Kubernetes 支持多个虚拟集群,底层依赖于同一个物理集群。 这些虚拟集群被称为名称空间。名称空间namespace是k8s集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的名称空间,例如,可以为test、dev、prod环境分别创建各自的命名空间。
当多个用户或团队共享具有固定节点数目的集群时,人们会担心有人使用超过其基于公平原则所分配到的资源量。资源配额是帮助管理员解决这一问题的工具。
资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。
资源配额的工作方式如下:
-
不同的团队可以在不同的命名空间下工作。这可以通过 RBAC 强制执行。
-
集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
-
当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况, 以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
-
如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
-
如果命名空间下的计算资源 (如
cpu和memory)的配额被启用, 则用户必须为这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
下面介绍下怎么给k8s集群中的名称空间做资源配额限制。
查看名称空间:
# kubectl get ns
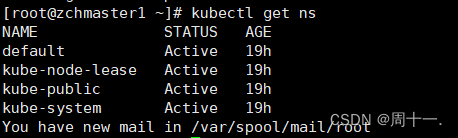
k8s 默认有以上四个名称空间
创建一个test名称空间
# kubectl create ns test
如何对namespace资源做限额呢?
查看帮助命令:
# kubectl explain quota
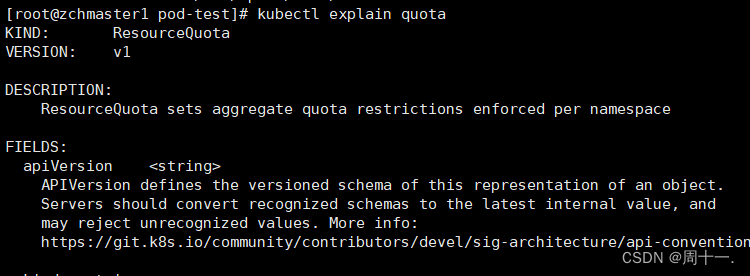
参数介绍:
| 资源名称 | 描述 |
|---|---|
limits.cpu | 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 |
limits.memory | 所有非终止状态的 Pod,其内存限额总量不能超过该值。 |
requests.cpu | 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 |
requests.memory | 所有非终止状态的 Pod,其内存需求总量不能超过该值。 |
hugepages-<size> | 对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 |
cpu | 与 requests.cpu 相同。 |
memory | 与 requests.memory 相同。 |
下面我们给test这个名称空间创建一个资源配额限制
# vi namespace-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
namespace: test
spec:
hard:
requests.cpu: "2"
requests.memory: 2Gi
limits.cpu: "4"
limits.memory: 4Gi说明:每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu请求(cpu request)和cpu限额(cpu limit)。
所有容器的内存请求总额不得超过2GiB。
所有容器的CPU请求总额不得超过2 CPU。
所有容器的内存限额总额不得超过4 GiB。
所有容器的CPU限额总额不得超过4CPU
执行资源文件:
# kubectl apply -f namespace-quota.yaml
![]()
查看test 名称空间下的资源配额信息,验证是否执行成功:
# kubectl describe ns test

如上所示 test名称空间 已经加上的配额限制信息,下面我们在test名称空间下创建POD,验证是否可以限制成功。
编辑资源文件:
# vi pod-test-quota2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-test-quota
namespace: test
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat-test
ports:
- containerPort: 8080
image: docker.io/library/tomcat:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "10Gi"
cpu: "5"
limits:
memory: "20Gi"
cpu: "10"很明显,当前我们所创建的POD 配置的Resources资源,已经大于前面我们对test名称空间的限制。
执行以下,看看
# kubectl apply -f pod-test-quota2.yaml
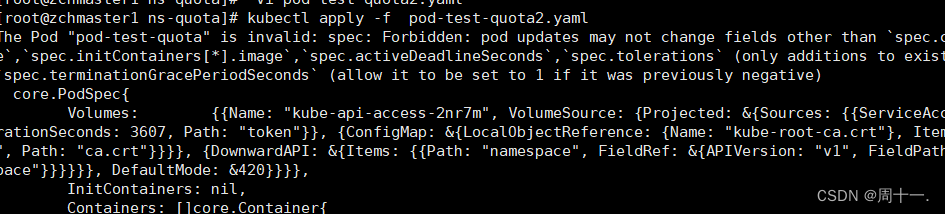
如上,创建不成功
再次编辑资源文件:
# vi pod-test-quota2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-test-quota
namespace: test
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat-test
ports:
- containerPort: 8080
image: docker.io/library/tomcat:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "200Mi"
cpu: "100m"
limits:
memory: "2Gi"
cpu: "2"再次执行资源文件:
# kubectl apply -f pod-test-quota2.yaml

说明我们的名称空间资源配额限制是生效的









