1、数据
电动汽车的充电数据形式如下
| 订单号 | 充电开始时间 | 充电完成时间 | 订单/时段总充电量(KWh) | 尖时电量 | 峰时电量 | 平时电量 | 谷时电量 |
| 202302010500002612 | 2023-02-01 00:03:26 | 2023-02-01 00:40:52 | 28.441 | 0.000 | 0.000 | 0.000 | 28.441 |
| 202302010500004570 | 2023-02-01 00:10:28 | 2023-02-01 01:01:35 | 45.319 | 0.000 | 0.000 | 0.000 | 45.319 |
| 202302010500004728 | 2023-02-01 00:10:32 | 2023-02-01 01:27:13 | 57.312 | 0.000 | 0.000 | 0.000 | 57.312 |
| 202302010500004959 | 2023-02-01 00:11:32 | 2023-02-01 01:16:45 | 25.492 | 0.000 | 0.000 | 0.000 | 25.492 |
| 202302010500006969 | 2023-02-01 00:22:59 | 2023-02-01 01:36:38 | 44.889 | 0.000 | 0.000 | 0.000 | 44.889 |
| 202302010500007076 | 2023-02-01 00:24:13 | 2023-02-01 00:40:53 | 9.131 | 0.000 | 0.000 | 0.000 | 9.131 |
| 202302010500007082 | 2023-02-01 00:24:35 | 2023-02-01 00:40:51 | 8.187 | 0.000 | 0.000 | 0.000 | 8.187 |
| 202302010500007865 | 2023-02-01 00:29:27 | 2023-02-01 01:31:39 | 33.894 | 0.000 | 0.000 | 0.000 | 33.894 |
| 202302010500008663 | 2023-02-01 00:35:20 | 2023-02-01 01:20:31 | 28.240 | 0.000 | 0.000 | 0.000 | 28.240 |
| 202302010500008755 | 2023-02-01 00:35:50 | 2023-02-01 01:32:04 | 31.752 | 0.000 | 0.000 | 0.000 | 31.752 |
2、目标任务
以5分钟为一个时段,需要知道每天每个时段的总充电量,最终结果如下所示
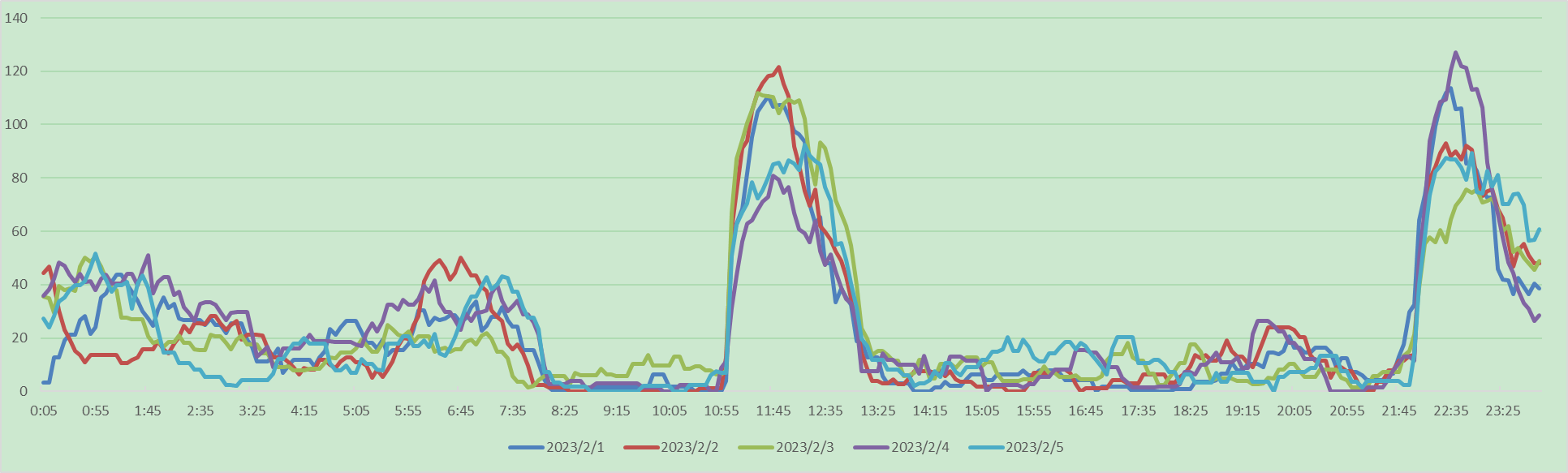
3、数据处理
Python代码在《excel_pandas.py》中,具体如下
import pandas as pd
import time
import os
start_time = time.time() # 开始计时
carDF = pd.read_excel(io='./carChageTime.xlsx')# 读取xlsx(相对路径)
# 将时间字符串转换为时间戳
carDF['start_time'] = pd.to_datetime(carDF['充电开始时间'])
carDF['end_time'] = pd.to_datetime(carDF['充电完成时间'])
# 建立空表,以5分钟为间隔
start_index_time = pd.to_datetime('2023-02-01')
end_index_time = pd.to_datetime('2023-07-31')
power_index = pd.date_range(start=start_index_time, end=end_index_time, freq='5min')
power_excel = pd.DataFrame(data=0, columns=['power'], index=power_index)
pass
start_index_bill = 0
end_index_bill = 52000
for index in range(start_index_bill, end_index_bill): # 260
print(start_index_bill, '/', index, '/', end_index_bill)
count = 0
num_5minutes = (carDF['end_time'][index] - carDF['start_time'][index]) // pd.Timedelta("5T")
if num_5minutes == 0: # 0不能做除数
power_average = carDF['订单/时段总充电量(KWh)'][index] # 将每一个订单的总电量均分
# print('num_5minutes=0', 'index=', index, 'power=', power_average)
# print(carDF['start_time'][index], carDF['end_time'][index])
for x in power_index:
if carDF['start_time'][index] <= x:
power_excel.loc[x] = power_excel.loc[x] + power_average
break
else:
power_average = carDF['订单/时段总充电量(KWh)'][index] / num_5minutes
for x in power_index:
if carDF['start_time'][index] <= x <= carDF['end_time'][index]:
count = count + 1
if count > num_5minutes:
break
else:
power_excel.loc[x] = power_excel.loc[x] + power_average
pass
# 保存结果
realTime = time.strftime('%Y%m%d%H%M%S', time.localtime())
file_name = os.path.basename(__file__)[0:-3]
power_excel.to_csv('{0}_{1}_{2}_{3}.csv'.format(file_name, realTime, start_index_bill, end_index_bill))
# 打印程序的运行时间
end_time = time.time()
print("end_time-start_time={}".format(end_time - start_time))
最终生成一个《excel_pandas_slice_20230918194213_0_52000.csv》,内容如下

4、进一步处理
Python代码在《csv_to_excel.py》中,具体如下
import pandas as pd
import time
import os
start_time = time.time() # 开始计时
df_RNN = pd.read_csv('excel_pandas_slice_20230918194213_0_52000.csv') # 读取xlsx(相对路径)
# 行名
start_index_time = pd.to_datetime('2023-02-01 00:05:00') # Timestamp('2023-02-01 00:00:00')
end_index_time = pd.to_datetime('2023-02-02 00:00:00') # Timestamp('2023-07-31 00:00:00')
power_index = pd.date_range(start=start_index_time, end=end_index_time, freq='5min')
# 列名
start_column_time = pd.to_datetime('2023-02-01') # Timestamp('2023-02-01 00:00:00')
end_column_time = pd.to_datetime('2023-7-31') # Timestamp('2023-07-31 00:00:00')
power_column = pd.date_range(start=start_column_time, end=end_column_time, freq='D')
power_excel = pd.DataFrame(data=0, columns=power_column, index=power_index)
# num_5minutes用于记录一天被划分为了多少个时间段
# 这里以5分钟为一个时间段,所以num_5minutes=288
t_step = pd.Timedelta("5T") # 时间间隔5minutes
num_5minutes = (end_index_time - start_index_time) // t_step + 1 # 288
pass
for i in range(df_RNN.shape[0] // num_5minutes):
power_excel.loc[:, power_column[i]] = list(df_RNN['power'][i * num_5minutes:(i + 1) * num_5minutes])
# 保存结果
realTime = time.strftime('%Y%m%d%H%M%S', time.localtime())
file_name = os.path.basename(__file__)[0:-3]
power_excel.to_excel('{0}_{1}.xlsx'.format(file_name, realTime))
# 打印程序的运行时间
end_time = time.time()
print("end_time-start_time={}".format(end_time - start_time))
最终生成一个《excel_to_csv_20230918203118.xlsx》,内容如下

这里在excel对《excel_to_csv_20230918203118.xlsx》的索引进行了设置单元格式处理

5、绘图
 绘图参考
绘图参考
EXCEL如何在一个图上画多条曲线-百度经验 (baidu.com)
参考另一篇博客









