目录
内存区域划分
如果内存区域只有一块,不太方便,为了更加方便使用,就把整个空间隔成很多区域,每一个区域都有不同的作用
JVM,在启动的时候,会申请一整个很大的区域,JVM 是一个应用程序,从操作系统里申请内存,JVM把整个空间分层几个部分,每个部分各自有不同的功能作用
每一个Java进程都包含一个JVM
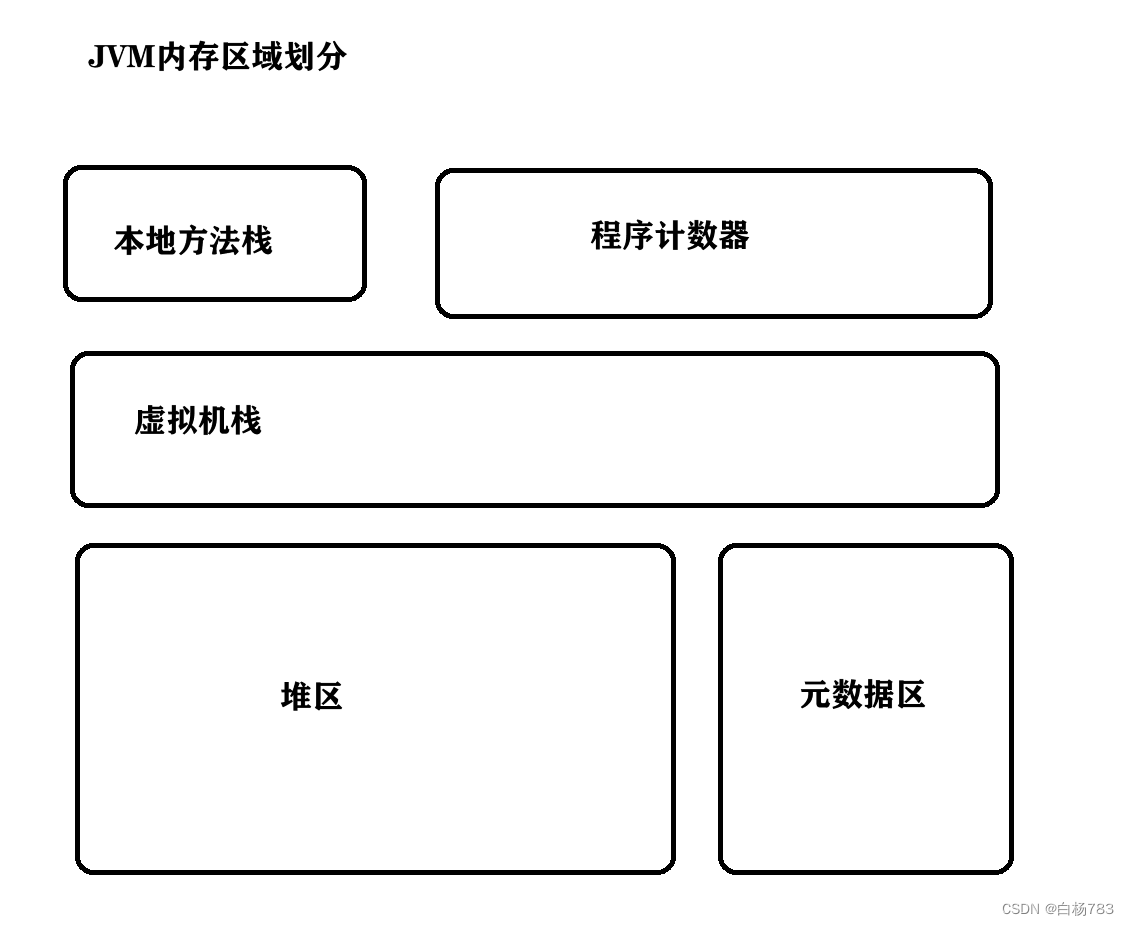
JVM中的栈
JVM中的栈不是数据结构中的栈,是JVM中的一个特定空间,对于 JVM 虚拟机,这里存储是 方法(我们自己写的java代码中的方法) 之间的调用关系.对于 本地方法栈,存储的是JVM内部方法的调用关系
整个栈空间内部,可以认为包含很多元素,每个元素表示一个方法. 这里的每个元素,称为一个"栈帧",这一个栈帧里,会包含这个方法的 入口地址,方法的参数是什么,返回地址是什么,局部变量等
数据结构的栈,是一个通用的更广泛的概念,是后进先出的数据结构,此处的JVM中的栈,特指JVM上的一块内存空间,由于函数调用,也是有后进先出的特点
JVM中虚拟机中的栈,有很多,每一个线程都有一个属于自己的栈,每一个栈都有很多的栈帧,调用一个方法会创建栈帧,方法结束,就会销毁这个栈帧

JVM中的堆
堆是整个 JVM 空间最大的区域,new 出来的对象(引用类型),都是在堆上.因此类的成员变量也在堆山.
堆是一个进程只有一份,一个进程中的多个线程共用一份堆.栈是一个线程有一个栈,一个进程有N个栈
堆的生命周期比较长,堆上面的方法执行结束默认不自动释放空间,而栈上面的方法会随着方法执行结束,自动释放空间
程序计数器
记录当前线程执行到哪个指令,每个线程都独有一份程序计数器
方法区(元数据区)
方法区每个进程只有一个,多个线程共用一份, 类对象,常量池,静态成员(static)都在方法区
给一段代码,某个变量在哪个区域上?
原则
1.局部变量在 栈 上
2.普通成员变量在 堆 上
3.静态成员变量在 方法区/元数据区 上
类加载
类加载: 类加载就是 .class文件,从文件(硬盘)被加载到内存中(方法区/元数据区)这样的过程
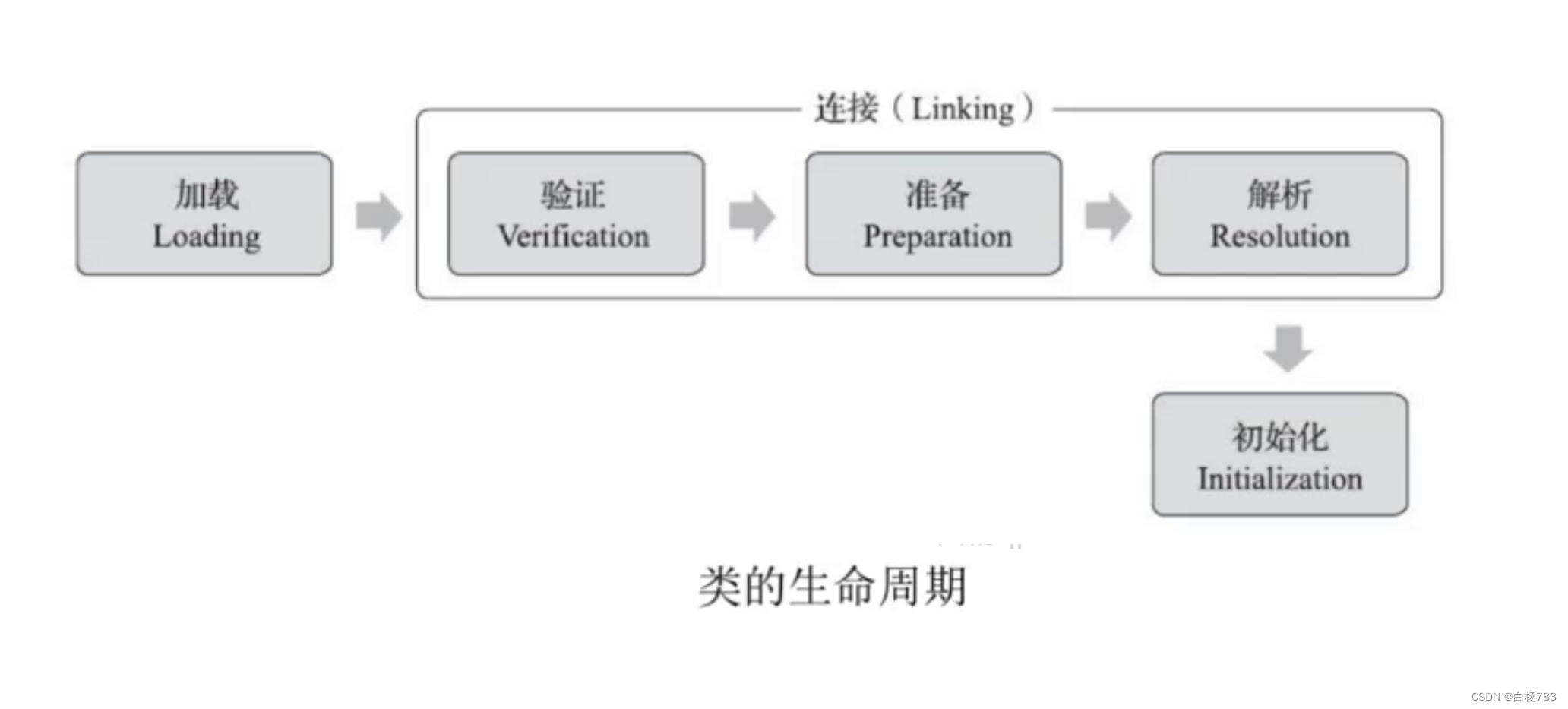
加载: 把.class文件找到,打开文件,读文件,把文件内容读到内存中,最终得到类对象
验证: 检查.class文件格式是否正确
准备: 给类对象分配一个内存空间(在方法区/元数据区占个位置),会使静态成员被设置成0值
解析: 初始化字符串常量,把符号引用转换为直接引用
初始化: 调用构造方法,进行成员初始化,执行代码块,静态代码块,加载父类...
类加载时机
java程序运行,不是把所有的类都加载了,而是真正用到了才加载(懒汉模式),一旦加载过后,后续再使用就不必重复加载了
1.构造类的实例
2.调用这个类的 静态方法/使用静态属性
3.加载子类,就会先加载父类
双亲委派模型
双亲委派模型,描述的是 加载过程 找.class文件,基本过程
JVM默认提供了 三个 类加载器
BootstrapClassLoader: 负责加载标准库中的类(java规范)
ExtensionClassLoader: 负责加载JVM扩展中的类(规范之外)
ApplicationClassLoader: 负责加载用户提供的第三方库/用户项目代码 中的类
上述三个类存在父子关系,BootstrapClassLoader是ExtensionClassLoader的父类,ExtensionClassLoader是ApplicationClassLoader的父类
加载一个类的时候是先从ApplicationClassLoader开始的,但是 ApplicationClassLoader会把加载任务,交给父亲,让父亲去执行.于是ExtensionClassLoader要去加载,但是ExtensionClassLoader也会委托给自己的父亲,于是BootstrapClassLoader就要去加载了,BootstrapClassLoader也想委托给自己的父类,可以它没有父类,因此就由自己加载,此时 Bootstrap就会搜索自己负责的标准库目录的相关的类,如果找到就加载,如果没找到,就由子类加载器进行加载.. ExtensionClassLoader 真正搜索扩展库相关的目录,如果找到就加载,如果没找到就由子类加载器加载. ApplicationClassLoader,加载器进行加载(由于当前没有子类,如果没有找到,就会抛出 类找不到 这样的异常)
GC 垃圾回收机制
垃圾指的是不再使用的内存,垃圾回收,就是把不用的内存帮我们自动释放掉了. 而GC 就是一种主流的垃圾回收机制,GC垃圾回收机制 主要是针对 堆 里面的空间进行释放的, GC 是以"对象" 为基本单位,进行回收的
GC 实际工作过程
1.找到垃圾/判定垃圾
哪个对象是垃圾,哪个对象不是垃圾,哪个对象以后可能还要使用,哪个对象后面不用了,关键思路是:看这个对象,有没有别的引用指向它(java中,使用对象只能通过引用来使用,如果一个对象没有引用指向,那么它一定不被使用)
具体如何判断对象是否有引用指向
1.可达性分析(Java中的做法)
Java 中的对象,都是通过引用来指向并访问的,经常是,一个引用指向一个对象,这个对象里的成员,又指向别的对象,比如链表,二叉树
整个Java中所有的对象,通过链表/树结构,整体串起来,可达性分析 就是把所有这些对象被组织的结构称为树,从树根节点出发,所有能被访问到的对象,标记成 "可达",不能访问到的,就是"不可达"
因此,通过上述标记JVM就可以知道所有可达的对象,剩下的不可达对象,就视为垃圾 进行回收
2.引用计数
给每个对象分配一个计数器(整数),每有一个引用指向该对象,计数器就+1,每次该引用被销毁 计数器就-1,引用计数为0时,此时这个对象就可以认为是垃圾了
2.清理垃圾
1.标记清除
直接把被标记的垃圾清除掉,缺点: 被释放的空间是闲散,零散,不连续,而我们申请内存需要连续的内存空间
2.复制算法
把不是垃圾的对象,复制到另一半,然后把刚刚有垃圾的一半整个空间删除掉.解决了内存碎片的问题
缺点,空间利用率低,如果要是垃圾少,有效对象多,复制成本大
3.标记整理
类似顺序表删除中间元素,把是垃圾的元素用不是垃圾的元素给填掉(元素搬运),再释放空间
分代回收(复制算法+标记整理)
根据不同的场景,使用不同的算法
分代: 基于经验规律,根据生命周期的长短,分别使用不同的算法
给对象引入一个 年龄 的概念,单位是 熬过GC垃圾回收的轮次,把年龄小的对象使用复制算法删除(年龄小的对象中,可能是垃圾的比较多),把年龄大的对象使用标记整理删除(老年代对象可能是垃圾较少)







