一、进程间通信的目的
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
二、管道通信
1.匿名管道
通过打开同一个文件,父子进程对文件进行读写操作,父子进程在文件内核缓冲区中写入或读出数据,从而实现通信
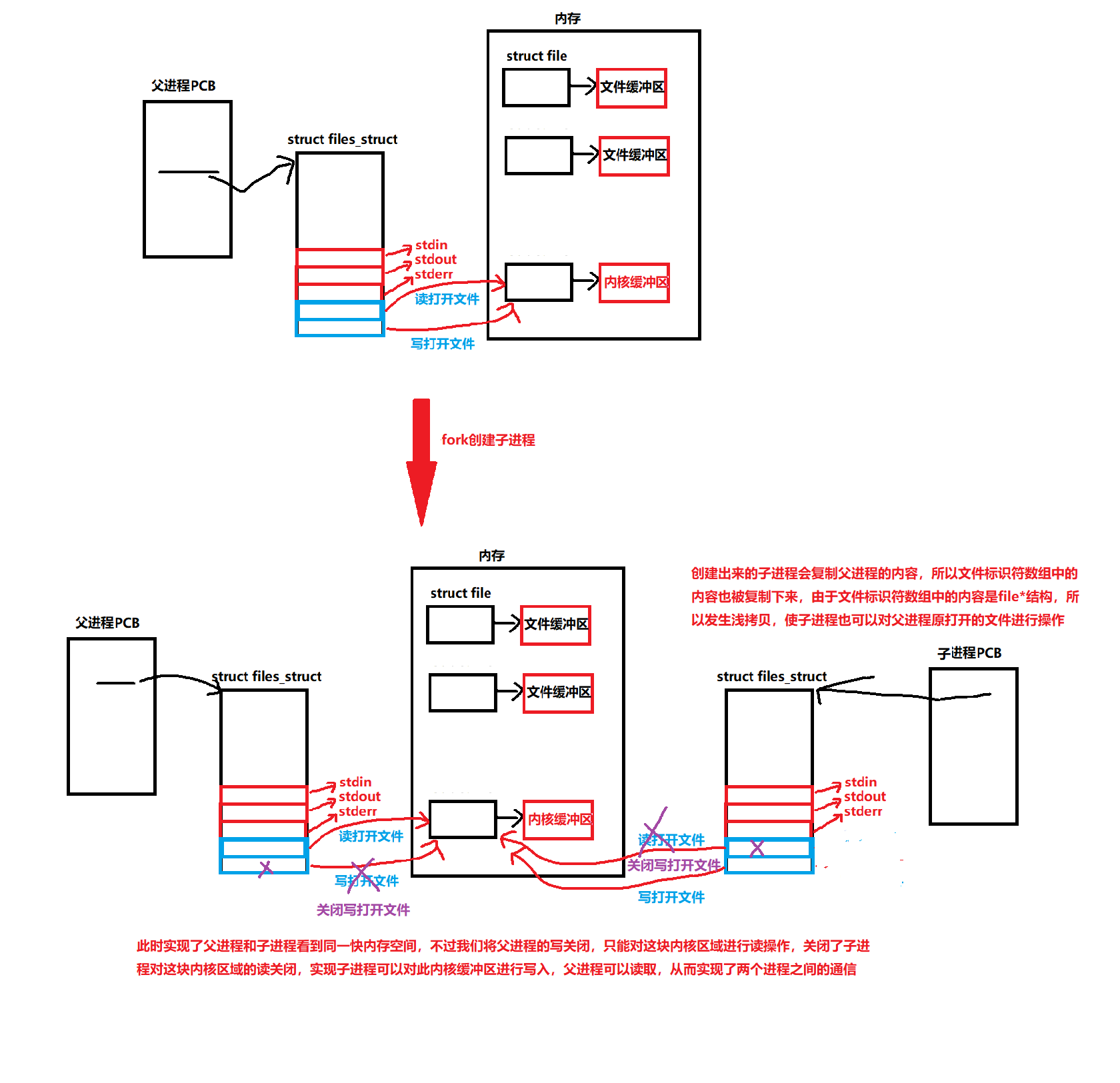
创建匿名管道
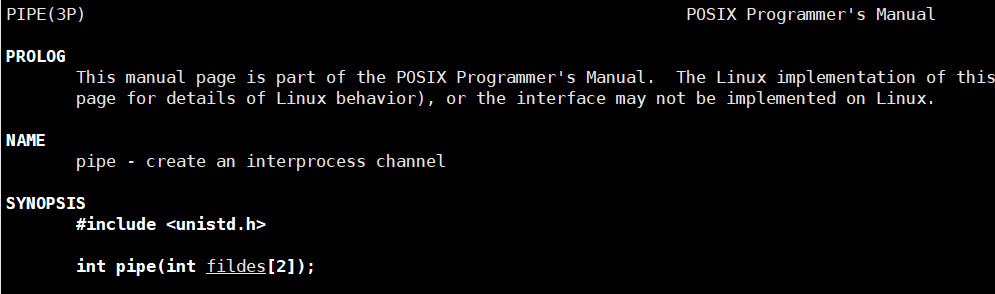
pipe:创建一个管道,参数为输出型参数,打开两个文件描述符(fd),返回值为0表示打开失败。
#include<iostream>
#include<string>
#include<cerrno>
#include<cassert>
#include<string.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int pipefd[2]={0};
//1.创建管道
int n=pipe(pipefd);
if(n<0)
{
//创建不成功
std::cout<<"pipe error, "<<errno<<":"<<strerror(errno)<<std::endl;
return 1;
}
std::cout<<"pipefd[0]: "<<pipefd[0]<<std::endl; //读
std::cout<<"pipefd[1]: "<<pipefd[1]<<std::endl; //写
//2.创建子进程
pid_t id=fork();
assert(id!=-1); //省去判断
if(id==0)
{
//子进程
//3.关闭不需要的fd 父进程读取,子进程进行写入
close(pipefd[0]);
//4.开始通信
std::string namestr="hello,我是子进程";
int cnt=1;
char buffer[1024];
while(true)
{
snprintf(buffer,sizeof(buffer),"%s, 计数器:%d, 我的id: %d",namestr.c_str(),cnt++,getpid());
write(pipefd[1],buffer,strlen(buffer));
sleep(1);
}
exit(0); //子进程退出
}
//父进程
//3.关闭不需要的fd 父进程读取,子进程进行写入
close(pipefd[1]);
//4.开始通信
char buffer[1024];
while(true)
{
//sleep(1);
int n=read(pipefd[0],buffer,sizeof(buffer)-1);
if(n>0)
{
//读取成功
buffer[n]='\0';
std::cout<<"我是父进程, child give me massage: "<<buffer<<std::endl;
}
}
return 0;
}
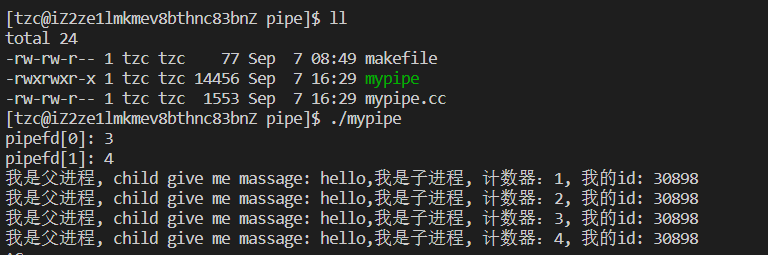
子进程往内核缓冲区中写入数据,父进程读取数据,实现了简单的父子间进程通信。
管道的特点:
1.只能单向通信
2.面向字节流
3.只能在有"血缘"关系的进程中通信
4.管道也是文件,管道的生命周期随进程
5.管道自带同步系统,原子性写入
云服务器中,管道的大小为64KB,写端写满后不会再写,会等读端读取管道内容,且读取4KB后才会重新写入(读端的容量为4KB)

#include<iostream>
#include<string>
#include<cerrno>
#include<cassert>
#include<string.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int pipefd[2]={0};
//1.创建管道
int n=pipe(pipefd);
if(n<0)
{
//创建不成功
std::cout<<"pipe error, "<<errno<<":"<<strerror(errno)<<std::endl;
return 1;
}
std::cout<<"pipefd[0]: "<<pipefd[0]<<std::endl; //读
std::cout<<"pipefd[1]: "<<pipefd[1]<<std::endl; //写
//2.创建子进程
pid_t id=fork();
assert(id!=-1); //省去判断
if(id==0)
{
//子进程
//3.关闭不需要的fd 父进程读取,子进程进行写入
close(pipefd[0]);
//4.开始通信
std::string namestr="hello,我是子进程";
int cnt=1;
char buffer[1024];
int count=0;
char c='x';
while(true)
{
//snprintf(buffer,sizeof(buffer),"%s, 计数器:%d, 我的id: %d",namestr.c_str(),cnt++,getpid());
//write(pipefd[1],buffer,strlen(buffer));
write(pipefd[1],&c,1);
count++;
printf("%d\n",count);
//sleep(1);
}
exit(0); //子进程退出
}
//父进程
//3.关闭不需要的fd 父进程读取,子进程进行写入
close(pipefd[1]);
//4.开始通信
char buffer[1024];
while(true)
{
sleep(3);
int n=read(pipefd[0],buffer,sizeof(buffer)-1);
if(n>0)
{
//读取成功
buffer[n]='\0';
std::cout<<"我是父进程, child give me massage: %d,"<<n<<buffer<<std::endl;
}
}
return 0;
}
管道的读写规则
当没有数据可读时
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
当管道满的时候
O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
如果所有管道写端对应的文件描述符被关闭,则read返回0 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
1.读端不读或读的慢,写端要等读端
2.读端关闭,写端收到SIGPIPE信号直接终止
3.写端不写或者写的慢,读端要等写端
4.写端关闭,读端会读完管道内的数据然后再读,会读到0,表示读道文件结尾
2.命名管道
匿名管道只能解决有 “血缘” 关系的进程之间通信
为解决这一问题,引入命名管道,可以实现没有 “血缘” 关系的进程也可以进行通信,
原理相同,使两个进程看到同一块内存。
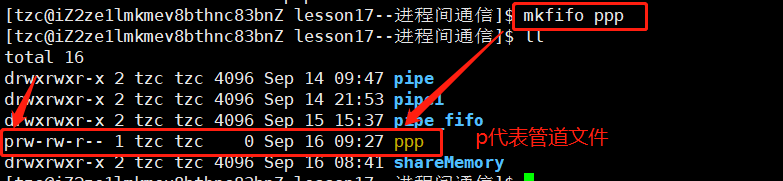
①.创建命名管道
命令行创建
代码创建
umask(0);
if(mkfifo(pipe, 0666) < 0) //创建命名管道
{
//创建失败
perror("mkfifo");
return 1;
}
②.使用命名管道
进程一
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#define MAX 128
//实现两个进程进行相互通信
int main()
{
//1.打开文件 对fifo文件进行只写
int fd1=open("fifo",O_WRONLY);
if(fd1==-1)
{
perror("open");
return 1;
}
printf("已打开一个管道文件\n");
char buf[MAX];
int cnt=5;
//2.写数据
while(cnt)
{
memset(buf,0,MAX);
sprintf(buf,"hello linux %d",cnt--);
int ret=write(fd1,buf,strlen(buf));
printf("write fifo : %d\n",ret);
sleep(1);
}
close(fd1);
return 0;
}
进程二
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#define MAX 128
int main()
{
//1.打开管道
int fd=open("fifo",O_RDONLY);
if(fd==-1)
{
perror("open");
return 1;
}
printf("以读方式打开一个管道\n");
char buf[MAX];
//2.读数据
while(1)
{
memset(buf,0,MAX);
int ret=read(fd,buf,MAX);
if(ret<=0)//读到结尾
{
perror("read");
break;
}
printf("buf:%s\n",buf);
}
//2.关闭文件
close(fd);
return 0;
}
运行两个程序,由此实现了两个进程的通信,如果想要实现相互通信,可以再开一个管道进行操作

三、system V 标准进程间通信
system V:同一主机内的进程间通信方案,在OS层面专门为进程间通信设计的方案
进程间通信的本质:让不同的进程看到同一份资源
system V标准下的三种通信方式 ①共享内存 ②消息队列 ③信号量
1.共享内存
实现原理
1.通过系统调用,在内存中创建一份内存空间
2.通过系统调用,让进程"挂接"到这份新开辟的内存空间上(即在页表上建立虚拟地址与物理地址的映射关系)
3.去关联(挂接)
4.释放共享内存
①常用接口
sheget :申请共享内存
返回值


#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
// key:创建共享内存时的算法和数据结构中唯一标识符,由用户自己设定需用到接口ftok
// size:共享内存的大小,建议是4KB的整数倍
// shmflg:有两个选项:IPC_CREAT(0),创建一个共享内存,如果已经存在则返回共享内存;IPC_EXCL(单独使用没有意义)
// IPC_CREAT|IPC_EXCL(如果调用成功,一定会得到一个全新的共享内存):如果不存在共享内存,就创建;反之,返回出错
// 返回值:shmdi,描述共享内存的标识符
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id); // 算法生成key
// pathname:自定义路径名
// proj_id:自定义项目id
shmctl :控制共享内存
返回值

#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
// shmid:共享内存id
// cmd:控制方式,这里我们只使用IPC_RMID 选项,表示删除共享内存
// buf:描述共享内存的数据结构
关联和去关联共享内存
返回值
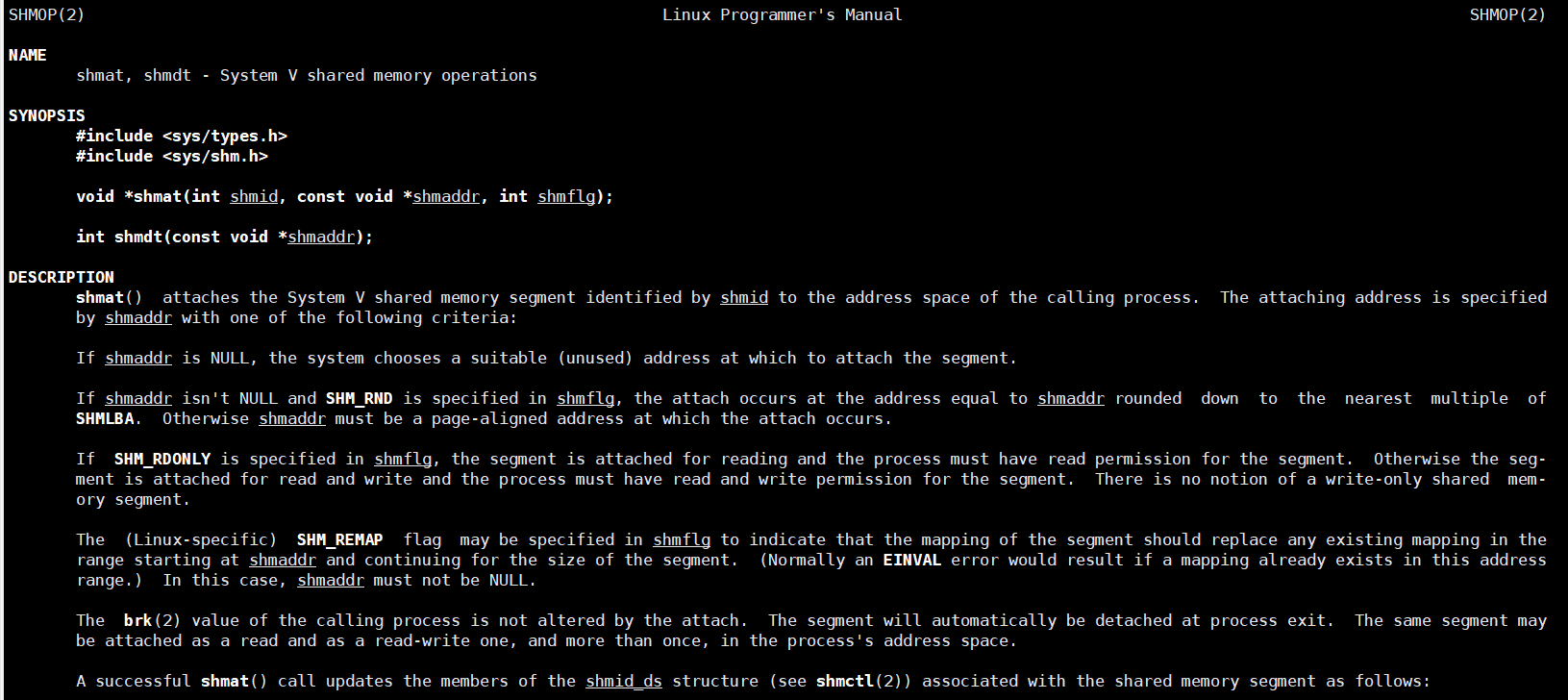

#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg); // 关联
// shmid:共享内存id
// shmaddr:挂接地址(自己不知道地址,所以默认为NULL)
// shmflg:挂接方式,默认为0
// 返回值:挂接成功返回共享内存起始地址(虚拟地址),类似C语言malloc
int shmdt(const void *shmaddr); // 去关联(取消当前进程和共享内存的关系)
// shmaddr:去关联内存地址,即shmat返回值
// 返回值:调用成功返回0,失败返回-1
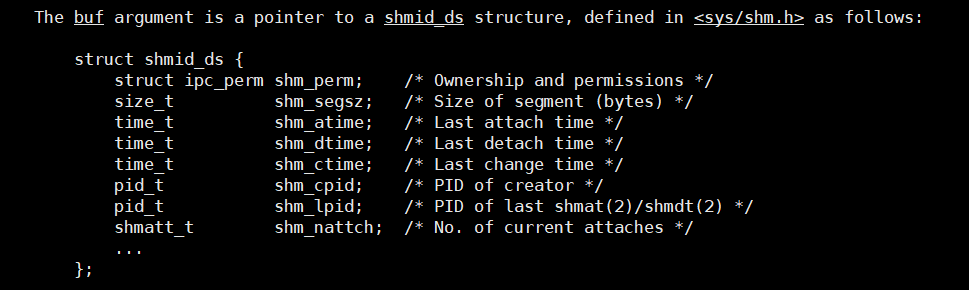
②共享内存的内核数据结构
共享内存是内存,操作系统同时是运行多个进程的,所以操作系统中有多个共享内存同时存在,操作系统如何管理这些内存文件?先描述,后组织,操作系统会定义一个struct shmid_ds的内核数据结构去管理这些打开的贡献内存。
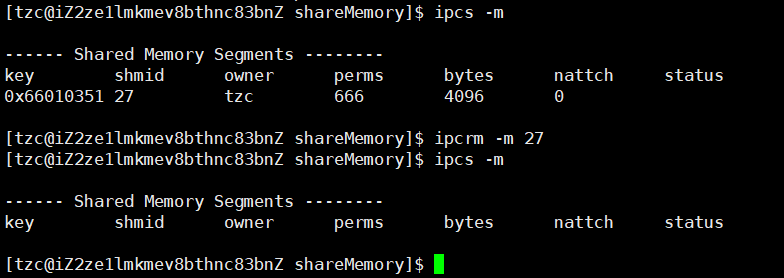
③查看删除共享内存
指令查看共享内存: ipcs -m

system V 的IPC资源,生命周期随内核,只能通过程序员显示释放(或者OS重启)
指令删除共享内存: ipcrm -m shmid
也可使用指令shmctl进行共享内存删除操作
实现一个小demo通过内存共享实现进程间相互通信
comman.hpp
#ifndef __COMM_HPP__
#define __COMM_HPP__
#include<iostream>
#include<cerrno>
#include<cstdio>
#include<cassert>
#include<cstring>
#include<sys/ipc.h>
#include<sys/shm.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<sys/shm.h>
using namespace std;
#define PATHNAME "."
#define PROJID 0x6666
const int gsize=4096;
key_t getKey()
{
key_t k=ftok(PATHNAME,PROJID);
if(k==-1)
{
//失败
cerr<<"error"<<errno<<":"<<strerror(errno)<<endl;
exit(1);
}
return k;
}
string toHex(int x)
{
char buffer[64];
snprintf(buffer,sizeof(buffer),"0x%x",x);
return buffer;
}
static int creatShmHelper(key_t k,int size,int flag)
{
int shmid=shmget(k,size,flag);
if(shmid==-1)
{
// 创建失败
cerr<<"error: "<<errno<<": "<<strerror(errno)<<endl;
exit(2);
}
return shmid;
}
//创建共享内存
//IPC_CREATE
//单独使用IPC_CREATE:创建一个共享内存,如果共享内存不存在,就创建之,如果已经存在,获取已经存在的共享内存并返回
//IPC_EXCL不能单独使用,一般配合IPC_CREATE
//IPC_CREATE | IPC_EXCL :创建一个共享内存,如果不存在,就创建之,如果已经存在,立马出错返回,如果创建成功,返回创建好的共享内存
int creatShm(key_t k,int size)
{
umask(0);
return creatShmHelper(k,size,IPC_CREAT|IPC_EXCL|0666); //设置权限
}
//获取共享内存
int getShm(key_t k,int size)
{
return creatShmHelper(k,size,IPC_CREAT);
}
void delShm(int shmid)
{
int n=shmctl(shmid,IPC_RMID,nullptr);
assert(n!=-1);
(void)n;
}
char* attachShm(int shmid)
{
char* start=(char*)shmat(shmid,nullptr,0);
return start;
}
void detachShm(char* start)
{
int n=shmdt(start);
assert(n!=-1);
(void)n;
}
#endif
shmserver.cc
#include"comman.hpp"
#include<unistd.h>
int main()
{
//1.创建key
key_t k=getKey();
cout<<"server:"<<toHex(k)<<endl;
//2.创建共享内存
int shmid=creatShm(k,gsize);
cout<<"server shmid: "<<shmid<<endl;
//3.将自己和共享内存关联起来
char * start=attachShm(shmid);
//通信代码
int n=0;
while(n<=26)
{
cout<<"client -> server # "<<start<<endl;
n++;
sleep(1);
}
//sleep(3);
//4.将自己和共享内存去关联
detachShm(start);
//删除共享内存
delShm(shmid);
return 0;
}
shmclient.cc
#include"comman.hpp"
#include<unistd.h>
int main()
{
key_t k=getKey();
cout<<"client:"<<toHex(k)<<endl;
int shmid=getShm(k,gsize);
cout<<"client shmid: "<<shmid<<endl;
//3.将自己和共享内存关联起来
char * start=attachShm(shmid);
char c='A';
while(c<='Z')
{
start[c-'A']=c;
c++;
start[c]='\0';
sleep(1);
}
//4.将自己和共享内存去关联
detachShm(start);
sleep(5);
return 0;
}
实现效果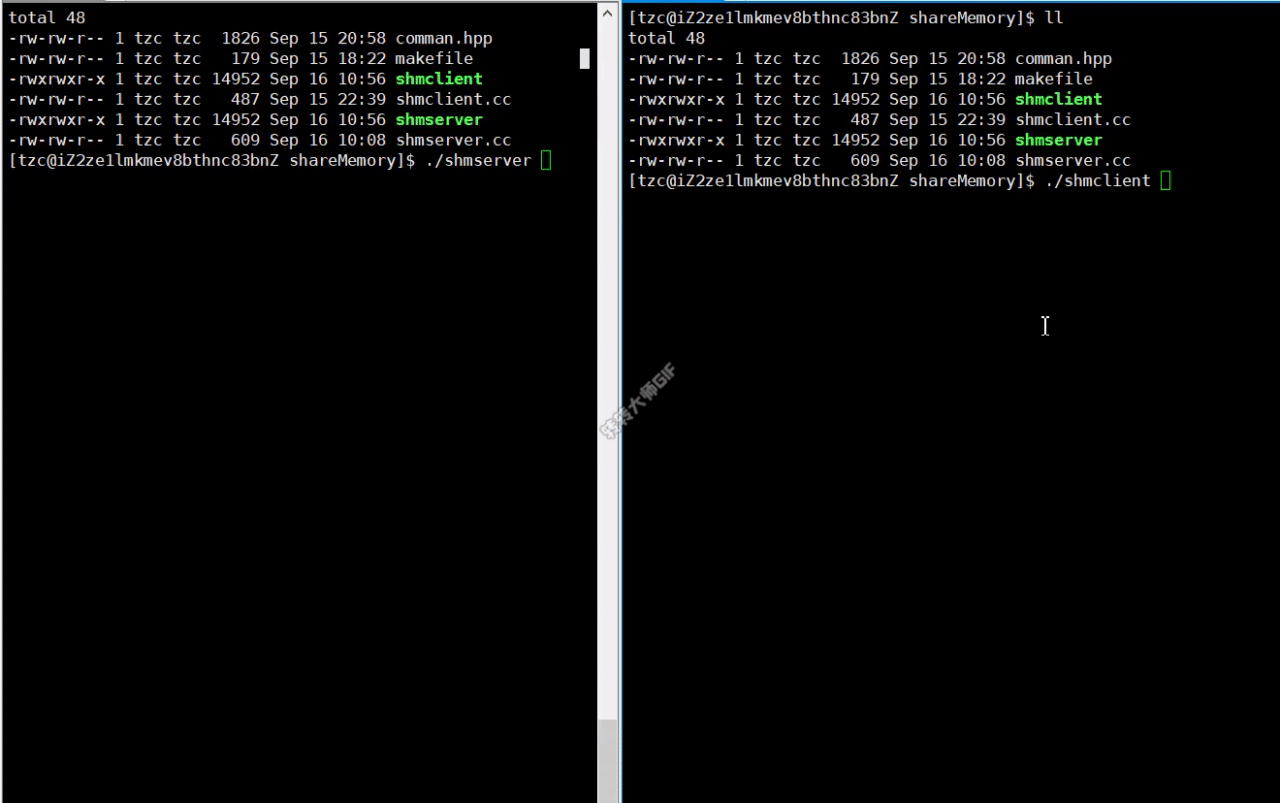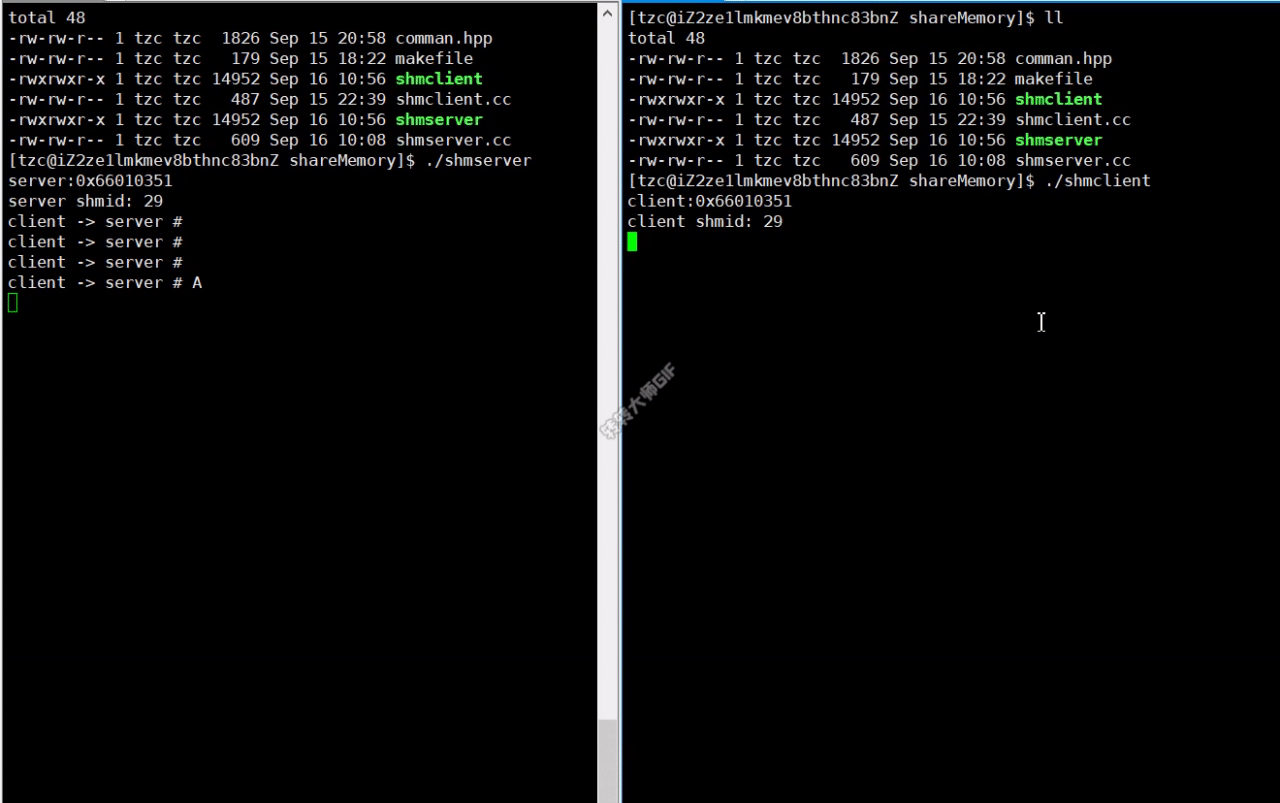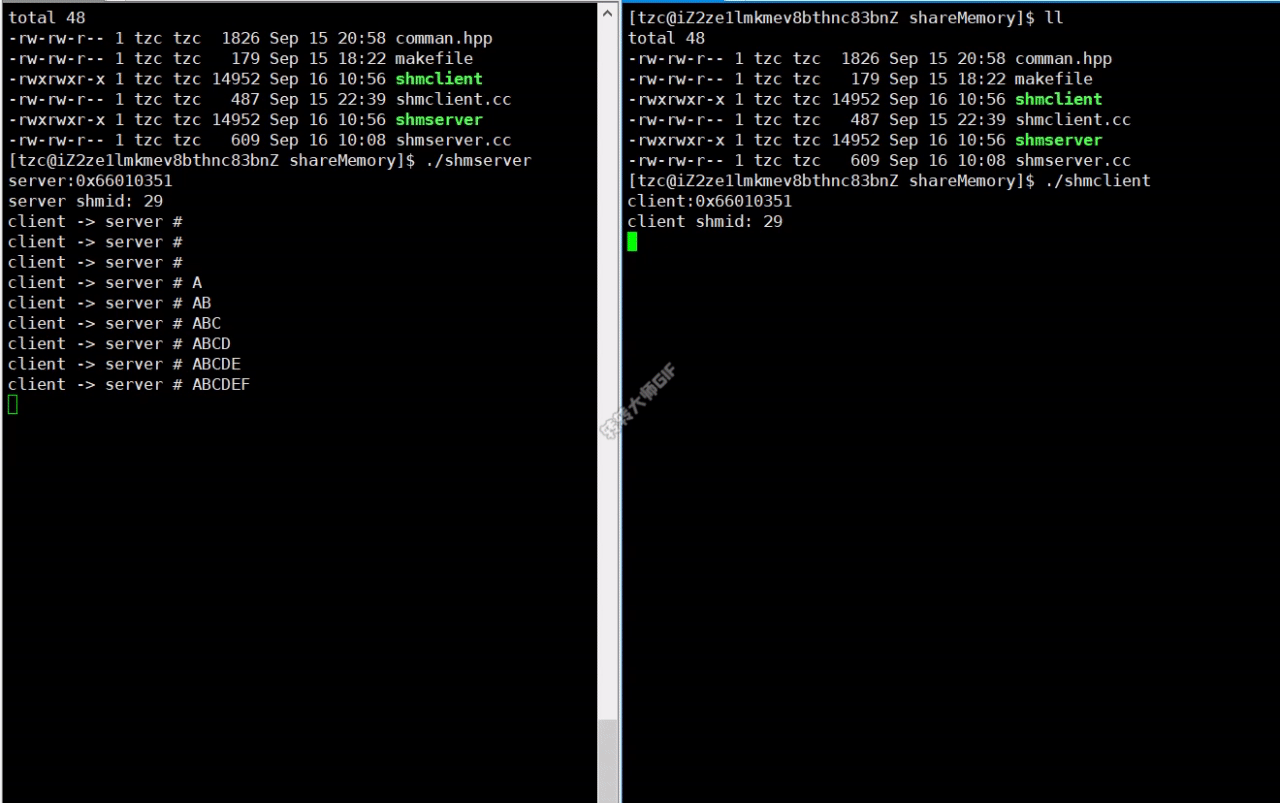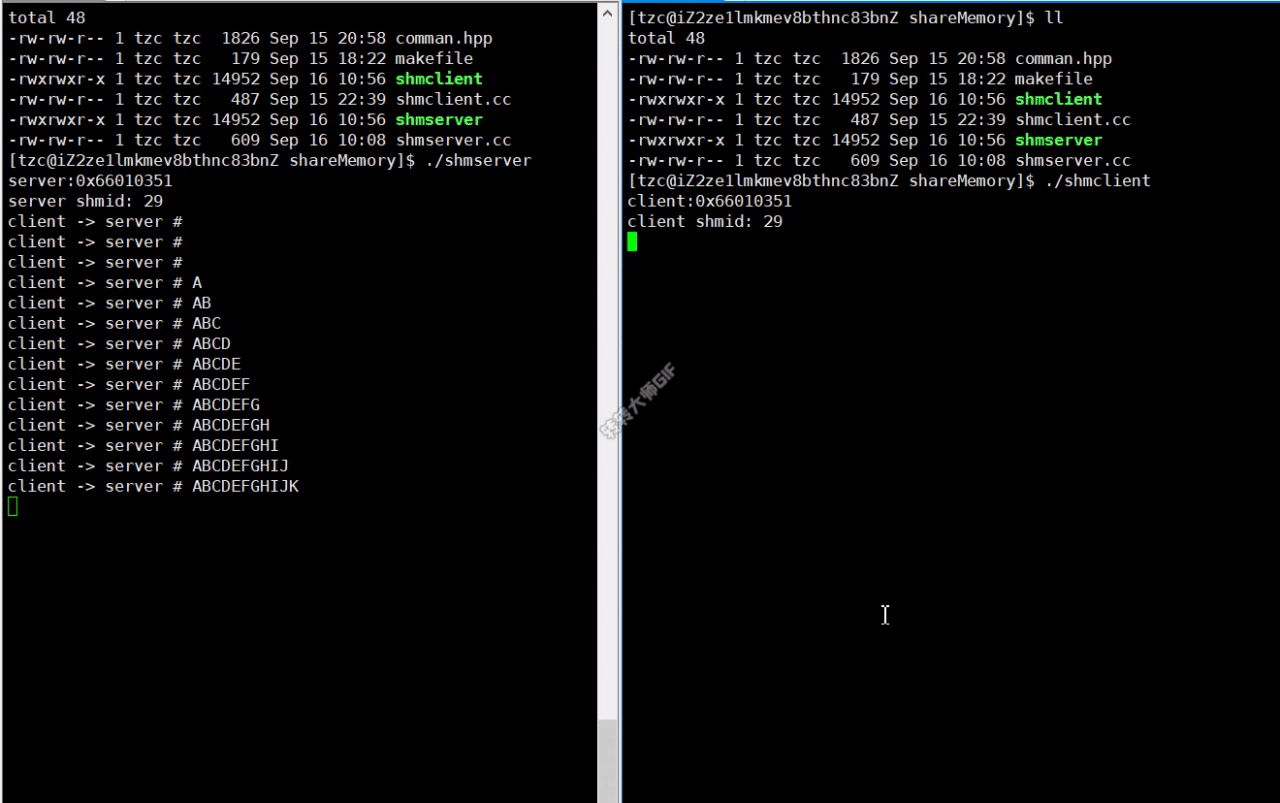
使用共享内存进行通信时,不需要使用read和write 接口。
共享内存是所有进程间通信中速度最快的。
共享内存不提供任何同步或互斥机制,需要程序员自行保证数据安全。
ps: 共享内存在内核中的申请的基本单位是页,内存页的大小为4KB,如果申请4097个字节,内核会分配8KB空间,但实际给使用的内存还是4097个字节。









