
目录
2.1.4 创建hive的外部表(需要添加external和location的关键字)
一、数据库的基本操作
1.1 展示所有数据库
show databases;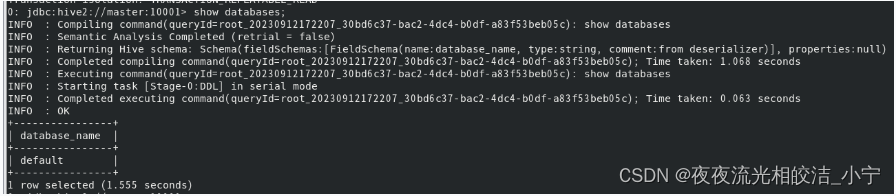
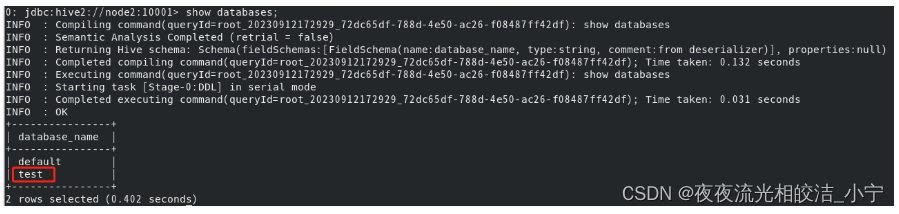
1.2 切换数据库
use database_name;提示:database_name 指的我们真实存在的数据库名称。
例子:use test;
1.3 创建数据库
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];例子:
create database test;
注意:当进入hive的命令行开始编写SQL语句的时候,如果没有任何相关的数据库操作,那么默认情况下,所有的表存在于default数据库,在hdfs上的展示形式是将此数据库的表保存在hive的默认路径下,如果创建了数据库,那么会在hive的默认路径下生成一个database_name.db的文件夹,此数据库的所有表会保存在database_name.db的目录下。
1.4 删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];例子:
drop database test;

1.5 显示数据库信息
1.5.1 显示数据库信息
语法:desc database database_name;
例子:desc databse test;

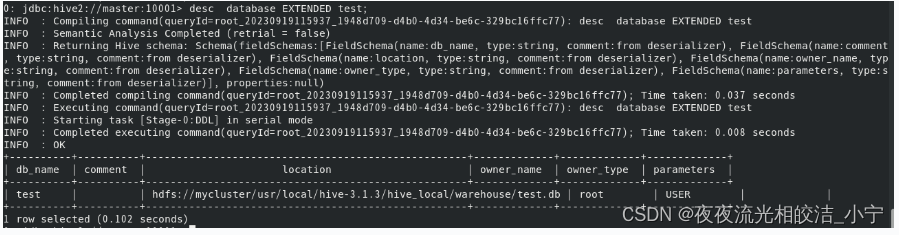
1.5.2 显示数据库详情
语法:desc database EXTENDED database_name;
例子:desc databse EXTENDED test;
二、数据库表的基本操作
2.1 创建表的操作
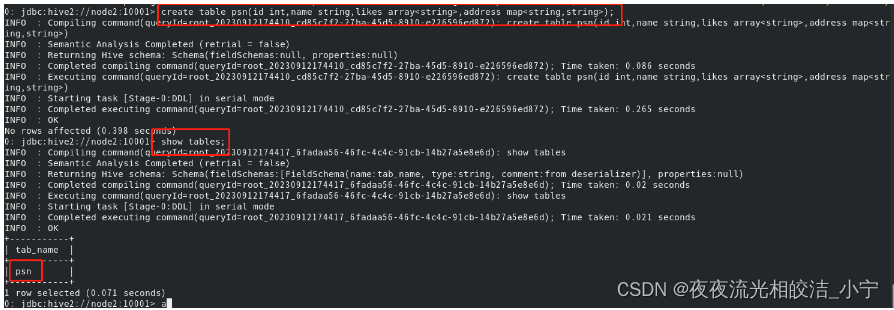
2.1.1 创建普通hive表(不包含行定义格式)
create table psn
(
id int,
name string,
likes array<string>,
address map<string,string>
)
2.1.2 创建自定义行格式的hive表
create table psn2
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';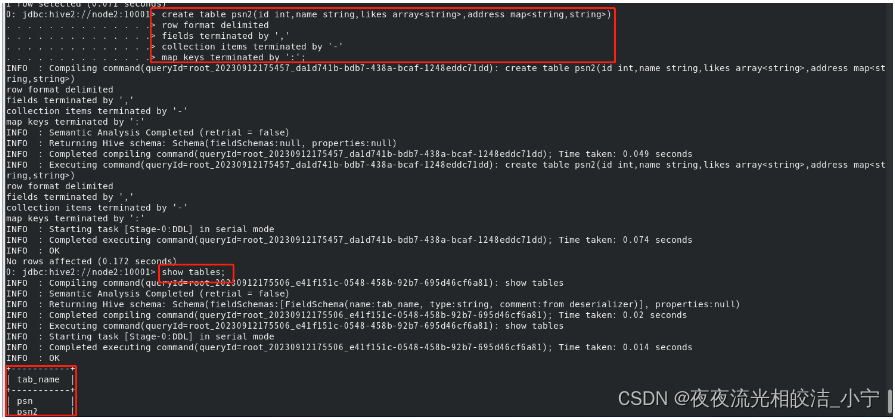
2.1.3 创建默认分隔符的hive表(^A、^B、^C)
create table psn3
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003';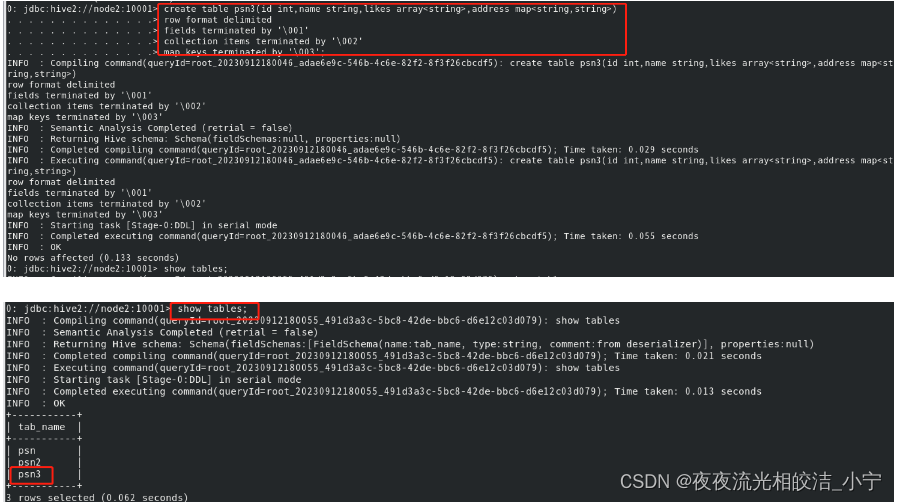
2.1.4 创建hive的外部表(需要添加external和location的关键字)
create external table psn4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/data';
在之前创建的表都属于hive的内部表(psn,psn2,psn3),而psn4属于hive的外部表,
内部表跟外部表的区别:
1、hive内部表创建的时候数据存储在hive的默认存储目录中,外部表在创建的时候需要制定额外的目录
2、hive内部表删除的时候,会将元数据和数据都删除,而外部表只会删除元数据,不会删除数据
应用场景:
内部表:需要先创建表,然后向表中添加数据,适合做中间表的存储
外部表:可以先创建表,再添加数据,也可以先有数据,再创建表,本质上是将hdfs的某一个目录的数据跟 hive的表关联映射起来,因此适合原始数据的存储,不会因为误操作将数据给删除掉
2.1.5 创建单分区表
create table psn5(id int,name string,likes array<string>,address map<string,string>)
partitioned by(gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
2.1.6 创建多分区表
create table psn6
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
注意:
1、当创建完分区表之后,在保存数据的时候,会在hdfs目录中看到分区列会成为一个目录,以多级目录的形式存在
2、当创建多分区表之后,插入数据的时候不可以只添加一个分区列,需要将所有的分区列都添加值
3、多分区表在添加分区列的值得时候,与顺序无关,与分区表的分区列的名称相关,按照名称就行匹配
2.1.7 给分区表添加分区列的值
alter table table_name add partition(col_name=col_value)2.1.8 删除分区列的值
alter table table_name drop partition(col_name=col_value)注意:
1、添加分区列的值的时候,如果定义的是多分区表,那么必须给所有的分区列都赋值
2、删除分区列的值的时候,无论是单分区表还是多分区表,都可以将指定的分区进行删除
2.1.9 修复分区
在使用hive外部表的时候,可以先将数据上传到hdfs的某一个目录中,然后再创建外部表建立映射关系,如果在上传数据的时候,参考分区表的形式也创建了多级目录,那么此时创建完表之后,是查询不到数据的,原因是分区的元数据没有保存在mysql中,因此需要修复分区,将元数据同步更新到mysql中,此时才可以查询到元数据.
2.1.9.1 在hdfs创建目录并上传文件
hdfs dfs -mkdir /ning
hdfs dfs -mkdir /ning/age=10
hdfs dfs -mkdir /ning/age=20
hdfs dfs -put /root/data/data /ning/age=10
hdfs dfs -put /root/data/data /ning/age=202.1.9.2 创建外部表
create external table psn11
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/ning';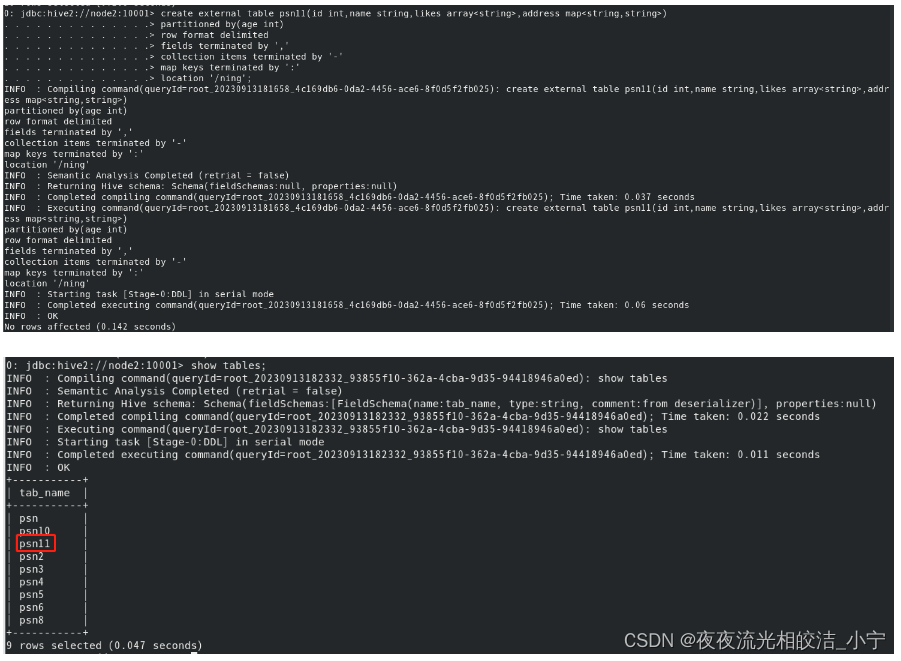
2.1.9.3 查询结果(没有数据)
select * from psn11;
2.1.9.4 修复分区
msck repair table psn11;2.1.9.5 再查询结果(有数据)
select * from psn11;
2.2 查看表的操作
2.2.1 查看表结构
desc formatted psn19;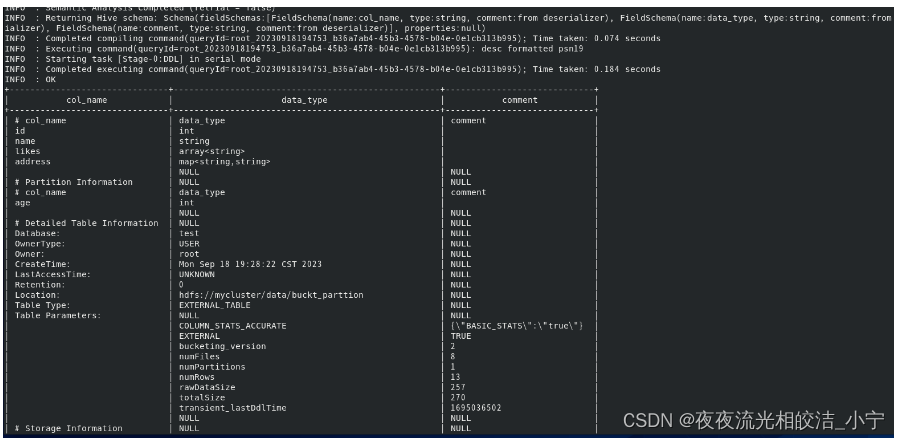
2.2.2 查看表分区
show partitions psn19;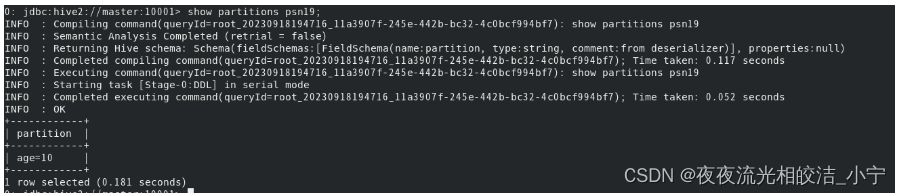
2.2.3 查看表详细结构
desc formatted psn19;
desc extended psn19;
2.2.4 查看表的类型
desc formatted psn19;
2.2.5 查看建表信息
show create table psn11;
2.3 修改表的操作
2.3.1 修改内部表为外部表
语法:alter table table_name set TBLPROPERTIES('EXTERNAL'='true');
例子:
alter table psn3 set TBLPROPERTIES('EXTERNAL'='true');

查询下表结构,看下表的类型:
desc formatted psn3;
表的类型变成了EXTERNAL_TABLE,变成了外部表(EXTERNAL_TABLE 是外部表,MANAGED_TABLE是内部表)。
2.3.2 修改表名
语法:alter table table_name RENAME to new_table;
例子:
alter table psn3 rename to new_psn3;
通过查看数据库中的表,我们发现表psn3成功修改为表new_psn3。
2.3.3 更新列
语法:alter table table_name CHANGE COLUMN col_old_name col_new_name column_type;
例子:
# 我们把new_psn3这张表中的name字段修改成new_name字段,类型是string类型。
alter table new_psn3 change column name new_name string;
通过查看表结构,我们发现原本的name字段,已经成功修改成了new_name字段,且类型是string 类型。
2.3.4 新增或替换列
语法:alter table table_name ADD|REPLACE COLUMNS (col_name data_type.........);
新增列例子:
#我们往new_psn3这张表中新增一个列,叫age,类型int 类型。
alter table new_psn3 add columns(age int);
替换列例子:
#我们将new_psn3这张表中的字段进行替换。
alter table new_psn3 replace columns(id int,name string,likes array<string>,address map<string,string>);
通过查看表,我们知道,表中的字段,被我们成功替换了。
2.3.5 修改列名、列类型、注释
语法:alter table table_name change old_column_name new_column_name new_column_type comment '注释';
例子:
#我们将new_psn3 中的name 修改成new_name,类型还是string ,添加注释“名称”
alter table new_psn3 change name new_name string comment '名称';2.4 删除表的操作
2.4.1 Drop删除
语法:`DROP TABLE [IF EXISTS] table_name;`
例子:
drop table if existt psn2;提示:使用drop命令删除普通表,hdfs的数据和hive中的元数据会被删除,但是删除外部表时,只会删除元数据,不会删除hdfs中的数据。
2.4.2 Truncate 删除
语法:
`TRUNCATE [TABLE] table_name [PARTITION partition_spec];`
`partition_spec:` (partition_column = partition_col_value, partition_column = partition_col_value, ...)例子:
在删除之前,我看下我的psn20表存储的数据:

可以看多,psn20有两个分区,分别是age=10,age=20.
#删除表中指定分区数据
truncate table psn20 partition(age=10);删除age=10这个分区后,我们发现psn20这个表只剩下age=20的分区数据。

# 删除所有分区数据
truncate table psn20;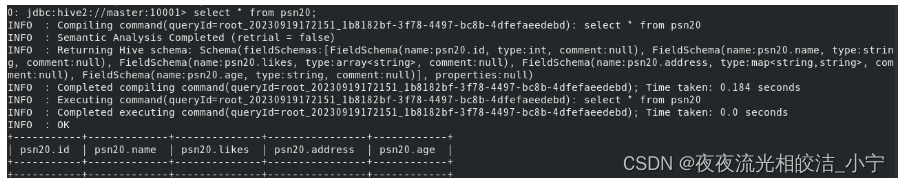
提示:
1、从表或分区中删除所有行。可以指定partition_spec一次截断多个分区,省略partition_spec将截断表中的所有分区(即分区表可以通过指定partition_spec删除表中指定的分区数据,如果不指定,则删除整个表中的分区数据)。
2、使用Truncate删除外部表会报错,因为外部表不被Hive所管理,被文件存储系统hdfs管理,所以需要先去hdfs中删除数据文件,再使用Truncate删除表元数据。
2.4.3 drop 和truncate的区别
1)drop 操作会删除元数据(即表不存在)和文件系统的数据(只针对普通表)
2)truncate操作只是会删除表中的数据,不会删除表的元数据(即表还存在,只针对普通表)
3)关于外部表,drop操作只会删除元数据,不会删除文件系统的数据,而truncate操作不能直接操作外部表,因为外部表的不属于Hive管理,直接操作会报错。
更多详细内容,可参考Hive官网DDL语句部分说明文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
好了,今天Hive基本SQL操作(DDL篇)的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!










