-FtoEnd, <-GtoEnd
fmt.Printf(" %dms: all over, %s, %s, %s\n", time.Now().UnixMilli()-t, resultOfE, resultOfF, resultOfG)
}
程序的执行结果如下所示,可以看到程序运行中花费了105ms,很接近关键路径的长度90ms,说明我们这个程序的并发性很好,在最大程度上实现了cpu的高效利用。(PS:关键路径begin → B→ C → G → end)
43ms: A over
44ms: B over
74ms: E over
74ms: C over
74ms: D over
74ms: F over
105ms: G over
105ms: all over, CCC, FFF, GGG







