有的网站页面是动态加载的资源,使用bs4库只能获取静态页面内容,无法获取动态页面内容,通过selenium自动化测试工具可以获取动态页面内容。
参考之前的"bs4库爬取小说工具"文章代码,稍微修改下,就可以转成获取动态页面小说工具。
第一步:先确定目标网址
先找到小说目录页面。
网址首页:'https://www.bq0.net/'
目标小说目录页:'https://www.bq0.net/1bqg/898531870/'
第二步:确定章节目录和内容元素坐标
通过谷歌浏览器F12调试功能可以很快的定位页面元素位置.

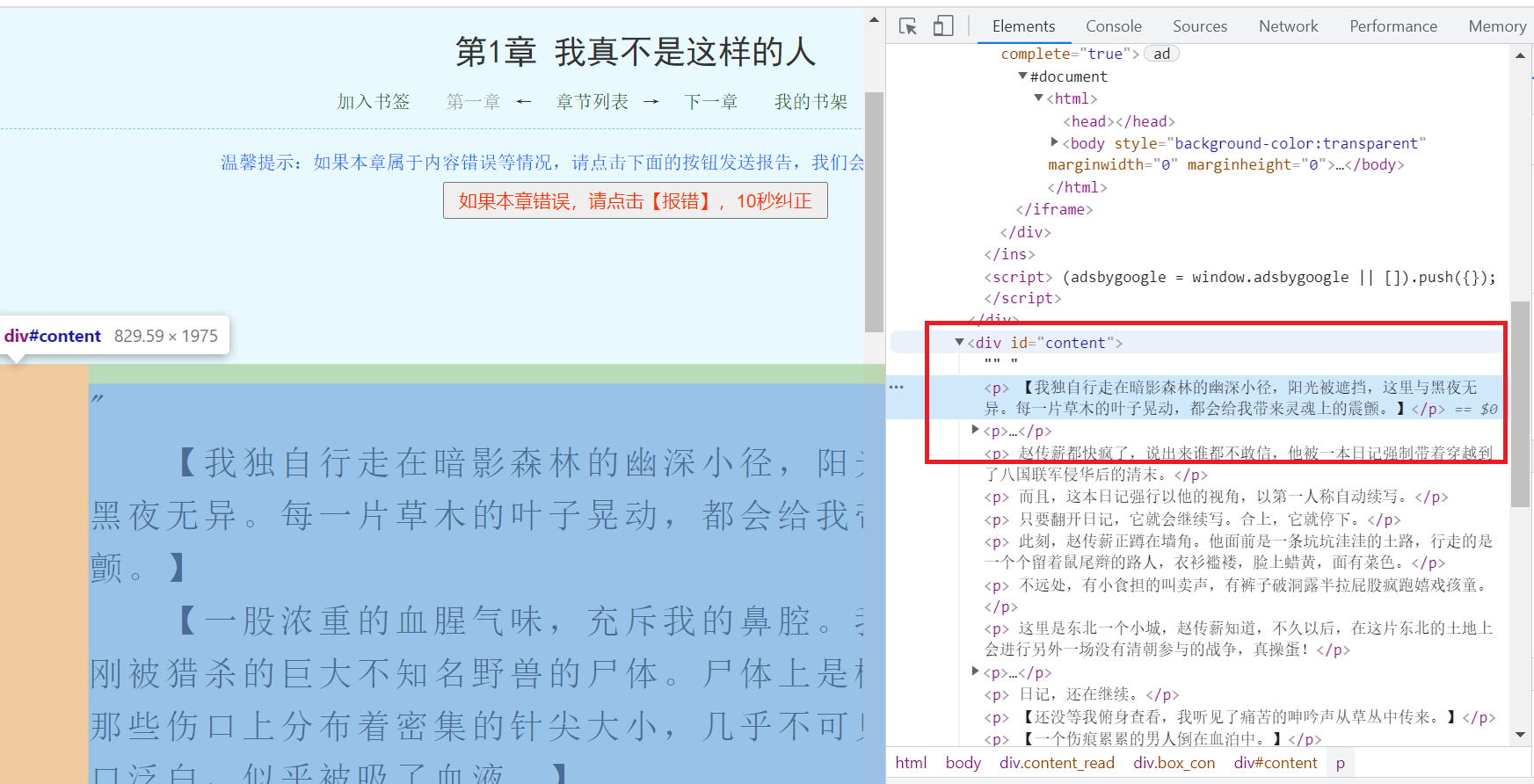
第三步:编写代码
采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块。
requests_webdriver.py:
# -*- coding: UTF-8 -*-
# selenium 自动化测试工具,爬取动态网页工具
import requests
import time
import re
from bs4 import BeautifulSoup
import random
import json
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# 打开驱动
def open_driver():
try:
# 连接浏览器web驱动全局变量
global driver
# Linux系统下浏览器驱动无界面显示,需要设置参数
# “–no-sandbox”参数是让Chrome在root权限下跑
# “–headless”参数是不用打开图形界面
'''
chrome_options = Options()
# 设为无头模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
# 连接Chrome浏览器驱动,获取驱动
driver = webdriver.Chrome(chrome_options=chrome_options)
'''
# 此步骤很重要,设置chrome为开发者模式,防止被各大网站识别出来使用了Selenium
options = Options()
# 去掉提示:Chrome正收到自动测试软件的控制
options.add_argument('disable-infobars')
# 以键值对的形式加入参数,打开浏览器开发者模式
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 打开浏览器开发者模式
# options.add_argument("--auto-open-devtools-for-tabs")
driver = webdriver.Chrome(chrome_options=options)
# driver = webdriver.Chrome()
print('连接Chrome浏览器驱动')
# 浏览器窗口最大化
driver.maximize_window()
'''
1, 隐式等待方法
driver.implicitly_wait(最大等待时间, 单位: 秒)
2, 隐式等待作用
在规定的时间内等待页面所有元素加载;
3,使用场景:
在有页面跳转的时候, 可以使用隐式等待。
'''
driver.implicitly_wait(3)
# 强制等待,随机休眠 暂停0-3秒的整数秒,时间区间:[0,3]
time.sleep(random.randint(0, 3))
except Exception as e:
driver = None
print(str(e))
# 关闭驱动
def close_driver():
driver.quit()
print('关闭Chrome浏览器驱动')
def get_html_by_webdriver(url_str):
'''
@方法名称: 根据浏览器驱动获取动态网页内容
@中文注释: 根据浏览器驱动获取动态网页内容
@入参:
@param url_str str url地址
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@作 者: PandaCode辉
@创建时间: 2023-09-21
@使用范例: get_html_by_webdriver('www.baidu.com')
'''
try:
if (not type(url_str) is str):
return [0, "111111", "url地址参数类型错误,不为字符串", [None]]
print('浏览器驱动不存在,重新打开浏览器驱动.')
# open_driver()
# 打开网址网页
driver.get(url_str)
# 等待6秒启动完成
driver.implicitly_wait(6)
# 获取动态网页的html字符串信息
html_str = driver.page_source
print('开始关闭Chrome浏览器驱动')
# close_driver()
# print(html_str)
return [1, '000000', "获取动态网页内容成功", [html_str]]
except Exception as e:
print("获取动态网页内容异常超时," + str(e))
print('开始关闭Chrome浏览器驱动')
close_driver()
return [0, '999999', "获取动态网页内容异常超时," + str(e), [None]]
def spider_novel_mulu(req_dict):
'''
@方法名称: 爬取小说章节目录
@中文注释: 根据参数爬取小说目录,保存到json文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@创建时间: 2023-09-21
@使用范例: spider_novel_mulu(req_dict)
'''
try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
open_driver()
# 根据url地址获取动态网页信息
rst = get_html_by_webdriver(req_dict['mulu_url'])
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2))
close_driver()
if rst[0] != 1:
return rst
html_str = rst[3][0]
# 使用BeautifulSoup解析网页数据
soup = BeautifulSoup(html_str, "html.parser")
# 目录列表地址
tar_dir_href = soup.select(req_dict['tar_dir_href'])
# print(tar_dir_href)
tar_len = len(tar_dir_href)
print('初始爬取章节总数量:', tar_len)
# 过滤章节下标初始化
del_index = 0
for dir_href in tar_dir_href:
chap_title = dir_href.text
# print(chap_title)
if '第1章' in chap_title:
break
del_index += 1
# 过滤章节下标
print(del_index)
# 过滤章节,从第一章开始
tar_dir_href_list = tar_dir_href[del_index:]
tar_len = len(tar_dir_href_list)
print('过滤后章节总数量:', tar_len)
# 目录容器
mulu_dict = {}
# 章节标题,列表
mulu_dict['chap_title'] = []
# 章节url,列表
mulu_dict['chap_url'] = []
# 是否完成标志: 0-未完成,1-已完成,列表
mulu_dict['flag'] = []
# 循环读取章节
for dir_href in tar_dir_href_list:
# 章节标题
chap_title = dir_href.text
print(chap_title)
mulu_dict['chap_title'].append(chap_title)
# 章节url
chap_url = req_dict['novel_url'] + dir_href['href']
print(chap_url)
mulu_dict['chap_url'].append(chap_url)
mulu_dict['flag'].append('0')
# 转换为json字符串
json_str = json.dumps(mulu_dict)
json_name = req_dict['novel_name'] + '.json'
# 写入json文件
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
# 返回容器
return [1, '000000', '爬取小说目录成功', [None]]
except Exception as e:
print("爬取小说目录异常," + str(e))
return [0, '999999', "爬取小说目录异常," + str(e), [None]]
def spider_novel_content(req_dict):
'''
@方法名称: 爬取小说章节明细内容
@中文注释: 读取章节列表json文件,爬取小说章节明细内容,保存到文本文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@创建时间: 2023-09-21
@使用范例: spider_novel_content(req_dict)
'''
try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]]
# 章节目录文件名
json_name = req_dict['novel_name'] + '.json'
# 检查文件是否存在
if os.path.isfile(json_name):
print('json文件存在,不用重新爬取小说目录.')
else:
print('json文件不存在')
# 爬取小说目录
spider_novel_mulu(req_dict)
# 读取json文件
with open(json_name, 'r') as f:
data_str = f.read()
# 转换为字典容器
mulu_dict = json.loads(data_str)
"""
关于open()的mode参数:
'r':读
'w':写
'a':追加
'r+' == r+w(可读可写,文件若不存在就报错(IOError))
'w+' == w+r(可读可写,文件若不存在就创建)
'a+' ==a+r(可追加可写,文件若不存在就创建)
对应的,如果是二进制文件,就都加一个b就好啦:
'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
"""
file_name = req_dict['novel_name'] + '.txt'
# 在列表中查找指定元素的下标,未完成标志下标
flag_index = mulu_dict['flag'].index('0')
print(flag_index)
# 未完成标志下标为0,则为第一次爬取章节内容,否则已经写入部分,只能追加内容写入文件
# 因为章节明细内容很多,防止爬取过程中间中断,重新爬取,不用重复再爬取之前成功写入的数据
if flag_index == 0:
# 打开文件,首次创建写入
fo = open(file_name, "w+", encoding="utf-8")
else:
# 打开文件,再次追加写入
fo = open(file_name, "a+", encoding="utf-8")
# 章节总数
chap_len = len(mulu_dict['chap_url'])
# 在列表中查找指定元素的下标
print('章节总数:', chap_len)
print('打开浏览器驱动')
open_driver()
# 循环读取章节
for i in range(flag_index, chap_len):
# 章节标题
# chap_title = mulu_dict['chap_title'][i]
print('i : ', i)
# # 写入文件,章节标题
# fo.write(chap_title + "\r\n")
# 章节url
chap_url = mulu_dict['chap_url'][i]
# 章节分页url列表初始化
page_href_list = []
# 根据url地址获取网页信息
chap_rst = get_html_by_webdriver(chap_url)
time.sleep(3)
if chap_rst[0] != 1:
# 跳出循环爬取
break
chap_html_str = chap_rst[3][0]
# 使用BeautifulSoup解析网页数据
chap_soup = BeautifulSoup(chap_html_str, "html.parser")
# 章节内容分页数和分页url
# 获取分页页码标签下的href元素取出
page_href_list_tmp = chap_soup.select("div#PageSet > a")
all_page_cnt = len(page_href_list_tmp)
print("分页页码链接数量:" + str(all_page_cnt))
# 去除最后/后面数字+.html
tmp_chap_url = re.sub(r'(\d+\.html)', '', chap_url)
for each in page_href_list_tmp:
if len(each) > 0:
chap_url = tmp_chap_url + str(each.get('href'))
print("拼接小说章节分页url链接:" + chap_url)
# 判断是否已经存在列表中
if not chap_url in page_href_list:
page_href_list.append(chap_url)
print("分页url链接列表:" + str(page_href_list))
# 章节标题
chap_title = chap_soup.select(req_dict['chap_title'])[0].text
print(chap_title)
# 写入文件,章节标题
fo.write("\n" + chap_title + "\n")
# 章节内容
chap_content = chap_soup.select(req_dict['chap_content'])[0].text
chap_content = chap_content.replace(' ', '\n').replace(' ', '\n')
# print(chap_content)
# 写入文件,章节内容
fo.write(chap_content + "\n")
# 分页列表大于0
if len(page_href_list) > 0:
for chap_url_page in page_href_list:
print("chap_url_page:" + chap_url_page)
time.sleep(3)
# 等待3秒启动完成
driver.implicitly_wait(3)
print("等待3秒启动完成")
# 根据url地址获取网页信息
chap_rst = get_html_by_webdriver(chap_url_page)
if chap_rst[0] != 1:
# 跳出循环爬取
break
chap_html_str = chap_rst[3][0]
# 然后用BeautifulSoup解析html格式工具,简单的获取目标元素
chap_soup_page = BeautifulSoup(chap_html_str, "html.parser")
# 章节内容
chap_content_page = chap_soup_page.select(req_dict['chap_content'])[0].text
chap_content_page = chap_content_page.replace(' ', '\n').replace(' ', '\n')
# print(chap_content_page)
# 写入文件,章节内容
fo.write(chap_content_page + "\n")
# 爬取明细章节内容成功后,更新对应标志为-1-已完成
mulu_dict['flag'][i] = '1'
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
print("循环爬取明细章节内容,写入文件完成")
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
# 返回容器
return [1, '000000', '爬取小说内容成功', [None]]
except Exception as e:
print('关闭浏览器驱动')
close_driver()
# 关闭文件
fo.close()
# 转换为json字符串
json_str = json.dumps(mulu_dict)
# 再次写入json文件,保存更新处理完标志
with open(json_name, 'w', encoding="utf-8") as json_file:
json_file.write(json_str)
print("再次写入json文件,保存更新处理完标志")
print("爬取小说内容异常," + str(e))
return [0, '999999', "爬取小说内容异常," + str(e), [None]]
# 主方法
if __name__ == '__main__':
req_dict = {}
'''可变参数,小说名称和对应目录页面url地址'''
# 小说名称
req_dict['novel_name'] = '清末的法师'
# 目录页面地址,第1页
req_dict['mulu_url'] = 'https://www.bq0.net/1bqg/898531870/'
'''下面参数不用变,一个官网一个特定参数配置'''
# 官网首页
req_dict['novel_url'] = 'https://www.bq0.net/'
# 章节目录定位
req_dict['tar_dir_href'] = "div.box_con>dl>dd>a"
# 章节标题定位
req_dict['chap_title'] = 'div.bookname > h1'
# 章节明细内容定位
req_dict['chap_content'] = 'div#content'
# 爬取小说目录
# spider_novel_mulu(req_dict)
# 爬取小说内容
spider_novel_content(req_dict)
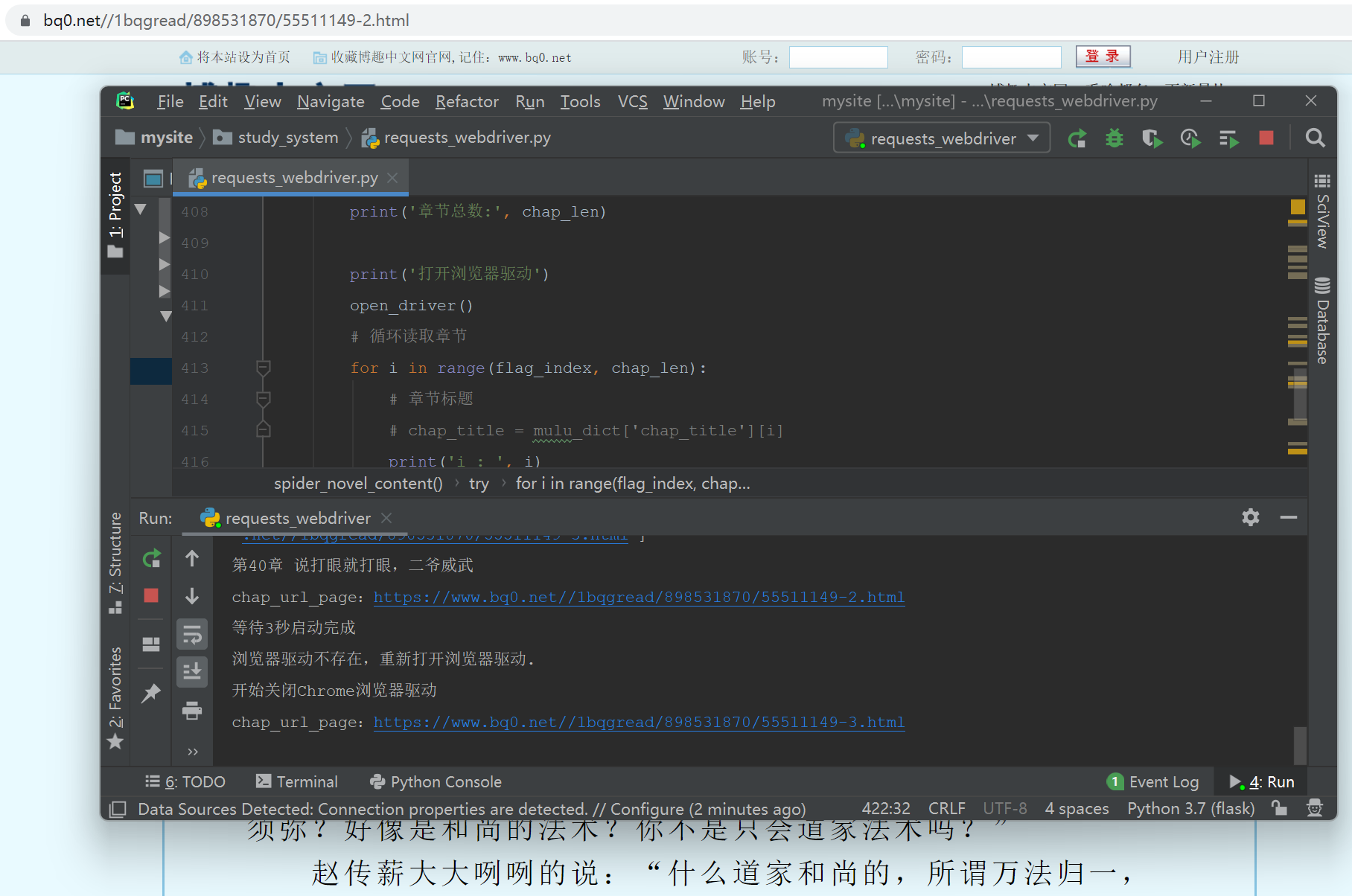
第四步:运行测试效果

-------------------------------------------end---------------------------------------









