1. 锁是什么?
是为了保证数据并发访问时的一致性和有效性,数据库提供的一种机制。锁机制的优劣直接影响到数据库的并发处理能力和系统性能,所以锁机制也就成为了各种数据库的核心技术之一。同时,锁机制也为实现 MySQL事务的各个隔离级别提供了保证。
2. 锁的缺点
锁是一种消耗资源的机制,想要实现锁的各种操作,包括获得锁、检测锁是否已解除、释放锁等 ,都会增加系统的开销。
3. 锁的分类
为了尽可能提高数据库的并发量,每次锁定的数据范围越小越好,但是锁定越小的范围,耗费的系统资源越多,也会系统性能下降。所以,为在高并发响应和系统性能两方面进行平衡,这样就产生了“锁粒度”的概念,可以将锁粒度理解成锁定范围。
那么根据锁的粒度MySQL细分了如下三种锁:表级锁、行级锁、页级锁。
3.1. 表级锁(table lock)
表级锁是一种表级别的锁定机制,是 MySQL 中最大颗粒度的锁定机制,它会锁定整张表,但同时可以很好的避免死锁。
MyISAM存储引擎默认使用表级锁。
表级锁根据操作的不同,分为:读锁(共享锁)、写锁(排他锁)。
3.1.1.读锁(read lock)
也叫共享锁(shared lock),一个用户在对表进行读操作(select)时, 针对同一份数据,多个读操作可以同时进行而不会互相影响。
3.1.2.写锁(write lock)
也叫排他锁(exclusive lock),一个用户在对表进行写操作(插入、删除、更新等)时,需要先获得写锁,它会阻塞其它用户对该表的所有读写操作,具备排他性。
小结: 1.读锁会阻塞写操作,不会阻塞读操作 2.写锁会阻塞读和写操作
3.1.3.表级锁的优点和缺点
- 对整张表加锁
- 开销小
- 加锁快
- 无死锁
- 锁粒度大,发生锁冲突概率大,并发性低
3.2. 行级锁(row lock)
行级锁的锁定颗粒度在 MySQL 中是最小的,只针对操作的当前行进行加锁,所以行级锁发生锁定资源争用的概率也最小。
由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要处理并发逻辑更多,同时消耗的资源也就更大。此外,行级锁也最容易发生死锁。所以说行级锁最大程度地支持并发处理的同时,也带来了最大的锁开销。
InnoDB 存储引擎默认使用行级锁。
行级锁根据操作的不同,分为:读锁(共享锁 S)、写锁(排他锁 X)、意向共享锁(IS)、意向排它锁(IX)。
3.2.1.意向共享锁IS
一个事务给一个数据行加共享锁时,必须先获得该表的意向共享锁,简称IS锁。
3.2.2.意向排他锁IX
一个事务给一个数据行加排他锁时,必须先获得该表的意向排他锁,简称IX锁。
3.2.3.行级锁的优点和缺点
- 对一行数据加锁
- 开销大
- 加锁慢
- 会出现死锁
- 锁粒度小,发生锁冲突概率最低,并发性高
3.3. 页级锁(page lock)
页级锁是 MySQL 中比较独特的一种锁定级别。
页级锁的颗粒度介于行级锁与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力同样也是介于上面二者之间。另外,页级锁和行级锁一样,会发生死锁。
页级锁主要应用于 BDB 存储引擎。
3.4. 行级锁的实现算法
在 MySQL的InnoDB存储引擎中,行锁通过给之前索引内容的索引树中的索引项加锁来实现,如果没有索引,InnoDB 将通过隐藏的主键索引(聚集索引)引来对记录加锁。
InnoDB 主要通过以下 3 种算法实现行级锁:
- 记录锁(
Record Lock):直接对索引项加锁,属于单个行记录上的锁。Record Lock总是会去锁住索引记录,如果InnoDB存储引擎表建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定。 - 间隙锁(
Gap Lock):间隙锁是一个在索引记录之间的间隙上进行锁定。间隙可以是两个索引记录之间,也可能是第一个索引记录之前或最后一个索引之后的空间。间隙锁会锁定该间隙空间,防止其它事务在这个区域内插入、修改、删除数据; - 临键锁(
Next-Key Lock):记录锁+间隙锁组合起来用就叫做临键锁Next-Key Lock。 锁定一个范围,同时包含记录本身。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
小结: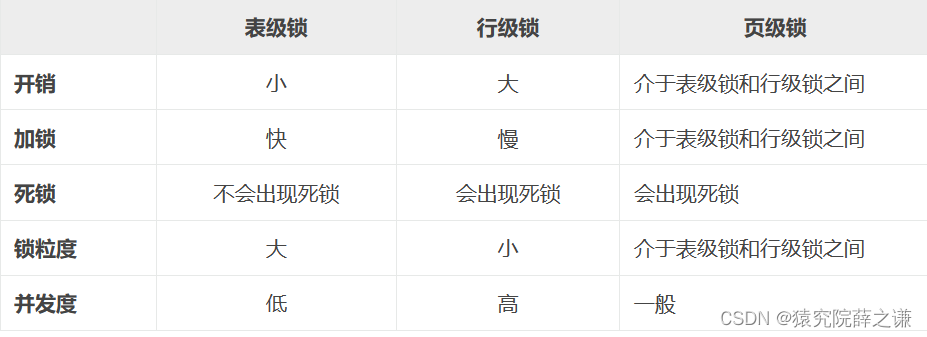
4. 锁的兼容与互斥
锁和锁之间的关系,要么是兼容的,要么是互斥的。
- 锁
a和锁b兼容是指:操作同样一组数据时,如果事务t1获取了锁a,另一个事务t2还可以获取锁b; - 锁
a和锁b互斥是指:操作同样一组数据时,如果事务t1获取了锁a,另一个事务t2在t1释放锁a之前无法释放锁b。
如果一个事务请求的锁模式与当前的锁兼容,InnoDB 就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
5. 乐观锁与悲观锁
5.1.乐观锁(Optimistic Lock)
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于读多写少的应用场景。
5.2.悲观锁(Pessimistic Lock)
悲观锁(又名“悲观并发控制”,Pessimistic Concurrency Control,缩写“PCC”)是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作读某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
所以,顾名思义就是很悲观的锁定思想,每次去拿数据的时候都认为其它的事务会修改,所以每次在拿数据的时候都会上锁,这样其它事务想要获取这个数据就会被block阻塞,直到当前事务释放锁。关系型数据库中的行锁,表锁,读锁,写锁等,都是在做操作之前先上锁。它指的是对数据被外界修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。
悲观锁主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
5.3.两种锁的优缺点:
- 乐观锁适用于写比较少的情况下,即:并发冲突相对较低的场景。这样可以省去了锁的开销,加大了系统的整个吞吐量。
- 悲观锁适用于写入比较多的情况下,因为如果经常产生数据冲突,使用乐观锁,应用程序会不断的
retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
6. 死锁
数据库的死锁是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。常见的报错信息为“Deadlock found when trying to get lock...”。
死锁发生以后,只有部分或完全回滚其中一个事务,才能打破死锁。多数情况下只需要重新执行因死锁回滚的事务即可。
所以在实际应用中,通常可以使用的避免死锁的办法:
- 如果不同程序会并发存取多个表,或者涉及多行记录时,尽量约定以相同的顺序访问表,这样可以大大降低死锁的发生。例如:事务1和2都请求需要请求资源A,B,那么顺序最好保持一致AB或者BA,一个AB,一个BA,则死锁概率会大大提升。
- 业务中要及时提交或者回滚事务,可减少死锁产生的概率。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率。
- 对于非常容易产生死锁的部分,可以尝试升级锁粒度,表级锁不会产生死锁。









