
一、说明
让我们试一试烧瓶(Flask)这个模型框架,这个应用程序可让您管理和扩展您的云端业务;它允许管理人员浏览和计算商店的总销售额并从在线商店 - 服装。
二、什么是烧瓶?
什么是烧瓶?它是一个Web框架 - 一个极简主义和轻量级的设计,用于在Python中构建Web应用程序。
我们将在网上开设一家服装店。以下是我们的架构:
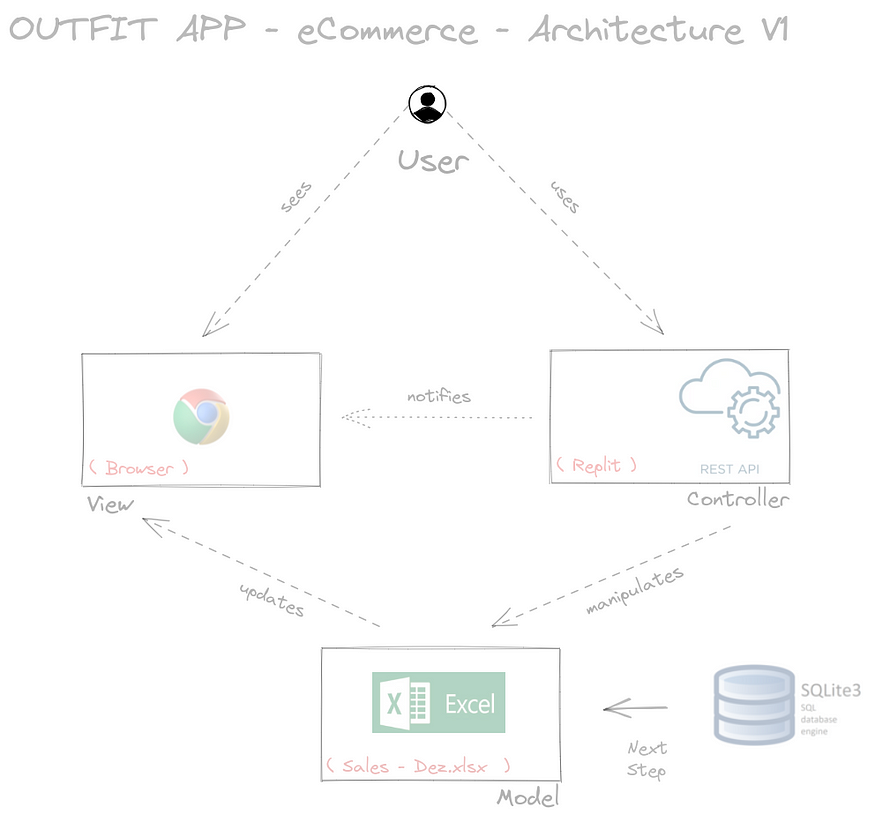
实际实现 v1-浏览器 — 控制器 — excel 组件;在下一集中,我们将把数据迁移到SQLite — Colaborate U2 : Excalidraw | Hand-drawn look & feel • Collaborative • Secure
我们的兴趣:时尚和服装网站。
服装是第一大时尚目的地,汇集了最好的高街品牌。

用于选择我们在您的服装店参加的时尚活动的思维导图 — 图片来自此链接
三、具体的实现服装电子商务的步骤
这是我们最初的服装百货商店库存:
Download db: (Sales — Dez.xlsx)

领口系列。图片来自此链接

棉花收藏。图片来自此链接
让我们开始吧!
0# 步骤 — 转到 Replit,创建一个帐户(如果还没有:)并在下面粘贴这些代码(或将其分叉:);我建议您先让它工作,他们尝试该应用程序,然后才尝试推理。Python很容易理解!
What is Replit used for?
Replit being Software as a
service (SaaS) allows users to
create online projects (called
Repls, not to be confused
with REPLs) and write code. 1# 步骤 — 加载数据库(点击 Replit 仪表板)snowman
from flask import Flask
import pandas as pd
app = Flask(__name__)
table = pd.read_excel("Sales - Dez.xlsx")此烧瓶代码执行以下任务:
- 导入必要的模块:代码使用语句导入 Flask 模块和 Pandas 模块。Flask用于创建Web应用程序,而pandas是用于数据操作和分析的库。
import - 创建 Flask 应用程序对象:该行创建 Flask 类的实例,该类表示 Flask 应用程序。该参数是一个特殊的 Python 变量,用于获取当前模块的名称。它通常用作 Flask 查找模板和静态文件等资源的参考点。
app = Flask(__name__)__name__ - 读取 Excel 文件:该行使用 pandas 读取名为“Sales - Dez.xlsx”的 Excel 文件,并将其加载到名为 的 pandas 数据帧中。Excel 文件可能包含销售数据,该函数分析文件的内容并创建数据帧,这是一个表格数据结构。
table = pd.read_excel("Sales - Dez.xlsx")tableread_excel()
通过执行这些代码行,将设置 Flask 应用程序,并将 Excel 文件中的销售数据加载到 pandas 数据帧中。这允许我们在您的 Flask 路由中使用数据帧并对销售数据执行操作,例如筛选、聚合或基于数据生成响应。table
2# step — 定义 ,返回总销售额root route
@app.route("/")
def gross_sales():
gross_sales = float(table["total of sales"].sum())
return {"gross_sales": gross_sales}此 Flask 代码为根 URL (“/”) 定义一个路由,并创建一个名为处理对该路由的请求的函数。以下是它的作用:gross_sales()
- 装饰器指定在向根 URL (“/”) 发出请求时应调用此函数。
@app.route("/") - 在函数内部,该行计算 Pandas 数据帧中“销售总额”列的总和,并将其分配给变量。该方法用于计算列值的总和。
gross_sales = float(table["total of sales"].sum())tablegross_sales.sum() - 计算值作为 JSON 响应使用该语句返回。它被包装在带有键“gross_sales”的字典中。响应将具有格式为 ,其中表示销售额的总和。
gross_salesreturn{"gross_sales": <value>}<value>
当对根 URL (“/”) 发出请求时,将执行该函数。它从数据帧中的“销售总额”列计算总销售额,并将其作为 JSON 响应返回。此终结点可用于从数据集中检索总销售额信息。gross_sales()table
3# step — 终点将所有 50 个项目分组和求和/sales/products
@app.route("/sales/products")
def sales_products():
table_prod_sales = table[["products",
"total of sales"]].groupby("products").sum()
sales_products_json = table_prod_sales.to_dict()
return sales_products_json此代码提供了一个 API 终结点,用于检索数据库中所有产品的销售数据,并将其作为 JSON 响应返回。销售数据包括每个产品的总销售额。此终结点可用于以方便的 JSON 格式提取所有产品的销售数据。
以下是代码的工作原理:
- 路由是使用带有 URL 模式“/sales/products”的装饰器定义的。这意味着路由需要对“/sales/products”URL 的请求;
@app.route() - 当向此路由发出请求时,将执行该函数;
sales_products() - 在函数内部,将创建 的子集,仅包含“产品”和“销售总额”列。该方法用于按产品对数据进行分组,并计算每个产品的销售额总和。我们使用 Pandas 数据帧通过传递两个字段的列表来搜索表,然后将它们分组并取总和。这一行我们带来了表格的一个子集;
table.groupby("products").sum()productstotal of sales; - 使用该方法将分组的销售数据转换为字典并存储在变量中;
.to_dict()sales_products_json - 包含所有产品的销售数据的字典作为 JSON 响应返回。
sales_products_json
通过搜索传递两个字段列表的表,然后将它们分组并取总和。这行我们带来了这个表格:productstotal of sales;
products, consolidated total grouped Amaryllis Dress, 96991.00 Aster Pants, 39111.00 Boat Neck, 15355.00 Breathable Dobby, 14744.00 Crew Neck, 52793.00 Denim Jeans, 26720.00 Dobby Dress, 60614.00 Draped, 20191.00 Fig Dress, 172768.00 Flora Blouse, 53576.00 Forrest Jumpsuit, 188215.00 Gambit Pinafore, 63883.00 Giger Dress, 19170.00 Ginger Skirt, 18450.00 Halter, 6020.00 Halter Light, 9048.00 Halter Woven, 15162.00 Illusion, 200.00 Jarrah Dress, 31800.00 Jeans Jackets, 21432.00 Jeans Skirt, 6240.00 Jeans Unisex, 11532.00 Karri Top, 8160.00 Kerria Anorak, 331636.00 Keyhole, 8844.00 Microtex Blouses, 15827.00 Off-Shoulder, 12420.00 One-Shoulder, 11658.00 Peter Pan Collar, 268020.00 Plunging, 12036.00 Poppy Dress, 12403.00 Sew Summer Tops, 92879.00 Soft Trench, 488848.00 Square Neck, 17864.00 Standard Shirts, 20770.00 Strapless, 33354.00 Surplice, 28052.00 Sweetheart, 49840.00 Sweetheart Cotton, 177031.00 Sweetheart Unisex, 23968.00 Trench Coat, 269.00 Trillim Essemble, 29427.00 Trillim Essemble Ginger, 11641.00 Trillim Essemble Microtex, 34883.00 Turtleneck, 10701.00 Ursi Assemble, 44751.00 V-Neck, 13910.00 Vallea Tunic, 31204.00 Victorian, 58896.00 Women Pants, 124004.00
这是通过以下烧瓶路由返回的:
/sales/products/<item>/sales/products and you can use it to make search using the next route:
4# step — 这将按项目名称搜索我们的数据库
@app.route("/sales/products/<item>")
def sales_per_item(item):
table_prod_sales = table[["products", "total of sales"]].groupby("products").sum()
if item in table_prod_sales.index:
item_sales = table_prod_sales.loc[item]
sales_item_json = item_sales.to_dict()
return sales_item_json
else:
return {item: "Not Found in this database"}此代码提供了一个 API 终结点,该终结点从数据库中检索特定产品的销售数据,并将其作为 JSON 响应返回。如果在数据库中找不到该项,它将返回一条相应的消息,指示未找到该项
以下是代码的工作原理:
- 路由是使用装饰器定义的,将 URL 模式指定为“/sales/products/<item>”。这意味着路由需要“/sales/products/<item>”形式的 URL,其中“<item>”可以替换为产品名称;
@app.route() - 参数将传递给函数 。
itemsales_per_item(item) - 在函数内部,创建了 的子集,仅包含“产品”和“总销售额”列;该方法用于按产品对数据进行分组,并计算每个产品的销售额总和。
table.groupby("products").sum() - 该函数检查分组销售数据的索引中是否存在指定的值。如果是,则使用 检索该项目的销售数据
item.loc[item]; - 物料的销售数据使用该方法转换为字典并存储在变量中。
.to_dict()sales_item_json - 如果在销售数据中找到该项目,则字典将作为 JSON 响应返回;
sales_item_json - 如果在销售数据中找不到该项,则返回具有单个键值对的字典,其中 是键,值是“在此数据库中找不到”。这表示在数据库中找不到指定的项。
item
5# 步 — 最后一行
app.run(host="0.0.0.0")Flask 中的行启动 Flask 开发服务器并将其绑定到 IP 地址“0.0.0.0”。app.run(host="0.0.0.0")
以下是它的作用:
app引用已创建的 Flask 应用程序对象。- 在对象上调用该方法以启动 Flask 开发服务器。
run()app - 参数设置为“0.0.0.0”。这意味着开发服务器将绑定到计算机上的所有可用网络接口,允许它接受来自任何 IP 地址的请求。
host
通过使用“0.0.0.0”作为主机,可以从同一网络上的其他设备访问 Flask 应用程序。当您想要从其他设备测试或访问 Flask 应用程序或允许外部访问时,这非常有用。
请务必注意,使用“0.0.0.0”作为主机可以使网络上的任何人都可以访问您的应用程序,因此在生产环境中使用此配置时要谨慎并考虑适当的安全措施。
6# 步 — 一气呵成
from flask import Flask
import pandas as pd
app = Flask(__name__)
table = pd.read_excel("Sales - Dez.xlsx")
@app.route("/")
def gross_sales():
gross_sales = float(table["total of sales"].sum())
return {"gross_sales": gross_sales}
@app.route("/sales/products")
def sales_products():
table_prod_sales = table[["products",
"total of sales"]].groupby("products").sum()
sales_products_json = table_prod_sales.to_dict()
return sales_products_json
@app.route("/sales/products/<item>")
def sales_per_item(item):
table_prod_sales = table[["products", "total of sales"]].groupby("products").sum()
if item in table_prod_sales.index:
item_sales = table_prod_sales.loc[item]
sales_item_json = item_sales.to_dict()
return sales_item_json
else:
return {item: "Not Found in this database"}
app.run(host="0.0.0.0")四、一种注释:
Flask 的目的是什么?
[CHAT-GPT]
Flask 是一个流行的 Web 框架用于构建网络应用程序在Python中。
其目的是为开发者提供 以一种简单而灵活的方式创建 Web 应用程序和 API。
Flask 以其简约而闻名和轻量化设计,允许开发商拥有更多控制权开发过程并做出根据他们的决定具体项目要求。
Flask 的主要目的是处理低级细节网络开发,例如路由 HTTP 请求到适当的功能,管理会话数据,并生成 HTTP 响应。
它提供了一套工具和有助于简化的库的发展过程,使得更容易构建网络应用程序使用Python。
Flask 遵循“微”框架
哲学,这意味着它提供仅核心功能需要构建网络应用程序,同时允许开发者添加附加功能和扩展按要求。
这种简约的方法使得Flask 高度通用,允许开发商要保留他们的应用轻量级和高效。
简单性和灵活性
Flask 做出了贡献其在开发商中的受欢迎程度。其学习程度相对较低曲线,使其触手可及对于初学者,同时仍然提供必要的功能对于更复杂的项目。
Flask 也有一个大的和活跃的社区,这意味着有很多资源和可提供帮助的扩展开发人员构建稳健和可扩展的网络应用程序。
这就是所有,再见!








