任务调度
何时需要调度执行一个任务?
-
第一:当任务创建的时候,需要决定是继续执行父进程,还是调度执行子进程
-
第二:在一个任务退出时,需要做出调度决策,需要从
TASK_RUNNING状态的所有任务中选择一个任务来执行 -
第三:当一个任务阻塞在 I/O 上,或者因为其他原因阻塞,必须调度另一个任务执行
-
第四:在一个 I/O 中断发生时,必须做出调度决策。
I/O 中断来源于 I/O 设备,说明 I/O 的工作结束了,需要唤醒正在阻塞在这个 I/O 上的进程,这个时候,调度程序要决定是否调度这个被唤醒的任务。
-
第五:时钟中断发生的时候
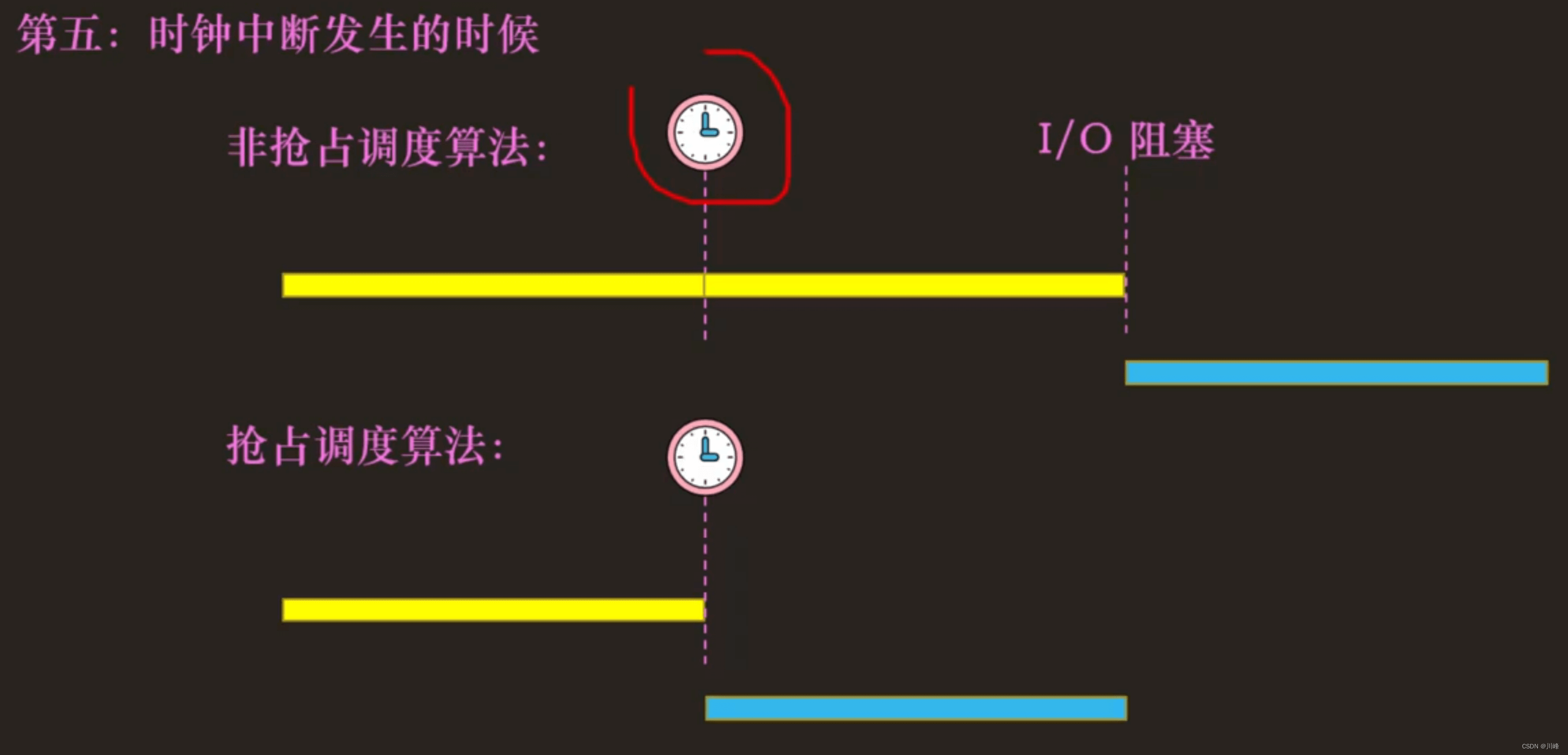
问题:如何实现对响应时间敏感的调度程序?
-
轮转调度(Round-Robin, RR)
-
基本思想:在一个时间片内运行一个任务,时间片结束,然后切换到下一个任务,而不是运行一个任务直到结束。这样反复执行,直到所有任务完成。
-
RR 有时被称为时间切片,时间片长度必须是时钟中断周期的倍数。如果时钟中断是每
10ms中断一次,则时间片可以是10ms、20ms或10ms的任何倍数。
信号处理
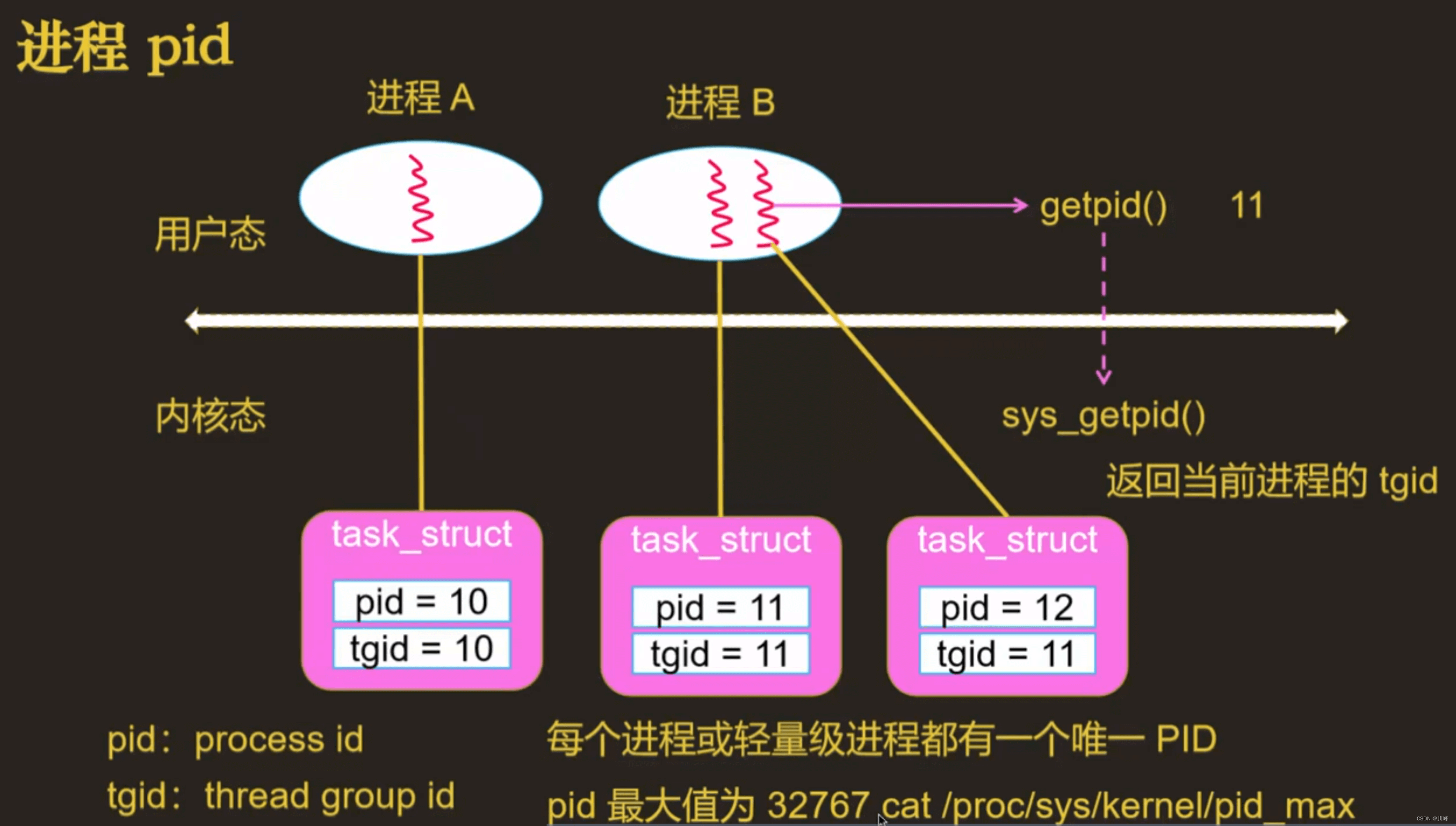
什么是信号?
例如 kill -9 2334,内核先找到pid = 2334的进程,并杀掉这个进程以及 tgid = 2334 的线程。
-
给进程
2334发送9号信号:SIGKILL -
一共有
64个信号:kill -l -
信号是很短的消息,可以被发送到一个进程或一组进程
-
每个信号,本质上就是一个数字而已
信号处理大体流程:
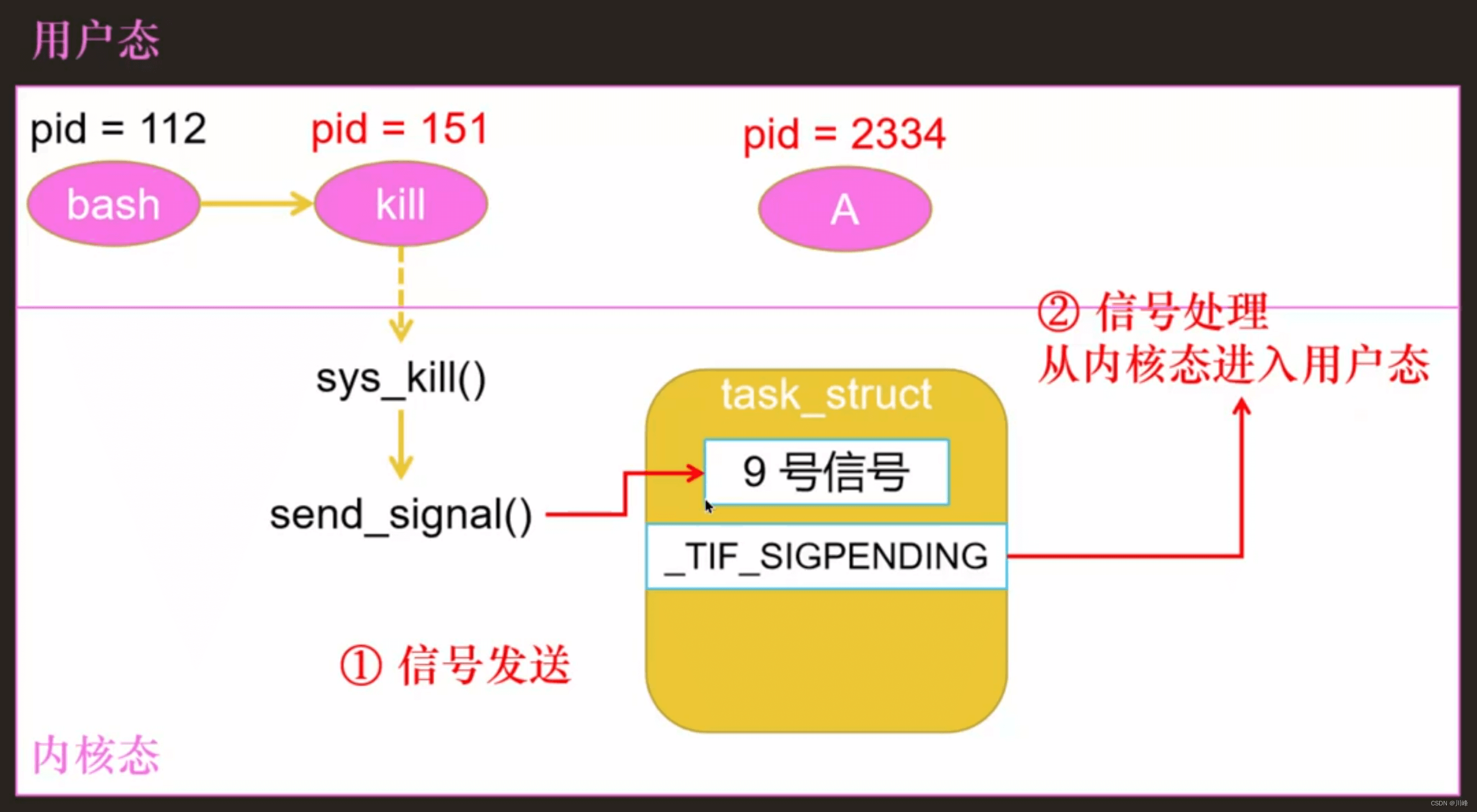
信号发送:
-
kill(pid, sig):向pid所在的线程组发送一个sig号信号 -
tkill(pid, sig):向pid进程(或线程)发送一个sig号信号 -
tgkill(pid, sig, tgid):向pid进程(或线程)发送一个sig号信号(检查下这个进程的tgid是否等于参数中的tgid)
给一个线程组发送的信号,称为共享信号,给一个进程/线程发送的信号,称为私有信号。
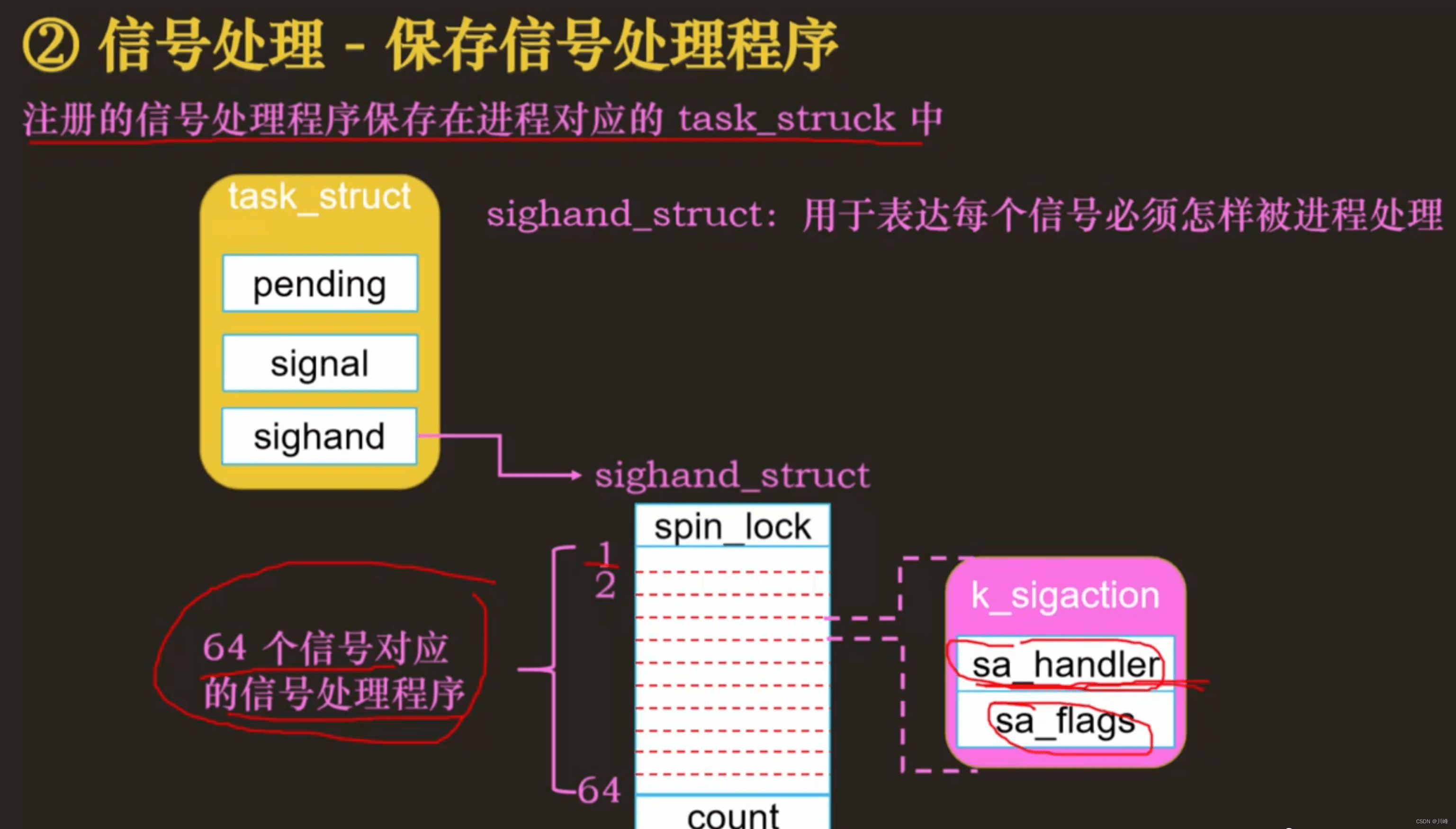
信号已发送,但未处理的信号称为挂起信号,存储在 task_struct 中 。
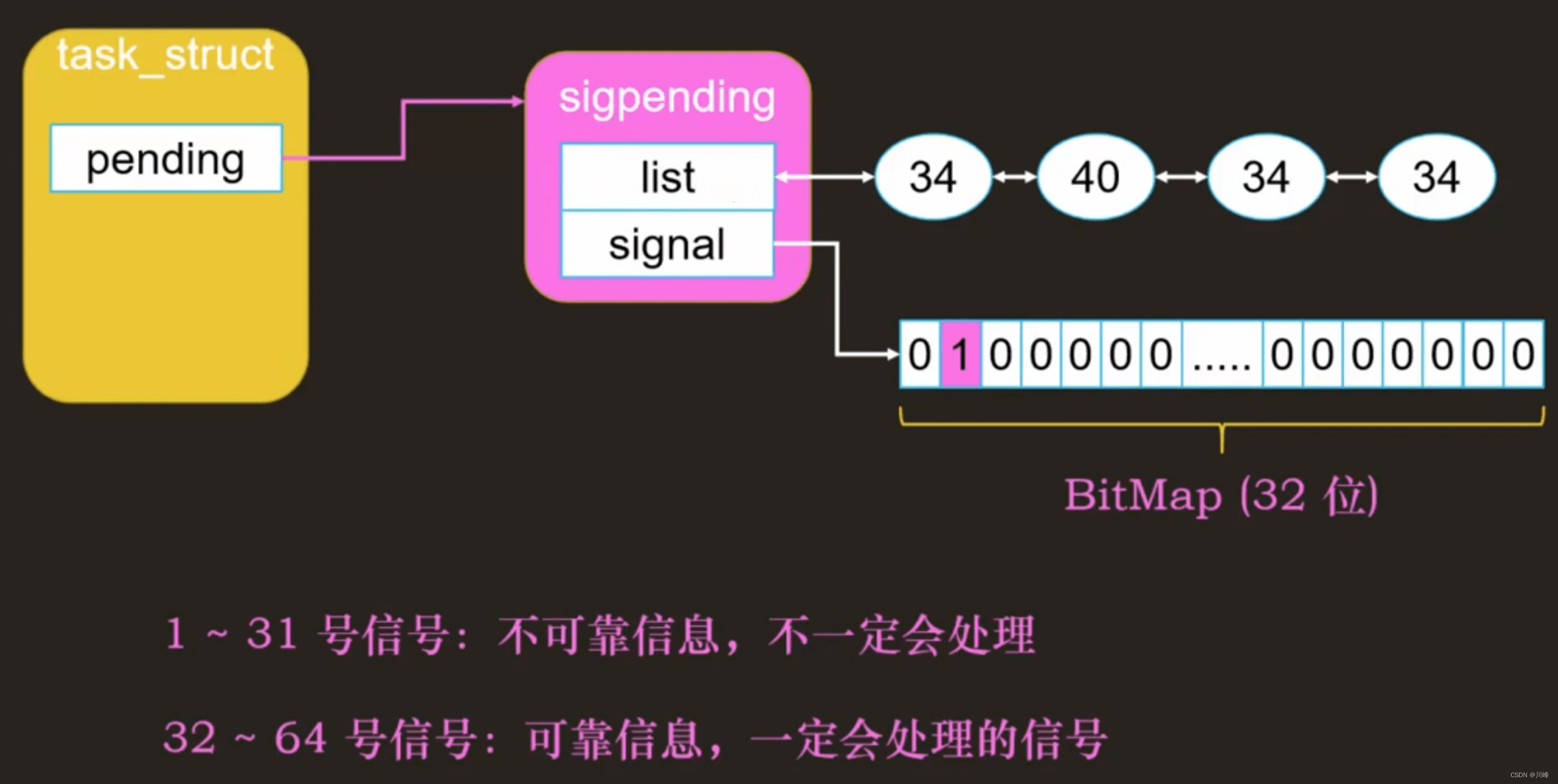
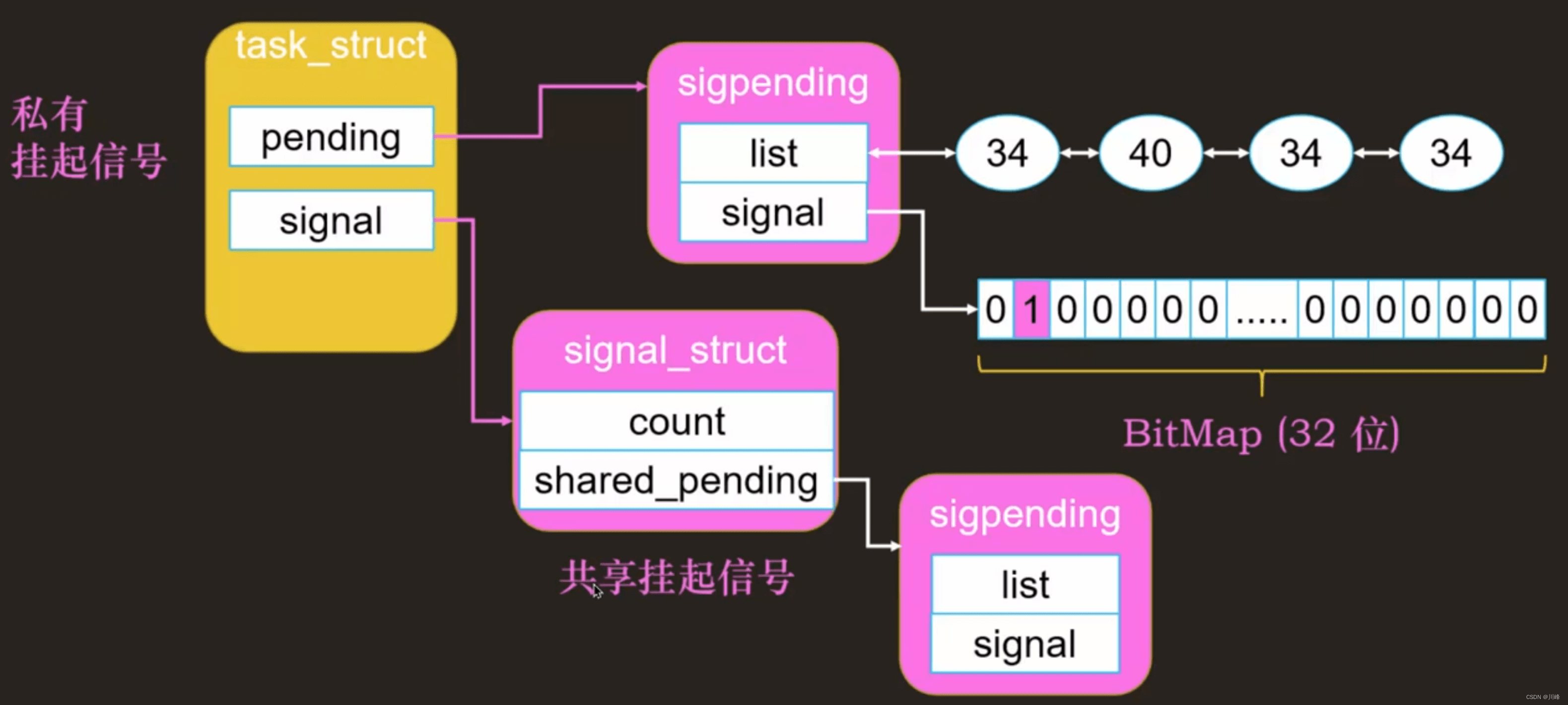
信号处理:
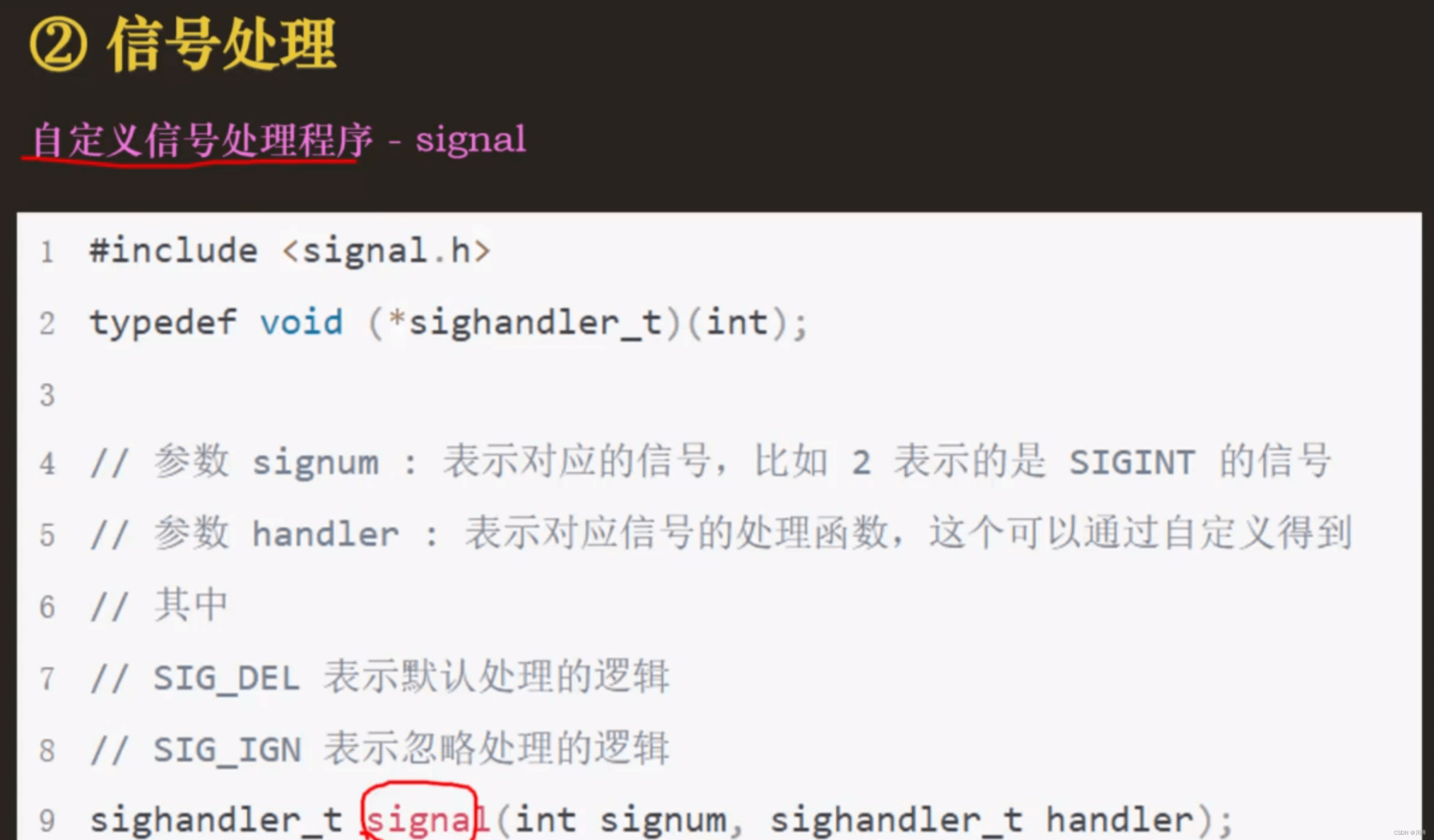
每个信号都有默认的处理方式:
-
① Terminate:终止进程(杀死)
-
② Dump:终止进程(杀死),将进程运行的上下文信息保存到文件中,方便查询进程相关信息
-
③ Ignore:信号被忽略
-
④ Stop:停止进程,将进程的状态设置为
TASK_STOPPED -
⑤ Continue:如果进程的状态是
TASK_STOPPED,那么把它 设置为TASK_RUNNIND

CPU 上下文、进程上下文以及中断上下文
CPU 上下文
在 CPU 执行程序指令的时候,需要一系列的 CPU 寄存器来存储 CPU 计算时要用到的指令、临时数据等。
第一个是指令指针寄存器 (eip 或者 rip),这个其实就是我们平时说的 程序计数器 (PC),它是 CPU 中最重要的寄存器了
- 32 位系统的话,寄存器的名字以
e开头 - 64 位系统的话,寄存器的名字以
r开头
它里面存储的是:下一条需要执行的指令在内存中的虚拟地址。CPU 的工作就是不断从内存中取出它指向指令,然后执行这一条指令,同时将下一条指令在内存的地址存放到指令寄存器中。如此不断重复,这就是 CPU 的工作了。
第二个是通用寄存器,一般用于存储 CPU 执行指令过程中产生的中间数据,一般有下面的寄存器:
- eax / rax:通常用于执行加法,函数调用的返回值一般也放在这里
- ebx / rbx:存放中间临时数据
- ecx / rcx:通常用于计数器
- edx / rdx:用于存放整数除法产生的余数
- esp / rsp:函数调用栈的栈顶指针,指向栈的顶部
- ebp / rbp:函数调用栈的栈底指针,指向栈的底部
- esi / rsi:存放中间临时数据
- edi / rdi:存放中间临时数据
这些通用寄存器是程序执行时最常用的,也是最基础的寄存器,程序执行过程中,绝大部分时间都是在操作这些寄存器来实现指令的功能。
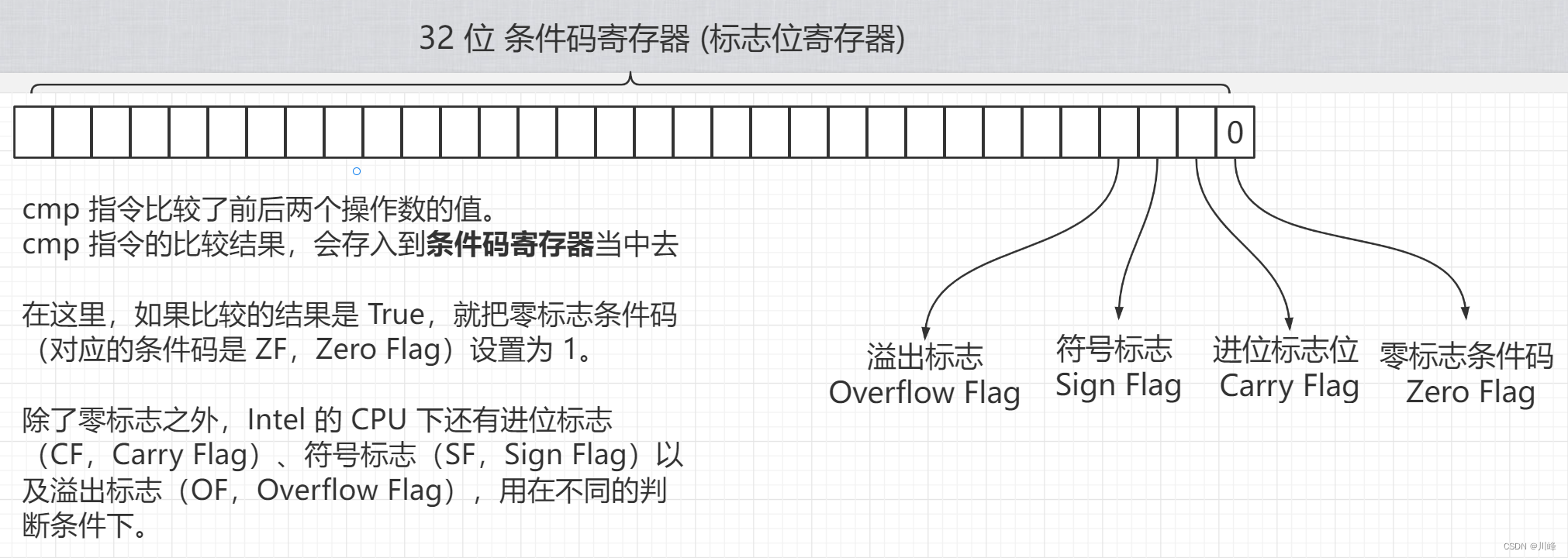
第三个是标志寄存器 (flags),里面有众多标记位,记录了 CPU 执行指令过程中的一系列状态,这些状态大都由 CPU 自动设置。
我们在【操作系统一:程序是如何运行的?】中的第 11 小节 中,讲的 if 语句的汇编指令中,就使用了标记寄存器中的零标志条件码 (Zero Flag) 这一位标志码,来实现程序指令的跳转功能。
第四个是段寄存器,段寄存器用于分段寻址,虽然 Linux 内核采用分页寻址,但是为了保持兼容,段寄存器有些地方仍然在使用,所以,我们还需要关心,段寄存器有 6 个:
- CS:代码段
- DS:数据段
- SS:栈段
- ES:扩展段
- FS
- GS
总结:
-
指令指针寄存器、通用寄存器、标志位寄存器以及段寄存器,这四组寄存器共同构成了一个基本的指令执行环境,也可以称为 CPU 上下文。
-
每个寄存器,CPU 中只有一个,比如指令指针寄存器,在 CPU 中只有一个
-
每个进程在执行的时候,都会有各自的 CPU 上下文信息,也就是说每个进程执行的时候,CPU 中的寄存器的值都有可能不同的
系统调用引起的 CPU 上下文切换
知道了什么是 CPU 上下文,就很容易理解 CPU 上下文切换,CPU 上下文切换就是 CPU 把前一个进程的 CPU 上下文保存起来,然后再加载新的进程的 CPU 上下文,这样,CPU 就可以根据指令指针中存放的新的指令内存地址,执行新的进程了。
其实,CPU 上下文切换就是修改 CPU 中的寄存器的值而已。
保存下来的 CPU 上下文,会存储在系统内核中,但是具体被保存在哪里呢?这个需要看具体的场景,我们先来看看系统调用。
操作系统将进程的运行空间分为内核空间和用户空间:
-
内核空间具有最高的权限,可以直接访问所有的资源
-
用户空间只能访问受限资源,不能直接访问磁盘等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
进程在用户空间运行时,也就是 CPU 执行用户程序代码,被称为进程的用户态。
而陷入内核空间的时候,那么 CPU 将执行内核程序代码,被称为进程的内核态。
从用户态陷入内核态,需要通过系统调用来完成。在系统调用的过程中会发生 两次 CPU 上下文切换:
- 首先将进程的用户态的 CPU 上下文保存到内核栈的
pt_regs中,然后,为了执行内核的代码指令,操作系统需要将 CPU 寄存器的值更新为内核态相关的值,然后开始执行内核态程序 - 当系统调用结束后,将内核栈中的
pt_regs中的用户态的 CPU 上下文,恢复到 CPU 寄存器中,然后切换用户空间,继续运行进程
注意:系统调用过程中一直是在同一个进程中进行的。
进程 / 线程上下文切换
一个进程的上下文信息包含:
- CPU 上下文
- 用户态虚拟内存,即
mm_struct,这个里面包含了进程页表 - TLB 页表项缓存数据
- 磁盘文件信息
- 信号处理信息
- 内核栈
在一个进程里,所有的线程共享进程的资源,比如虚拟内存、磁盘文件、信号处理等,不过线程也有自己的数据,一个线程的上下文包含:
- CPU 上下文
- 线程用户栈
- 线程内核栈
在 Linux 中线程是 CPU 任务调度的最小单位。
一个 CPU 同一时刻只能调度执行一个线程,所以,多线程运行的时候,肯定会出现线程切换。
线程切换又分为三种情况:
- 切换的两个线程是在同一个进程内
- 切换的两个线程不在同一个进程内
- 切换的两个线程有一个是内核线程
接下来我们分别来看下以上三种情况。
第一种情况:切换的两个线程在同一个进程内。 这种情况下需要做下面的几件事:
- 切换 CPU 上下文
- 切换用户栈
- 切换内核栈
第二种情况:切换的两个线程不在同一个进程内。 这种情况下需要做下面的几件事:
- 切换 CPU 上下文
- 切换用户态虚拟内存 (这里会切换用户栈)
- 切换页表
- 刷新 TLB 页表项缓存
- 切换内核栈
可以看出切换两个不在同一个进程的线程,其实就是切换进程上下文了,比切换在同一个进程中的两个线程开销要大。
第三种情况:切换的两个线程中有一个是内核线程。 这种情况下需要做下面的几件事:
- 切换 CPU 上下文
- 切换内核栈
因为内核线程只运行在内核,没有用户空间的虚拟内存,所以不需要切换用户态虚拟内存、不需要切换页表,也就不需要刷新 TLB。这样的话,内核线程切换的开销也不大。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。
而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。
所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、磁盘文件、信号处理等用户态资源。
中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。
同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。
所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
总结
-
CPU 上下文指一组 CPU 寄存器,包括:指令指针寄存器、通用寄存器、标志位寄存器以及段寄存器,不同进程切换时切换 CPU 上下文就是指切换 CPU 寄存器中的值。
-
系统调用会发生 2 次 CPU 上下文切换,从用户态陷入内核态, 首先将进程的用户态的 CPU 上下文保存到内核栈中,然后操作系统需要将 CPU 寄存器的值更新为内核态相关的值,开始执行内核态程序代码指令,当系统调用结束后,将内核栈中的用户态的 CPU 上下文,恢复到 CPU 寄存器中,然后切换用户空间,继续运行进程
-
进程 / 线程上下文切换时,也会发生 CPU 上下文切换:
1)如果是在同一个进程内的两个线程切换,则需要切换CPU上下文、用户栈和内核栈
2)如果是在不同进程的两个线程切换,则需要切换CPU上下文、用户栈和内核栈,还需切换页表,刷新TLB页表项缓存,此时就是切换两个进程
3)如果切换的两个线程中有一个是内核线程,则只需要切换CPU上下文和内核栈,因为内核线程只运行在内核,没有用户空间的虚拟内存,所以不需要切换用户态虚拟内存、不需要切换页表
-
中断上下文切换不会涉及进程的用户态,只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等









