0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 python图像检索系统设计与实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1 课题简介
图像检索:是从一堆图片中找到与待匹配的图像相似的图片,就是以图找图。 网络时代,随着各种社交网络的兴起,网络中图片,视频数据每天都以惊人的速度增长,逐渐形成强大的图像检索数据库。针对这些具有丰富信息的海量图片,如何有效地从巨大的图像数据库中检索出用户需要的图片,成为信息检索领域研究者感兴趣的一个研究方向。2 图像检索介绍
给定一个包含特定实例(例如特定目标、场景、建筑等)的查询图像,图像检索旨在从数据库图像中找到包含相同实例的图像。但由于不同图像的拍摄视角、光照、或遮挡情况不同,如何设计出能应对这些类内差异的有效且高效的图像检索算法仍是一项研究难题。
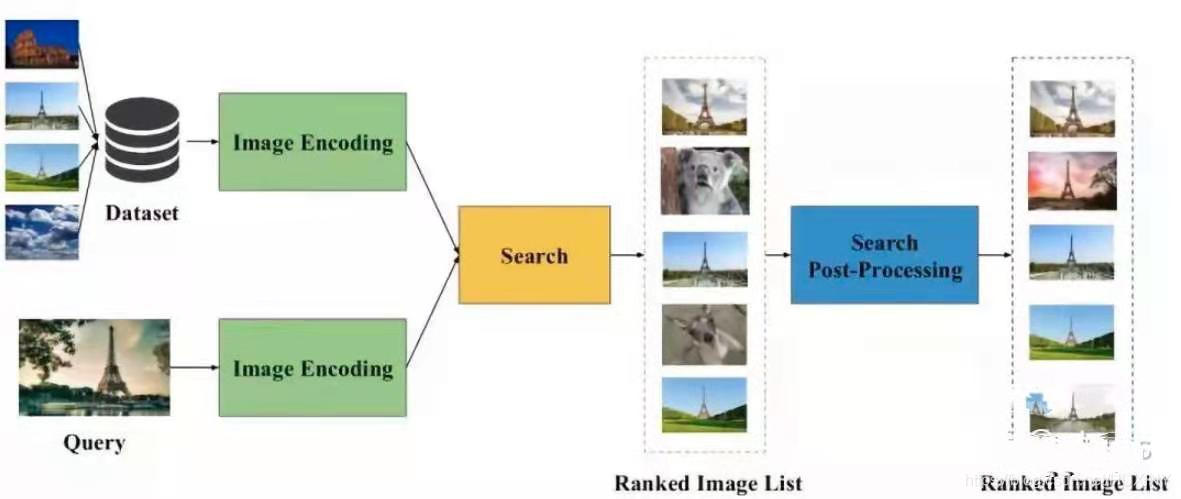
图像检索的典型流程 首先,设法从图像中提取一个合适的图像的表示向量。其次,对这些表示向量用欧式距离或余弦距离进行最近邻搜索以找到相似的图像。最后,可以使用一些后处理技术对检索结果进行微调。可以看出,决定一个图像检索算法性能的关键在于提取的图像表示的好坏。
(1) 无监督图像检索
无监督图像检索旨在不借助其他监督信息,只利用ImageNet预训练模型作为固定的特征提取器来提取图像表示。
直觉思路 由于深度全连接特征提供了对图像内容高层级的描述,且是“天然”的向量形式,一个直觉的思路是直接提取深度全连接特征作为图像的表示向量。但是,由于全连接特征旨在进行图像分类,缺乏对图像细节的描述,该思路的检索准确率一般。
利用深度卷积特征 由于深度卷积特征具有更好的细节信息,并且可以处理任意大小的图像输入,目前的主流方法是提取深度卷积特征,并通过加权全局求和汇合(sum-pooling)得到图像的表示向量。其中,权重体现了不同位置特征的重要性,可以有空间方向权重和通道方向权重两种形式。
CroW 深度卷积特征是一个分布式的表示。虽然一个神经元的响应值对判断对应区域是否包含目标用处不大,但如果多个神经元同时有很大的响应值,那么该区域很有可能包含该目标。因此,CroW把特征图沿通道方向相加,得到一张二维聚合图,并将其归一化并根号规范化的结果作为空间权重。CroW的通道权重根据特征图的稀疏性定义,其类似于自然语言处理中TF-IDF特征中的IDF特征,用于提升不常出现但具有判别能力的特征。
Class weighted features 该方法试图结合网络的类别预测信息来使空间权重更具判别能力。具体来说,其利用CAM来获取预训练网络中对应各类别的最具代表性区域的语义信息,进而将归一化的CAM结果作为空间权重。
PWA PWA发现,深度卷积特征的不同通道对应于目标不同部位的响应。因此,PWA选取一系列有判别能力的特征图,将其归一化之后的结果作为空间权重进行汇合,并将其结果级联起来作为最终图像表示。
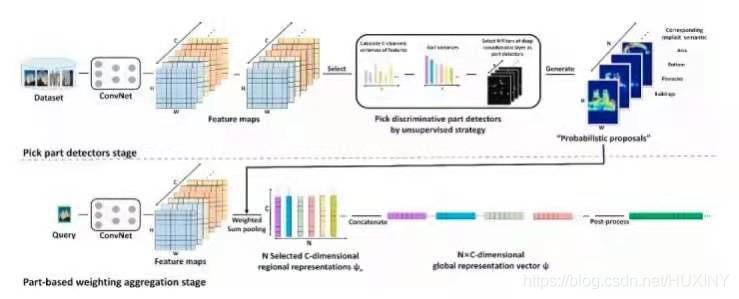
(2) 有监督图像检索
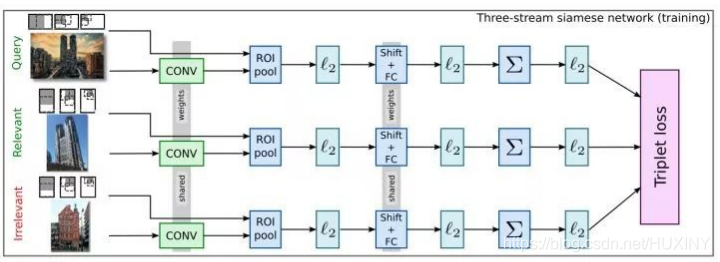
有监督图像检索首先将ImageNet预训练模型在一个额外的训练数据集上进行微调,之后再从这个微调过的模型中提取图像表示。为了取得更好的效果,用于微调的训练数据集通常和要用于检索的数据集比较相似。此外,可以用候选区域网络提取图像中可能包含目标的前景区域。
孪生网络(siamese network) 和人脸识别的思路类似,使用二元或三元(+±)输入,训练模型使相似样本之间的距离尽可能小,而不相似样本之间的距离尽可能大。
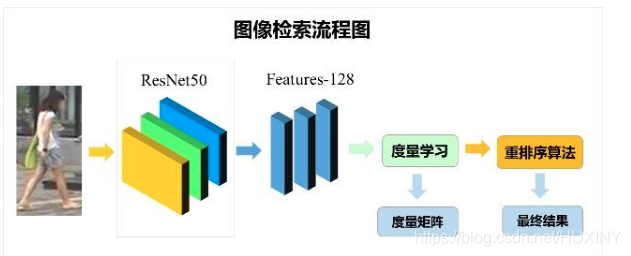
3 图像检索步骤
图像检索技术主要包含几个步骤,分别为:
-
输入图片
-
特征提取
-
度量学习
-
重排序
-
特征提取:即将图片数据进行降维,提取数据的判别性信息,一般将一张图片降维为一个向量;
-
度量学习:一般利用度量函数,计算图片特征之间的距离,作为loss,训练特征提取网络,使得相似图片提取的特征相似,不同类的图片提取的特征差异性较大。
-
重排序:利用数据间的流形关系,对度量结果进行重新排序,从而得到更好的检索结果。
4 应用实例
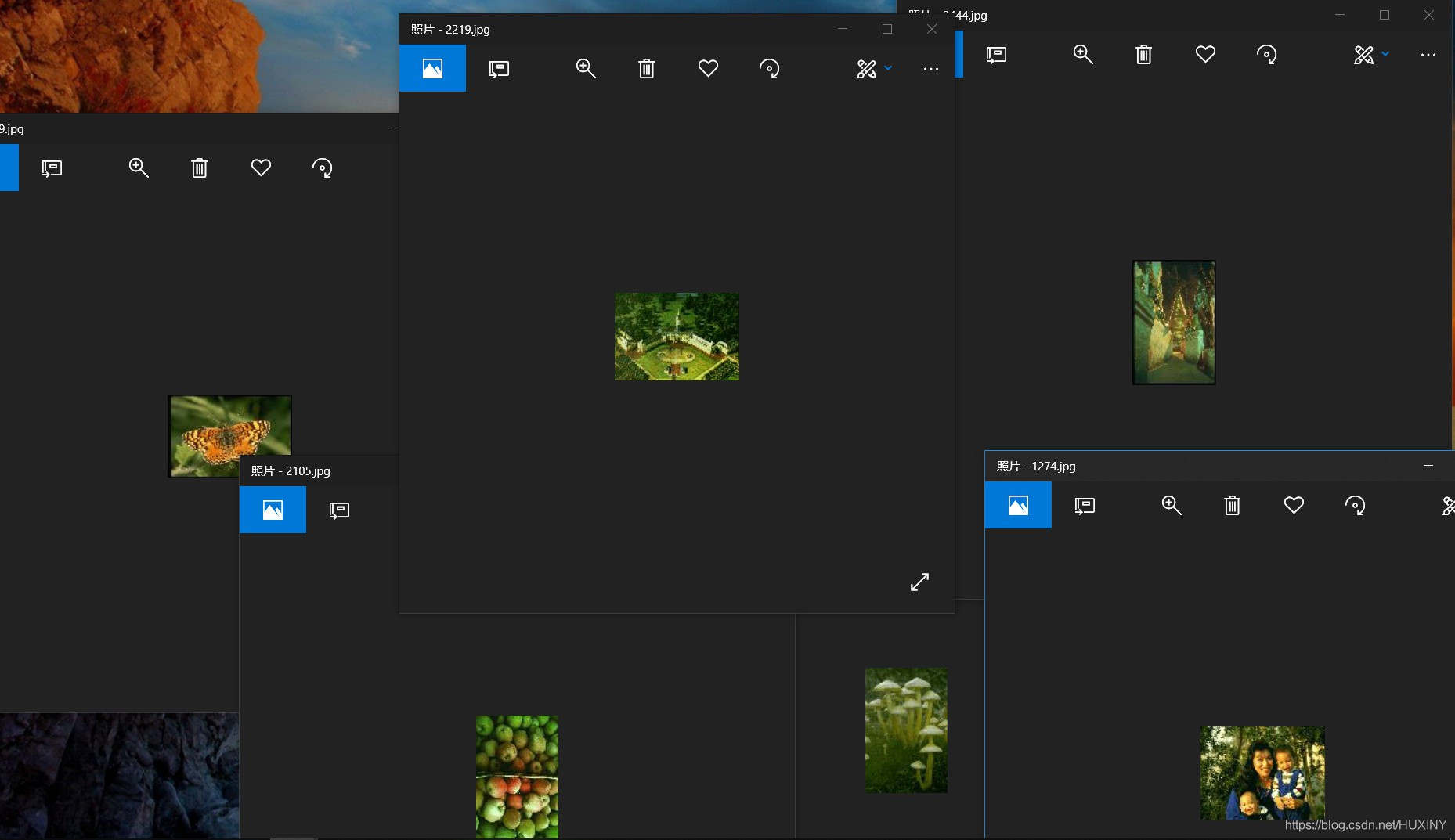
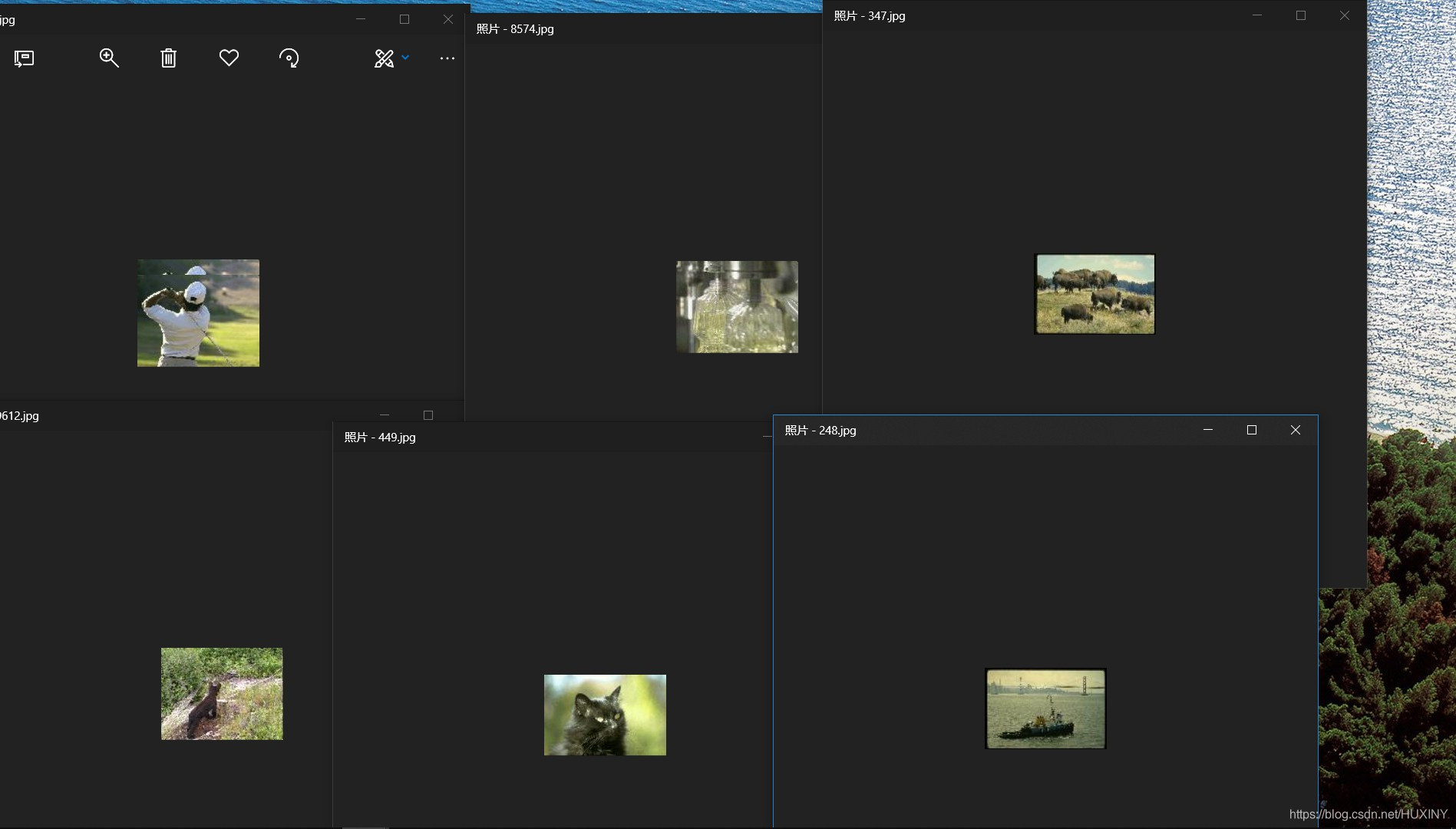
学长在这做了个图像检索器的demo,效果如下
工程代码:

关键代码:
# _*_ coding=utf-8 _*_
from math import sqrt
import cv2
import time
import os
import numpy as np
from scipy.stats.stats import pearsonr
#配置项文件
import pymysql
from config import *
from mysql_config import *
from utils import getColorVec, Bdistance
db = pymysql.connect(DB_addr, DB_user, DB_passwod, DB_name )
def query(filename):
if filename=="":
fileToProcess=input("输入子文件夹中图片的文件名")
else:
fileToProcess=filename
#fileToProcess="45.jpg"
if(not os.path.exists(FOLDER+fileToProcess)):
raise RuntimeError("文件不存在")
start_time=time.time()
img=cv2.imread(FOLDER+fileToProcess)
colorVec1=getColorVec(img)
#流式游标处理
conn = pymysql.connect(host=DB_addr, user=DB_user, passwd=DB_passwod, db=DB_name, port=3306,
charset='utf8', cursorclass = pymysql.cursors.SSCursor)
leastNearRInFive=0
Rlist=[]
namelist=[]
init_str="k"
for one in range(0, MATCH_ITEM_NUM):
Rlist.append(0)
namelist.append(init_str)
with conn.cursor() as cursor:
cursor.execute("select name, featureValue from "+TABLE_NAME+" order by name")
row=cursor.fetchone()
count=1
while row is not None:
if row[0] == fileToProcess:
row=cursor.fetchone()
continue
colorVec2=row[1].split(',')
colorVec2=list(map(eval, colorVec2))
R2=pearsonr(colorVec1, colorVec2)
rela=R2[0]
#R2=Bdistance(colorVec1, colorVec2)
#rela=R2
#忽略正负性
#if abs(rela)>abs(leastNearRInFive):
#考虑正负
if rela>leastNearRInFive:
index=0
for one in Rlist:
if rela >one:
Rlist.insert(index, rela)
Rlist.pop(MATCH_ITEM_NUM)
namelist.insert(index, row[0])
namelist.pop(MATCH_ITEM_NUM)
leastNearRInFive=Rlist[MATCH_ITEM_NUM-1]
break
index+=1
count+=1
row=cursor.fetchone()
end_time=time.time()
time_cost=end_time-start_time
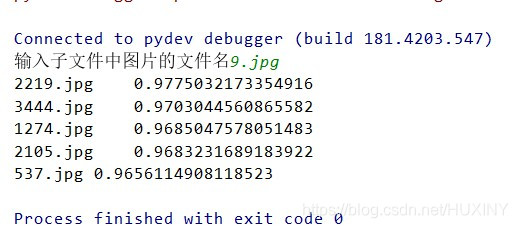
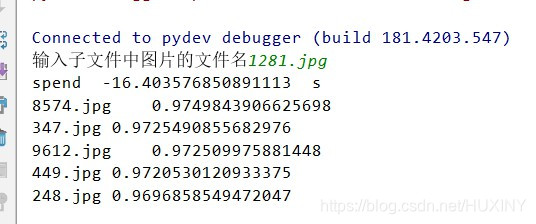
print("spend ", time_cost, ' s')
for one in range(0, MATCH_ITEM_NUM):
print(namelist[one]+"\t\t"+str(float(Rlist[one])))
if __name__ == '__main__':
#WriteDb()
#exit()
query("")
效果