目录
1、在虚拟机目录创建 Hadoop02 和 Hadoop03
(4)在Windows中 ping虚拟机(hadoop002)
搭建Hadoop集群需要做安装准备,需要下载 jdk,安装VMware。
链接:https://pan.baidu.com/s/1wwTKk-XxHbccHjE-Xk2PTA
提取码:q7j7 (这是网盘的分享链接,里面有jdk,VMware)
一、安装 jdk
如果下载有jdk8,可以下载 jdk17(网盘里有安装包,也可到官网下载)
1、查看电脑中安装的 jdk 版本
win+R 打开命令提示符界面 或者 直接在应用中搜命令提示符界面
win+R ——> 输入cmd确定 进入命令提示符界面
输入
java -version有图可以看出 jdk 版本是1.8(jdk8)

2、安装 jdk17
和安装 jdk8 是一样的
直接双击安装包
3、配置 path(配置jdk)
在电脑中打开设置——>高级系统设置——>环境变量
在系统变量中进行配置
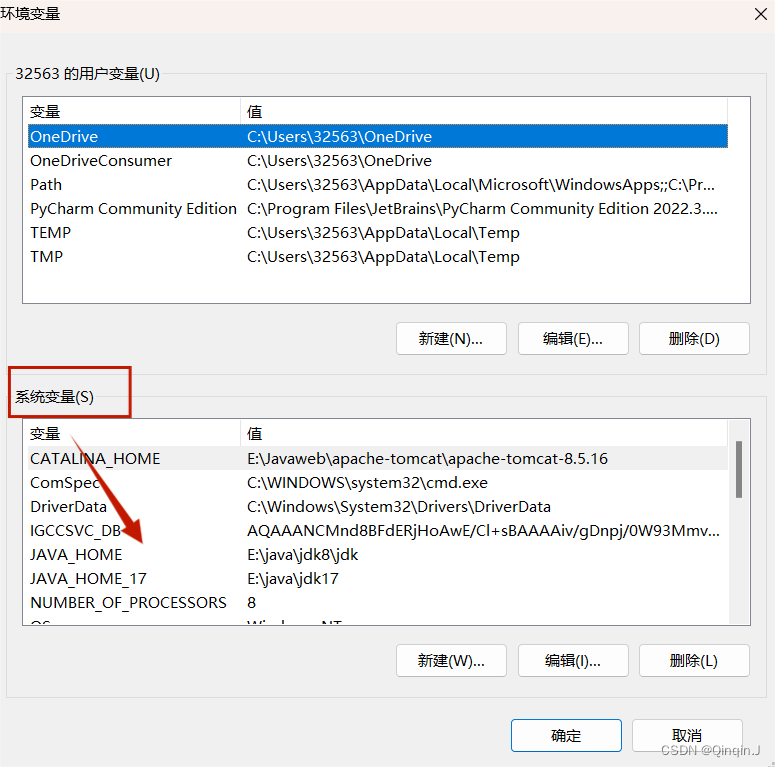
添加两个JAVA_HOME,分别是 jdk8 和 jdk17 (安装前最好不更换路径)
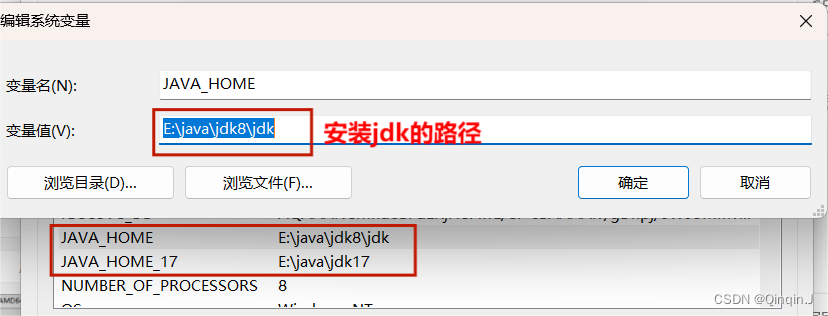
添加
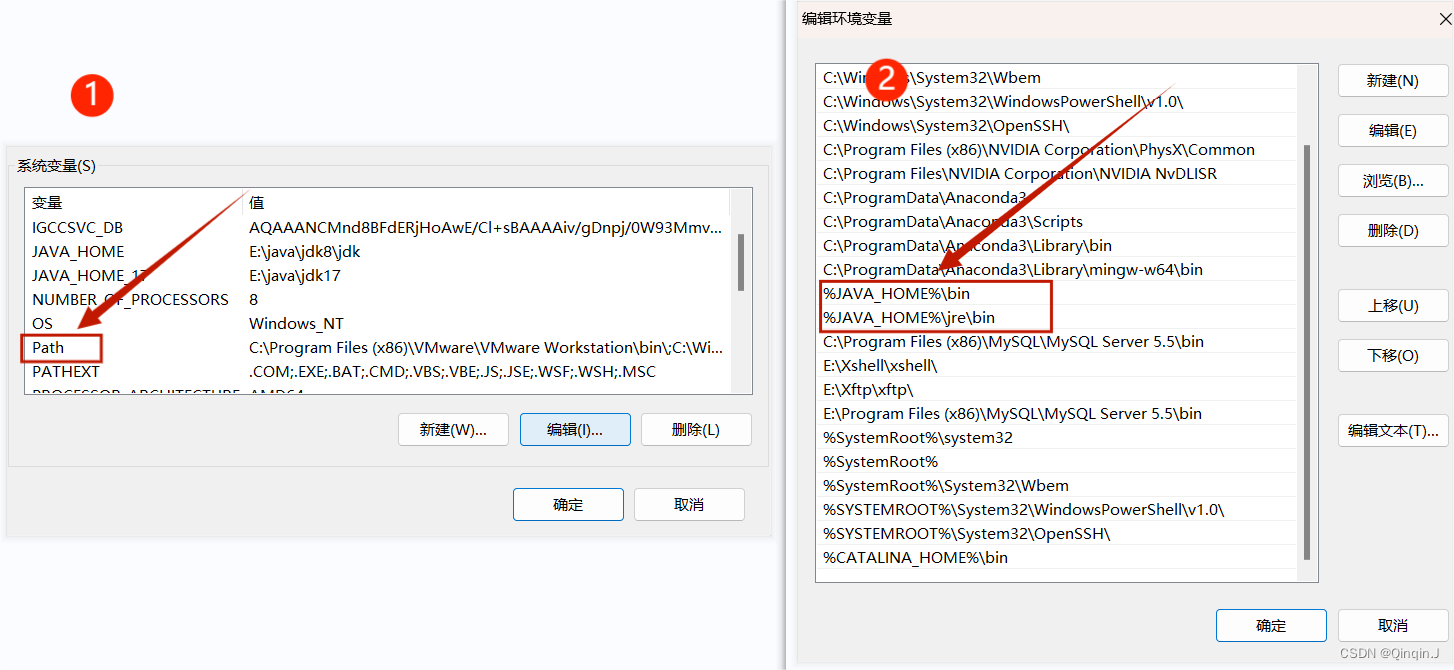
然后一直确定确定
win+R ——> 输入cmd确定 进入命令提示符界面 出现如下图表示安装成功
4、对 jdk8 和 jdk17 版本做自由切换
先进行删除
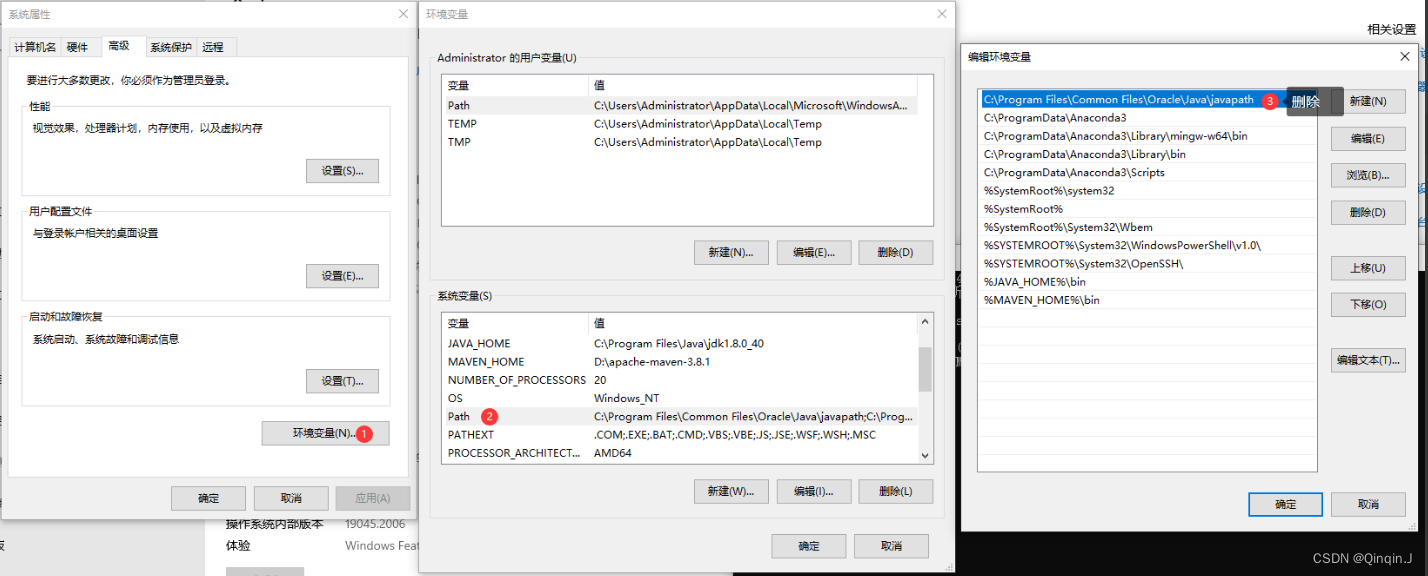
使用哪个版本的 jdk 就进行修改
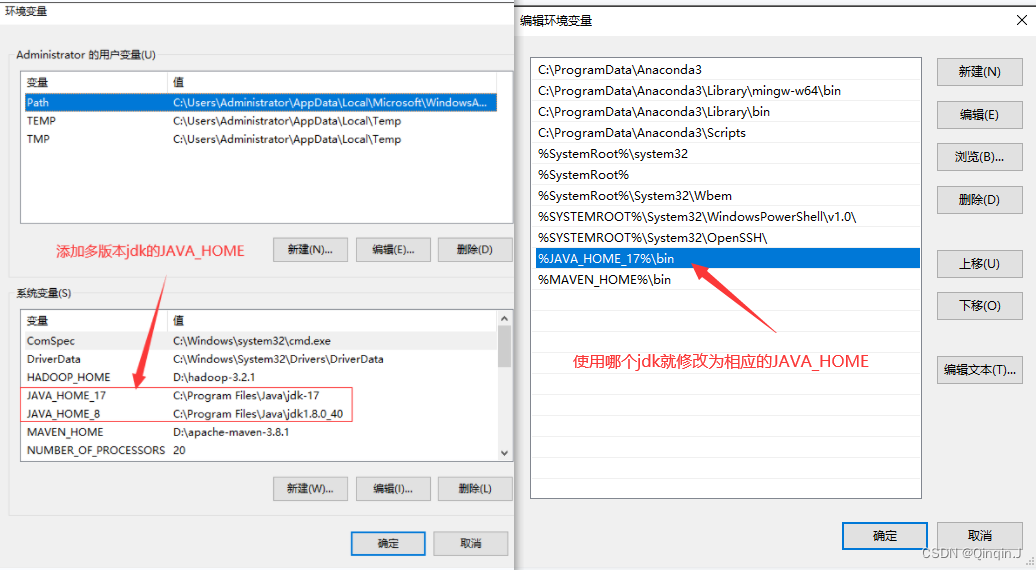
然后点击确定 确定 确定
win+R ——> 输入cmd确定 进入命令提示符界面
输入 java -verson 命令 (由图可知 是jdk8)
二、安装vmware
(网盘中有安装包,也可到官网下载)
路径不修改,点击下一步

取消√后,点击下一步
这时不要点击完成(一定先不要点击完成)
点击许可证输入密钥
输入密钥后点击输入
即安装完成
三、安装centos 7(虚拟机)
先新建虚拟机

指定要安装的系统的镜像文件位置(网盘中有镜像安装包)
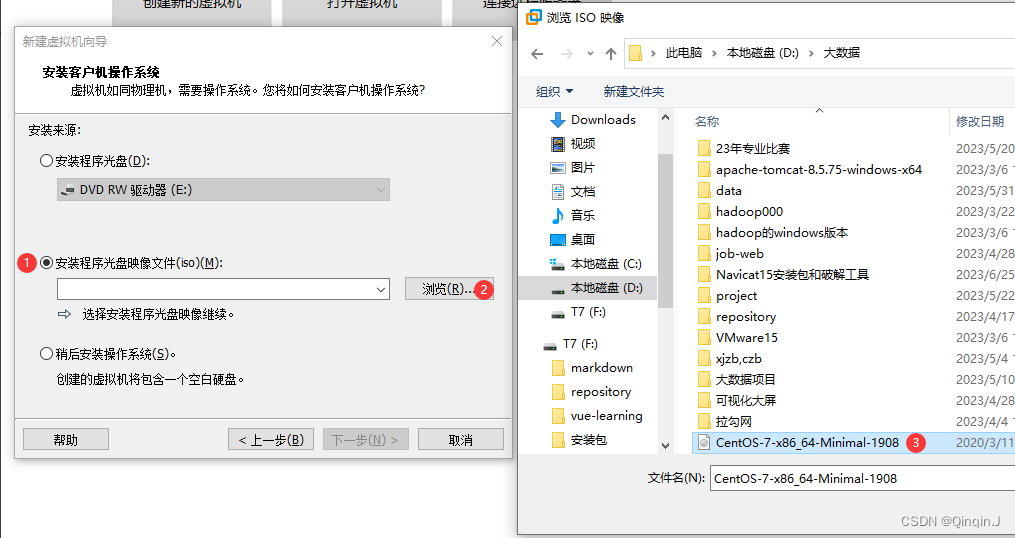
先到 D盘 或者 E盘下,创建文件夹 vmfile\hadoop\c2\Hadoop01(文件自己创建,自己记得就行)
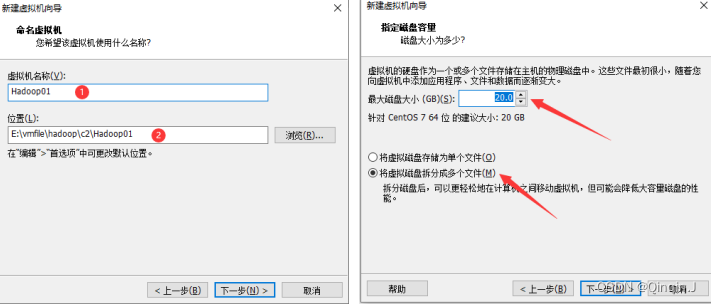
选好后,点击下一步
点击完成后虚拟机自动启动,选择安装系统
选择系统语言为中文,然后点击继续
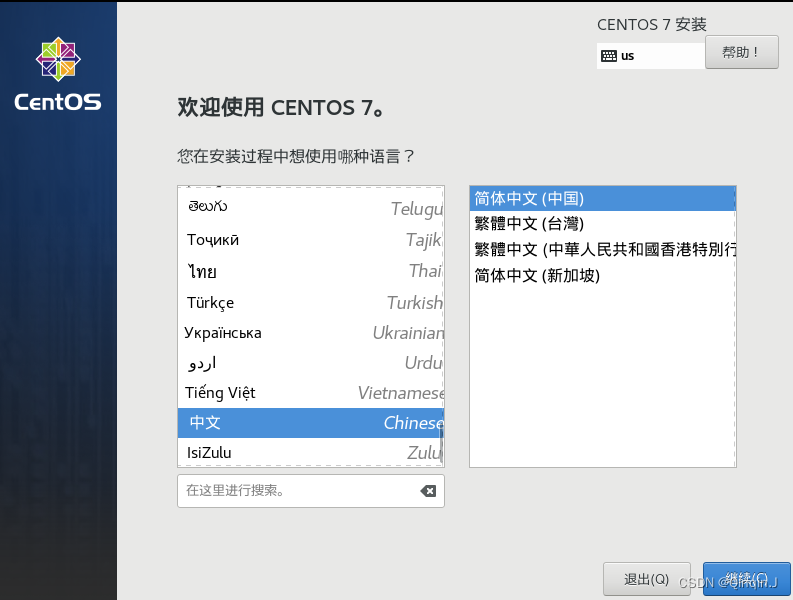
调整时间(当前时间为几点就设置几点),然后点击完成
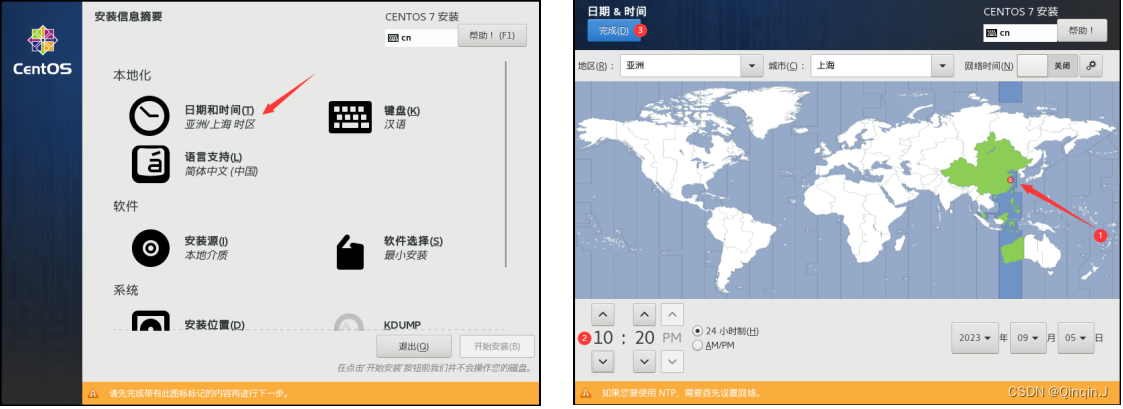
选择系统安装的位置,不要选择,直接点击完成
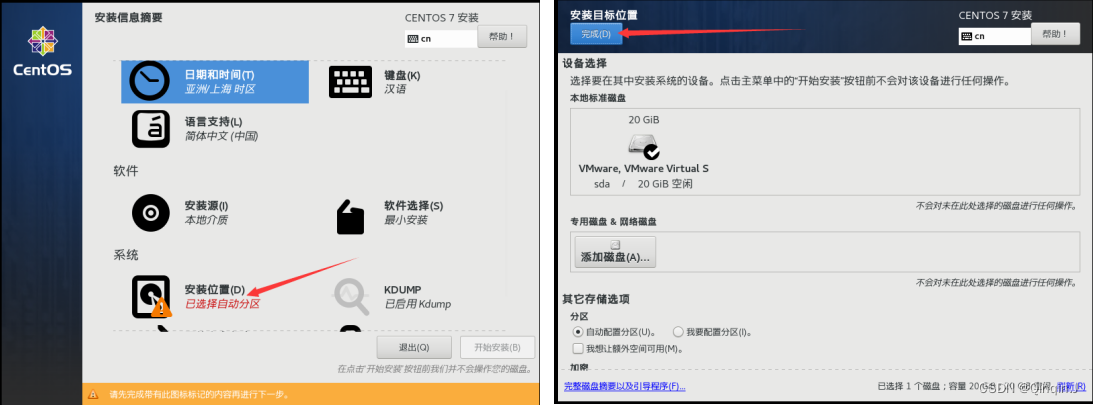
点击开始安装

设置密码(自己记住就行)
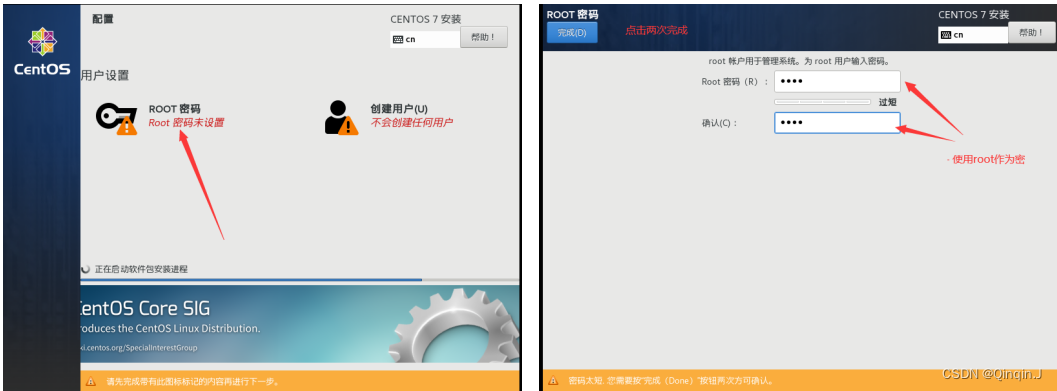
等待安装完成后重启即可
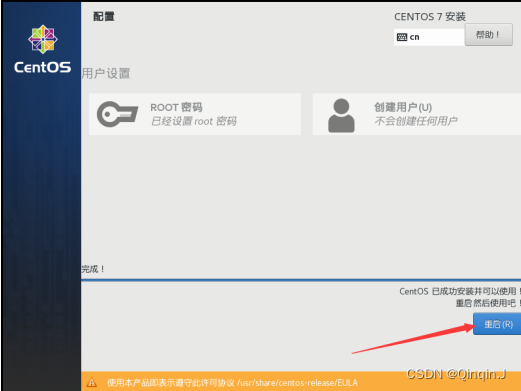
四、虚拟机设置
虚拟机——>设置

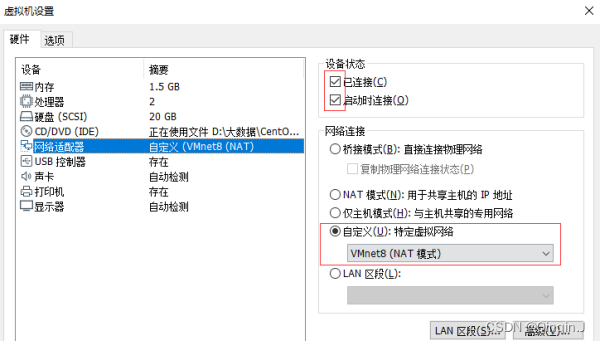
注意一定要选择Vmnet8(NAT模式)
五、虚拟机网络配置
目标:虚拟机和宿主机可以互相访问,虚拟机可以访问外网(www.baidu.com)
虚拟机的网络模式分为 NAT 和 桥接
我们使用的是 NAT 模式
1、查看 NAT 的网段
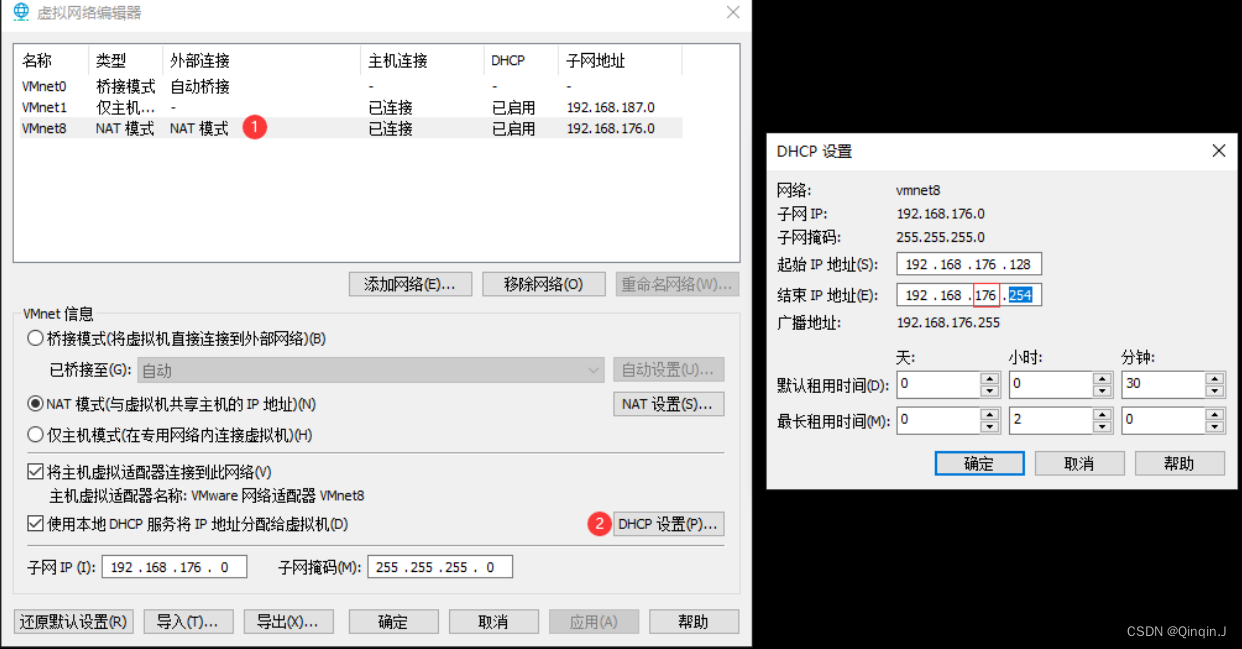
虚拟网段为 176,IP 地址的范围 128 ~ 254
登录虚拟机后,输入以下命令
vi /etc/sysconfig/network-scripts/ifcfg-ens33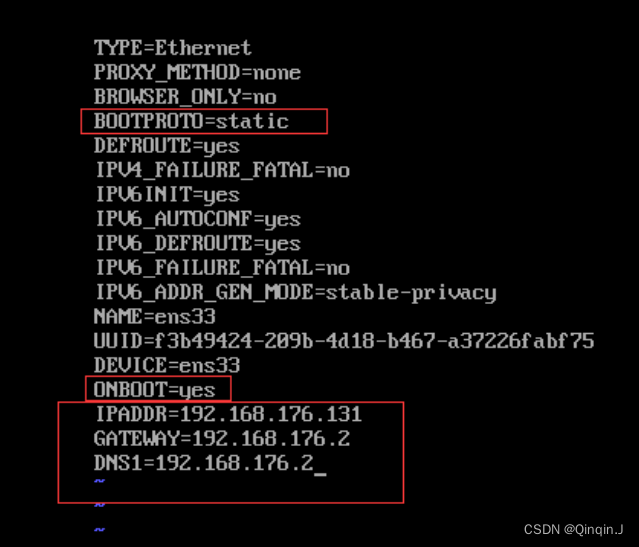
修改后保存退出
然后输入命令:service network restart(服务网络重启)
service network restart
尝试连接百度:ping www.baidu.com
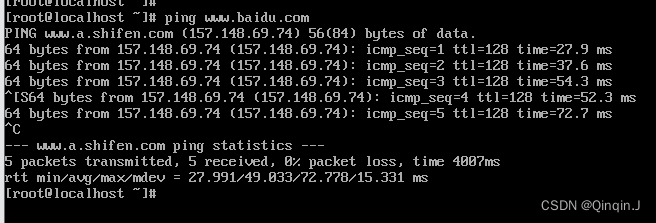
2、修改主机名
(1)修改虚拟机的 hosts
输入ip a 查自己的IP
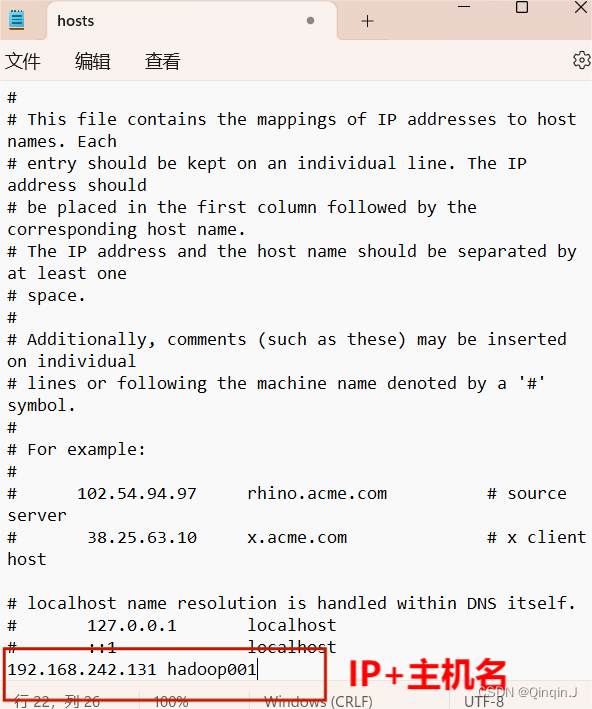
输入:vi /etc/hosts
vi /etc/hosts添加 IP + 主机名 然后保存退出
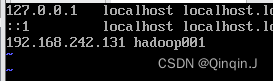
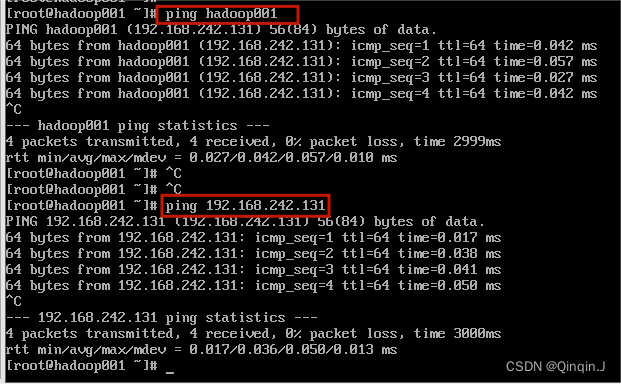
可以 ping 主机名 或 ping IP
为了方便配置后面的 Hadoop002 和 Hadoop003 添加 IP+主机名

保存并退出
(2)修改虚拟机的hostname
输入:vi /etc/hostname
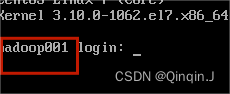
vi /etc/hostname删除原来的内容,修改为:hadoop001(主机名自己改),保存退出
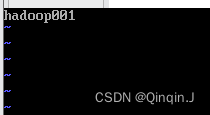
重启虚拟机可以看到
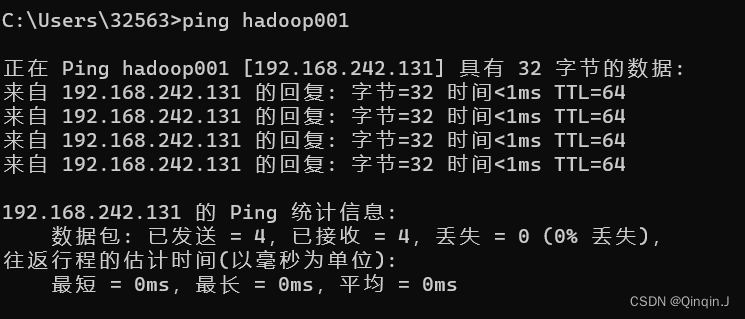
3、在Windows中 ping虚拟机
现在需要到Windows的命令提示符界面(win+R)ping虚拟机
输入ip a 查自己的IP
修改windows 的hosts
这时要下载phpStudy(网盘有安装包,也可到官网下载)
打开phpStudy
用记事本打开(用别的打开也行),编辑并且保存
win+R ——> 输入cmd确定 进入命令提示符界面
输入:ping 主机名 或者 ping IP
六、其他的配置
1、使用远程工具
需要用到 Xshell (网盘中有安装包,也可到官网下载)
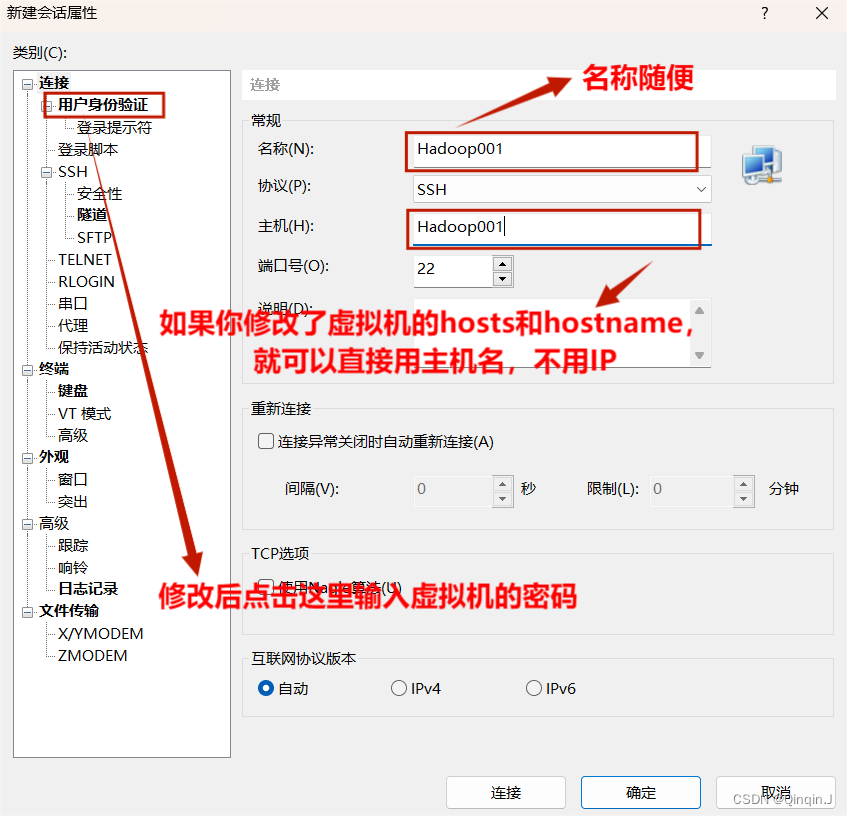
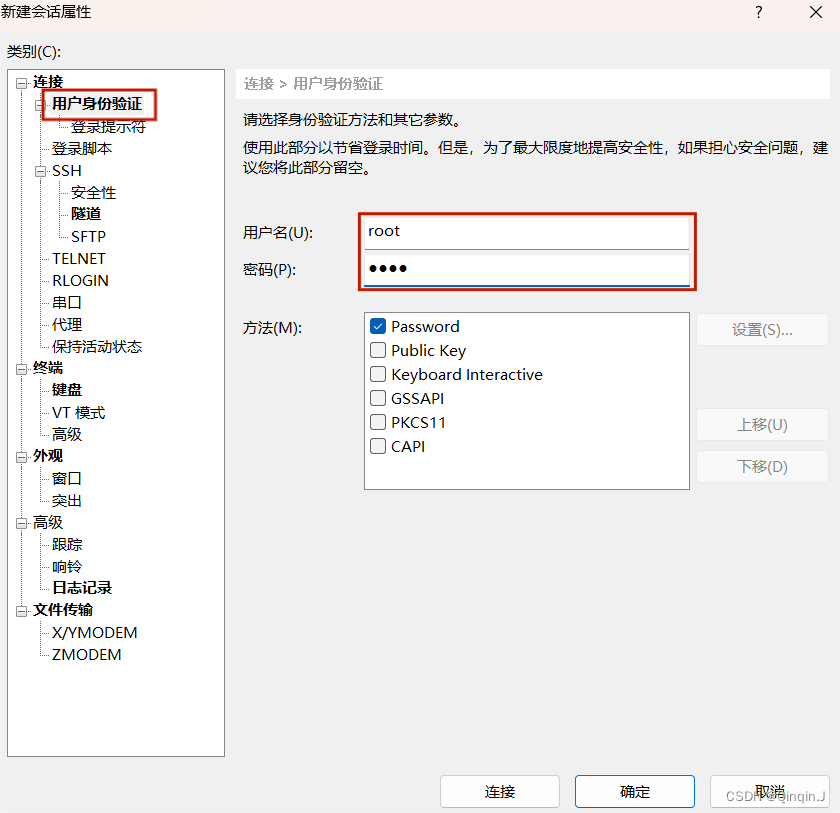
输入密码,接受并保存
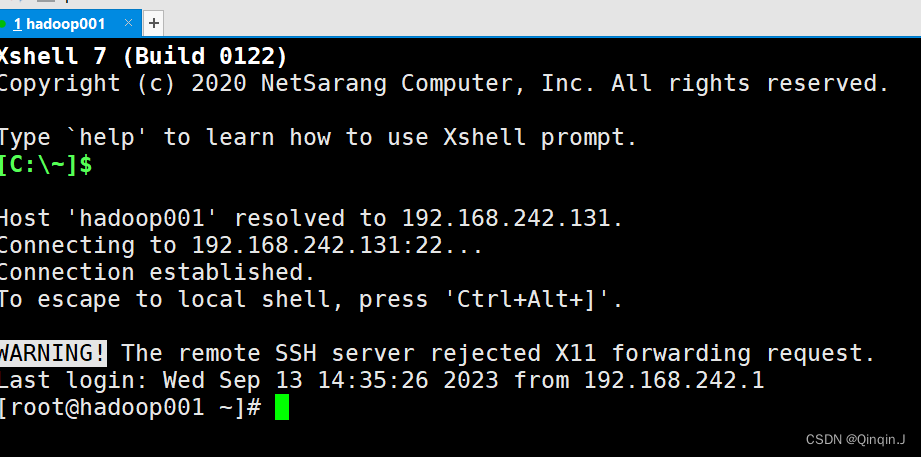
登录连接成功
2、安装一些必要的工具
在Xshell中输入以下命令安装工具
(1)安装额外的速度较快的镜像库
yum install -y epel-release(2)安装同步工具,方便在多台服务器上进行文件的传输
yum install -y rsync(3)安装网络工具
yum install -y net-tools(4)安装具有代码高亮显示的编辑器
yum install -y vim3、关闭防火墙
(1)查看防火墙状态
systemctl status firewalld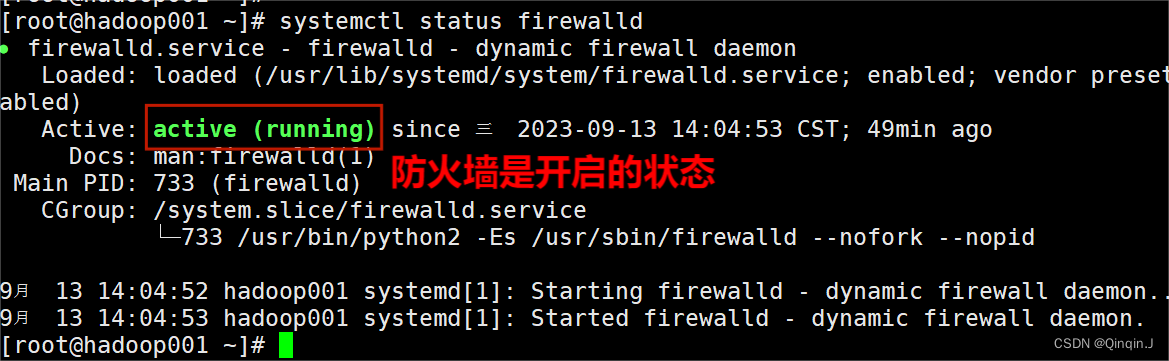
(2)关闭防火墙
取消 firewalld 服务自启开机
systemctl disable firewalld
关闭 firewalld 服务
systemctl disable firewalld
(3)查看防火墙状态
systemctl status firewalld
4、在虚拟机创建两个目录
software 用于存储软件安装包
module 用于存放安装包解压后的文件

七、克隆虚拟机
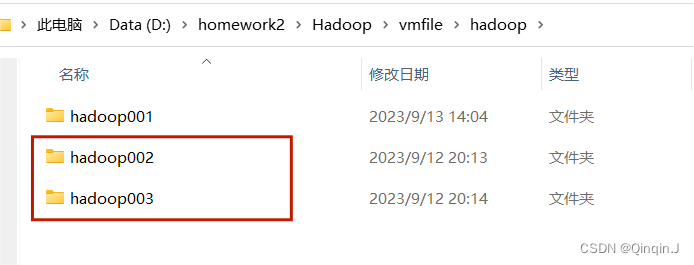
1、在虚拟机目录创建 Hadoop02 和 Hadoop03
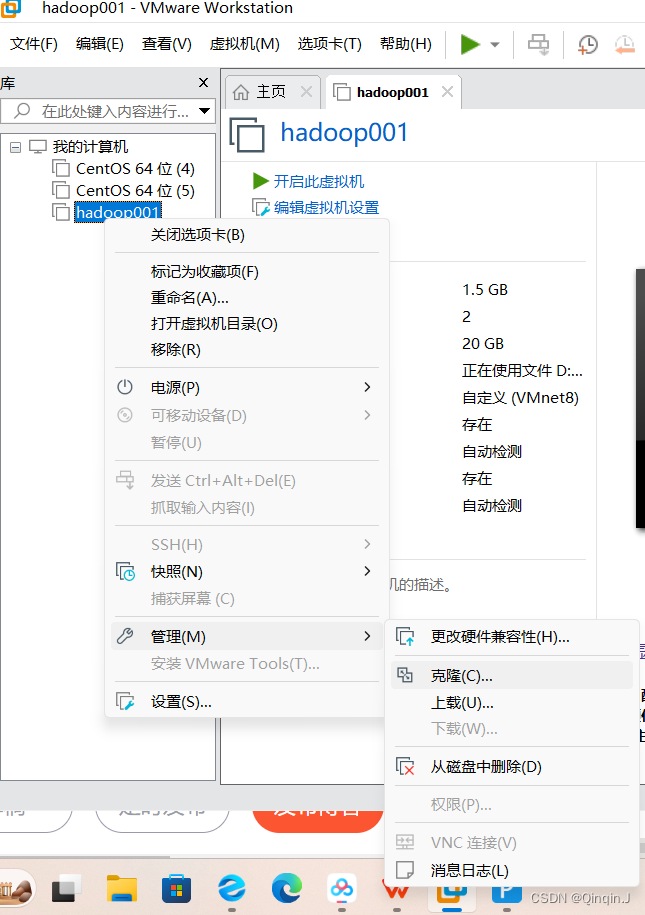
2、克隆虚拟机
克隆之前先关闭虚拟机
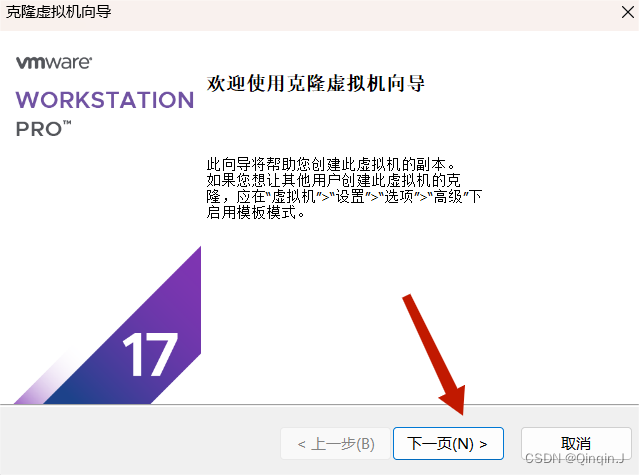
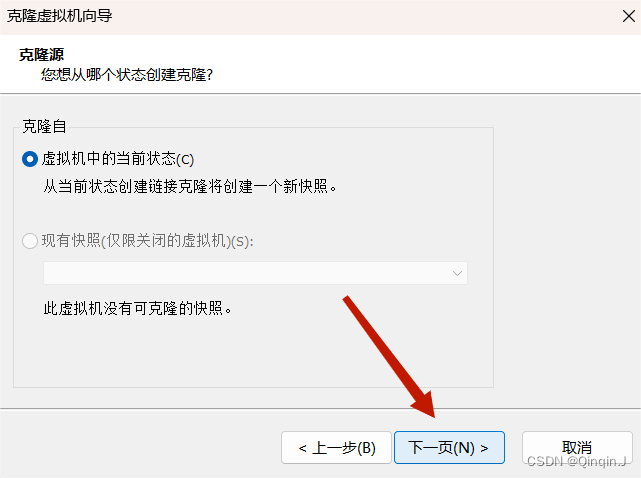
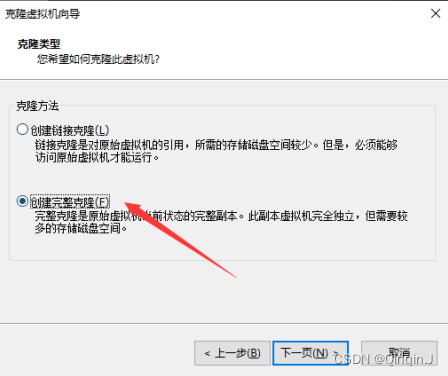

克隆完成
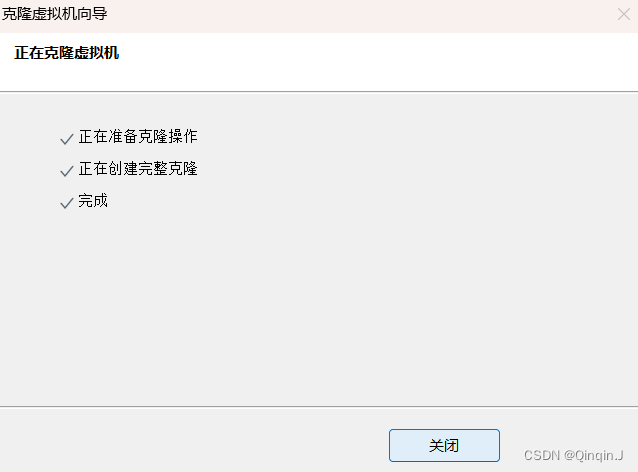
按照克隆Hadoop002的方法去克隆Hadoop003
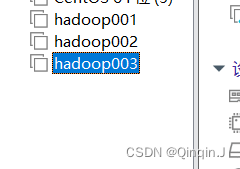
3、配置 IP 地址 和主机名
根据Hadoop001的 IP 把 Hadoop002 和 Hadoop003 的 IP 分别修改
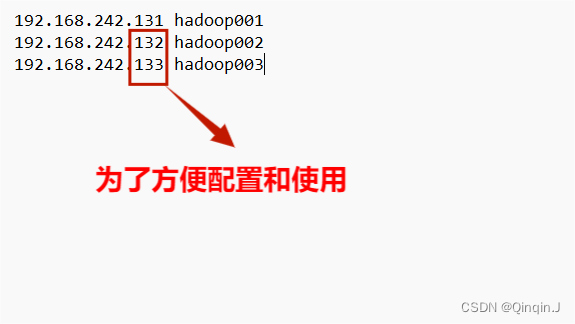
(1)配置Hadoop002的网段
vi /etc/sysconfig/network-scripts/ifcfg-ens33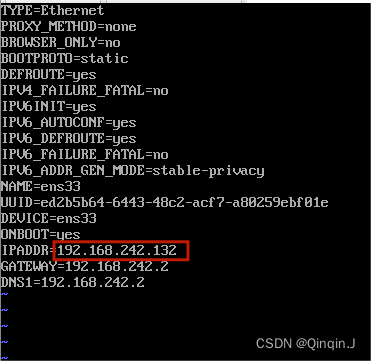
保存退出
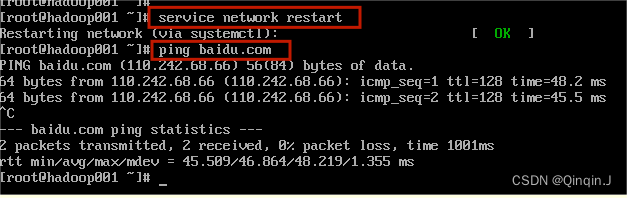
然后输入命令:service network restart(服务网络重启)
service network restart尝试连接百度:ping baidu.com
(2)修改虚拟机hadoop002的 hosts
输入ip a 查自己的IP
输入:
vi /etc/hosts添加 IP + 主机名 然后保存退出

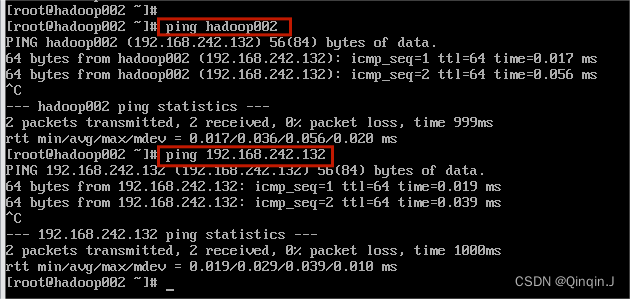
可以 ping 主机名 或 ping IP
(3)修改虚拟机hadoop002的 hostname
输入:
vi /etc/hostname删除原来的内容,修改为:hadoop002(主机名自己改),保存退出
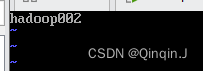
重启虚拟机可以看到
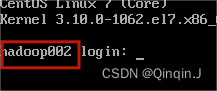
(4)在Windows中 ping虚拟机(hadoop002)
现在需要到Windows的命令提示符界面(win+R)ping虚拟机
输入ip a 查自己的IP
修改windows 的hosts
这时要下载phpStudy(网盘有安装包,也可到官网下载)
打开phpStudy
用记事本打开(用别的打开也行),编辑并且保存
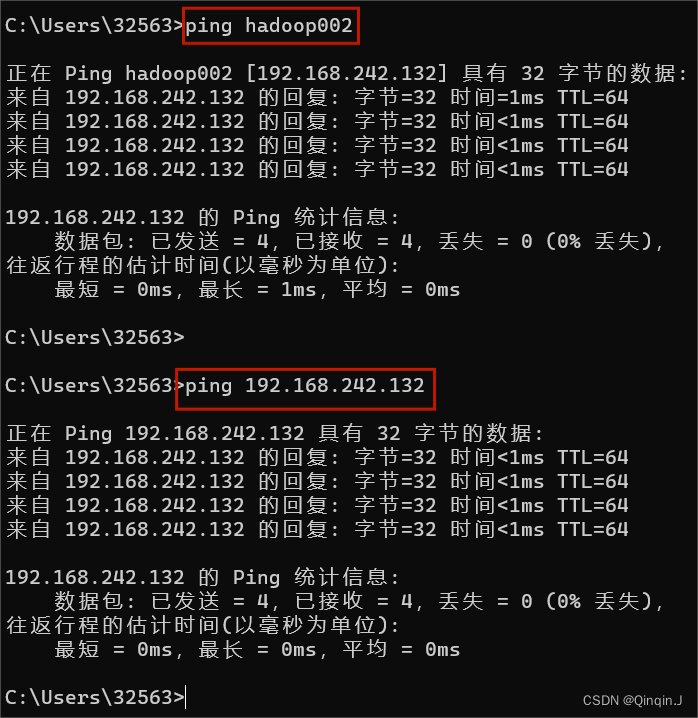
win+R ——> 输入cmd确定 进入命令提示符界面
输入:ping 主机名 或者 ping IP
(5)配置Hadoop003
和配置Hadoop002一样操作
和配置Hadoop002一样操作
和配置Hadoop002一样操作
八、SSH免密登录功能配置
在 SecurityCRT 或者 Xshell 进行连接

1、生成密钥
先给hadoop001生成密钥
输入
ssh-keygen -t rsa可以不用输入任何内容,连续按四次Enter键确认,生产密钥
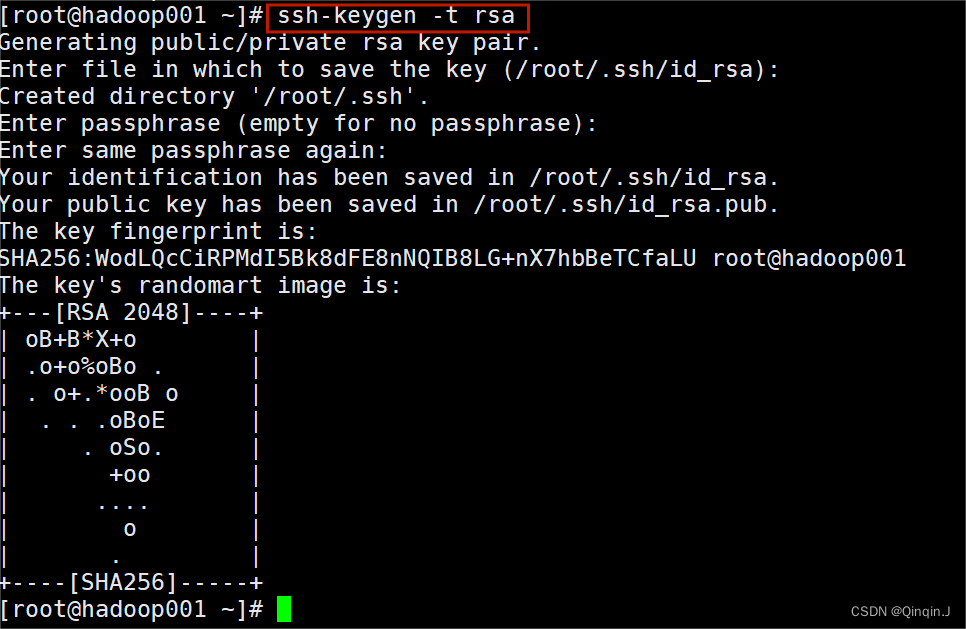
查看 ls –a
ls –a
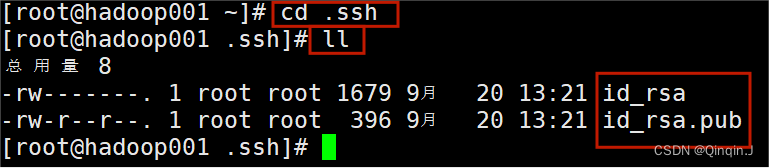
进入 .ssh隐藏目录
命令:
cd .ssh查看命令:ll
Id_rsa是hadoop01的私钥 Id_rsa.pub是公钥
以此类推给hadoop02和hadoop03生成密钥
以此类推给hadoop02和hadoop03生成密钥
以此类推给hadoop02和hadoop03生成密钥
2、给虚拟机发公钥
发公钥先给hadoop01发一个公钥
命令:ssh-copy-id +主机名
ssh-copy-id +主机名输入Yes 然后输入密码可以是密码都一样
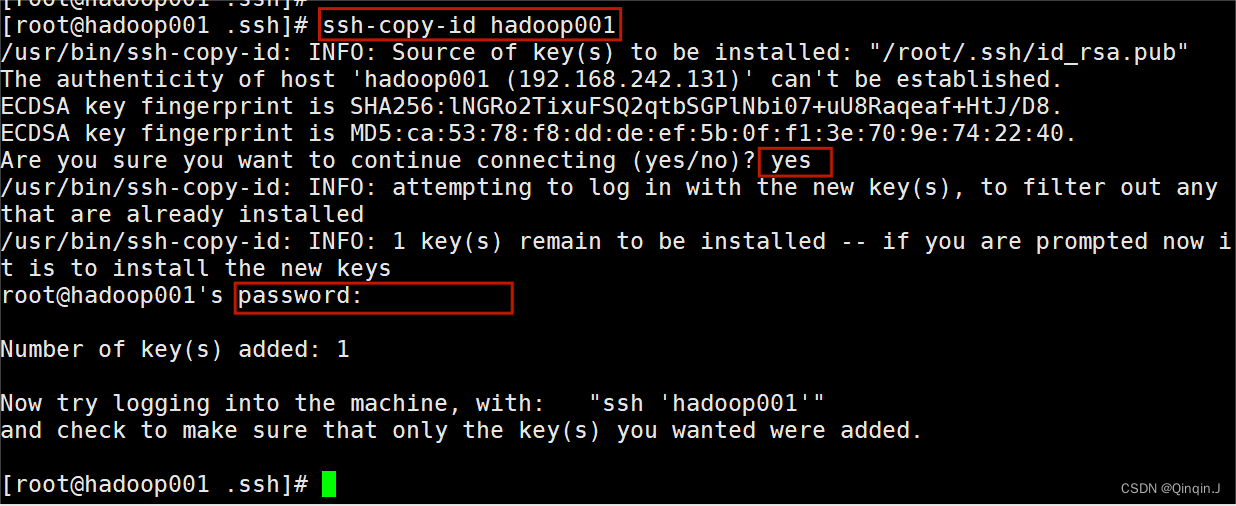
查看公钥是否发成功
命令:cat authorized_keys
cat authorized_keys
在hadoop01中给hadoop02和hadoop03分别发公钥
在hadoop01中给hadoop02和hadoop03分别发公钥
在hadoop01中给hadoop02和hadoop03分别发公钥
命令:ssh-copy-id +主机名
ssh-copy-id +主机名Yes 然后输入密码
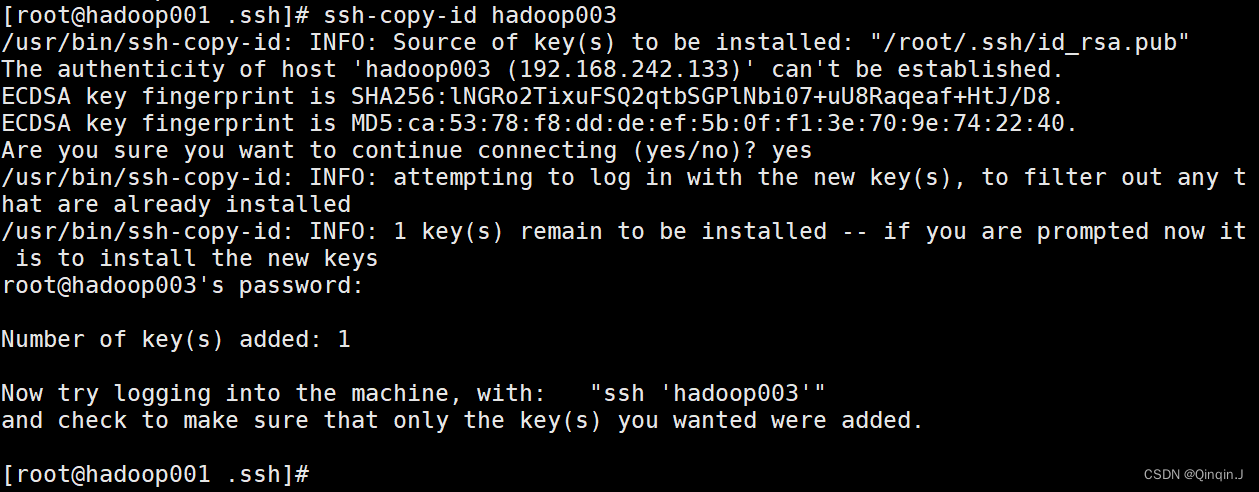
然后去hadoop02和hadoop03查看
查看公钥是否发成功
命令:cat authorized_keys
cat authorized_keys
以此类推hadoop01、hadoop02、hadoop03三台虚拟机相互发公钥,都互相有公钥
以此类推hadoop01、hadoop02、hadoop03三台虚拟机相互发公钥,都互相有公钥
查看公钥是否发成功
命令:cat authorized_keys
cat authorized_keys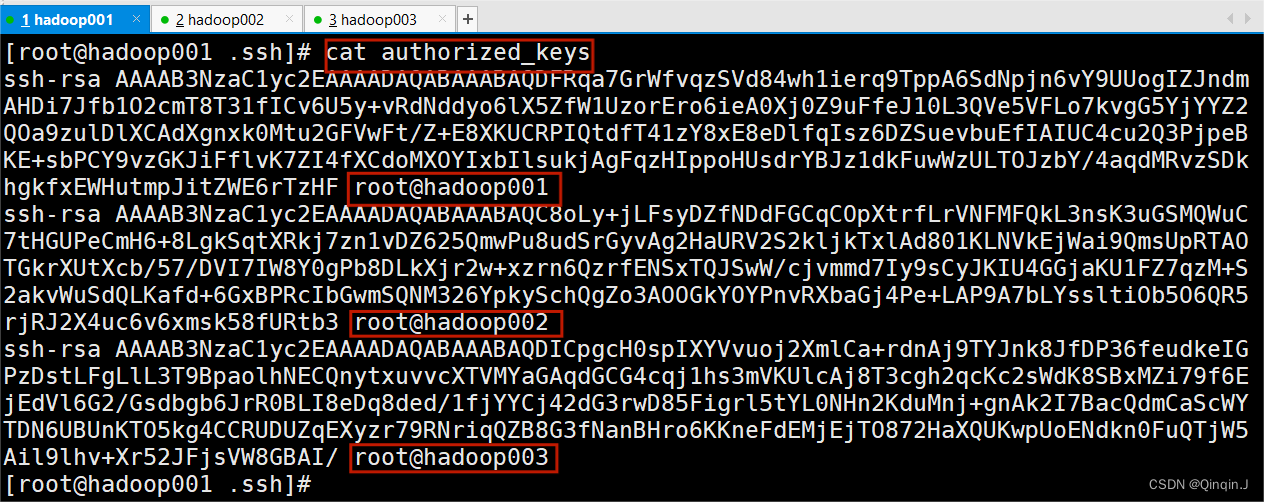
查看三台虚拟机发现都相互有公钥就可以了










