目录
前言:
1.数组名的意义:
- sizeof(数组名):这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
- &数组名:这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。
2.地址在内存中唯一标识一块空间,大小是4/8个字节。在32位平台下(X86环境)是4字节,64位平台下(X64环境)是8字节。
3.sizeof是操作符,计算的是对象或者类型创建的对象所占内存空间的大小,单位是字节,它不会关注内存中存放的到底是什么。
4.strlen是库函数,求的是字符串长度,本质上是统计字符串中\0之前出现的字符个数。
1.一维数组:
int main()
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a + 0));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a));
printf("%d\n", sizeof(*&a));
printf("%d\n", sizeof(&a + 1));
printf("%d\n", sizeof(&a[0]));
printf("%d\n", sizeof(&a[0] + 1));
return 0;
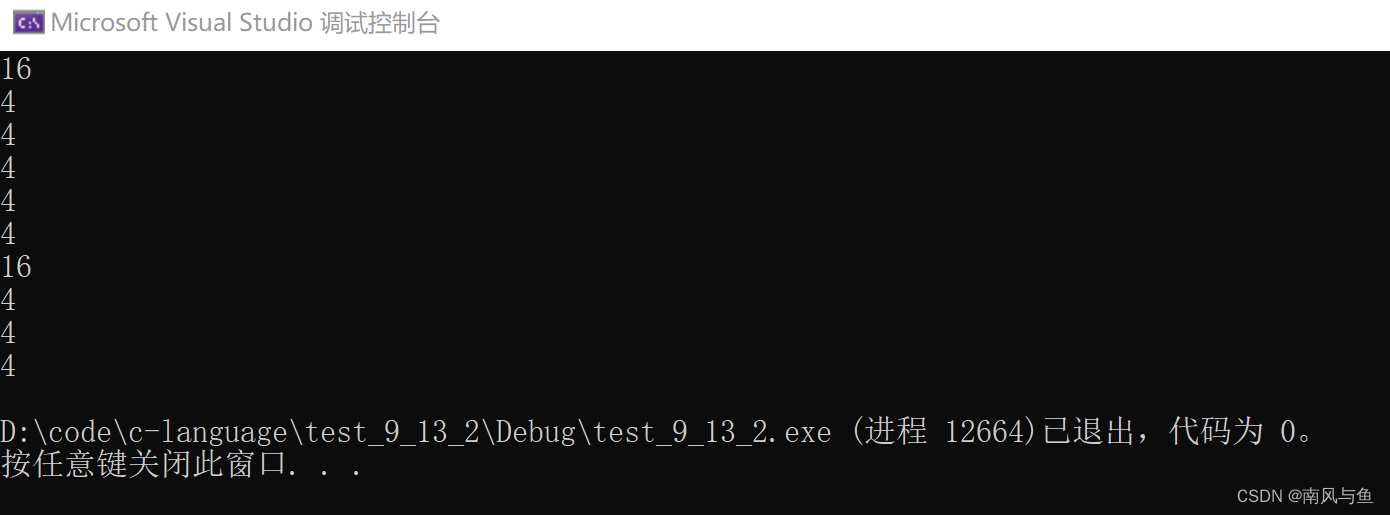
}运行结果:
🎈解析:
printf("%d\n",sizeof(a));数组名a单独放在sizeof内部,数组名表示整个数组,计算的是整个数组的大小,单位是字节,所以是16字节
printf("%d\n",sizeof(a[0][0]));a并非单独放在sizeof内部,也没有&,所以数组名是数组首元素的地址,即a+0还是首元素的地址,是地址大小就是4/8字节
printf("%d\n", sizeof(*a));a并非单独放在sizeof内部,也没有&,所以数组名是数组首元素的地址,*a就是首元素,也可以写成*a == *(a+0) == a[0],大小就是4字节
printf("%d\n", sizeof(a + 1));a并非单独放在sizeof内部,也没有&,所以数组名是数组首元素的地址,a+1就是第二个元素的地址,a+1 == &a[1],是第二个元素的地址,是地址大小就是4/8字节
printf("%d\n", sizeof(a[1]));a[1]就是数组的第二个元素,这里计算的就是第二个元素的大小,单位是字节,为4字节
printf("%d\n", sizeof(&a));&a是取出数组的地址,但是数组的地址也是地址,是地址就是4/8个字节,数组的地址和数组首元素的地址的本质区别是类型的区别,并非大小的区别
a --- int* int * p = a;
&a --- int (*)[4] int (*p)[4] = &a;
printf("%d\n", sizeof(*&a));1.对数组指针解引用访问一个数组的大小,单位是字节,所以是16字节
2.还可以理解为sizeof(*&a) 等价于 sizeof(a)
printf("%d\n", sizeof(&a + 1));&a是数组的地址,&a+1还是地址,是地址就是4/8个字节
printf("%d\n", sizeof(&a[0]));&a[0]就是取出首元素的地址,计算的是地址的大小,就是4/8个字节
printf("%d\n", sizeof(&a[0] + 1));&a[0]是首元素的地址,&a[0] + 1就是第二个元素的地址,大小是4/8个字节
&a[1] 、&a[0] + 1、a+1都可以取出第二个元素的地址
2.字符数组 :
2.1题型一:
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));
return 0;
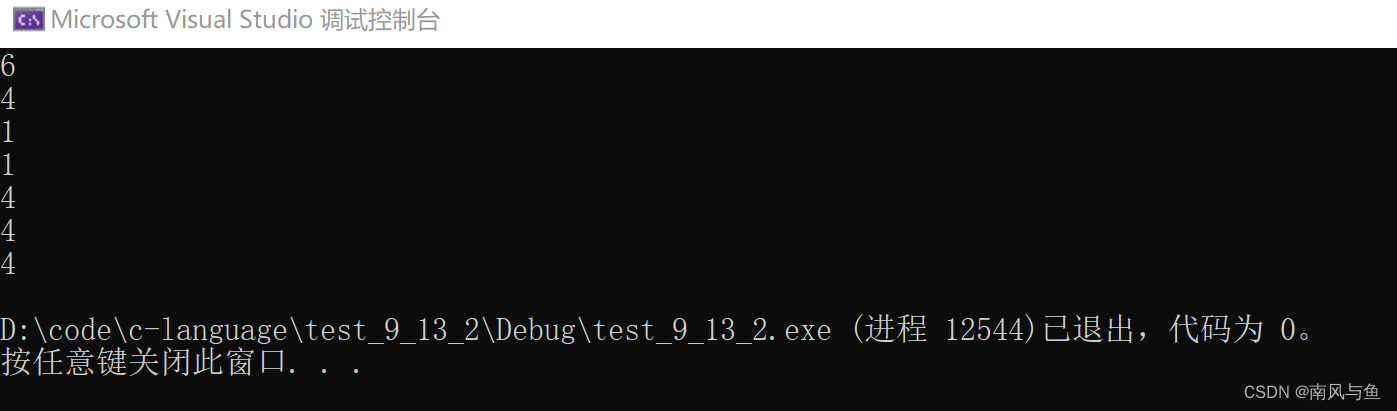
}运行结果:
🎈解析:
printf("%d\n", sizeof(arr));数组名arr单独放在sizeof内部,计算的是整个数组的大小,就是6字节
printf("%d\n", sizeof(arr+0));arr是首元素的地址==&arr[0],是地址就是4/8个字节
注意:
1. 指针变量的大小和类型无关,不管什么类型的指针变量,大小都是4/8个字节
2.指针变量是用来存放地址的,地址存放需要多大空间,指针变量的大小就是几个字节
3.32位环境下,地址是32个二进制位,需要4个字节,所以指针变量的大小就是4个字节
4.64位环境下,地址是64个二进制位,需要8个字节,所以指针变量的大小就是8个字节
💘不要门缝里看指针,把指针看扁喽
printf("%d\n", sizeof(*arr));arr是首元素的地址,*arr就是首元素,大小就是1字节
printf("%d\n", sizeof(arr[1]));arr[1]是首元素,大小就是1字节
printf("%d\n", sizeof(&arr));&arr是数组的地址,大小就是4/8个字节
printf("%d\n", sizeof(&arr+1));&arr+1是跳过数组后的地址,是地址就是4/8个字节
printf("%d\n", sizeof(&arr[0]+1));&arr[0]是第一个元素的地址,+1就是第二个元素的地址,是地址就是4/8个字节
🎈下面我们将这个代码稍微变动一下,将sizeof变为strlen,我们再来分析一下 :
注:strlen函数求的是字符串长度,统计的是在字符串中\0之前出现的字符的个数
#include <string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };//末尾没有\0
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
//printf("%d\n", strlen(*arr));//err
//printf("%d\n", strlen(arr[1]));//err
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
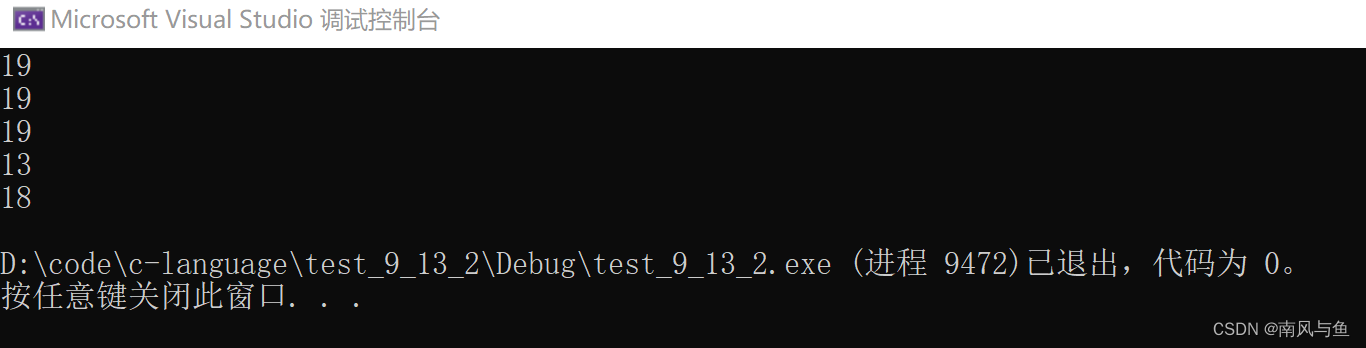
}运行结果:
🎈解析:
printf("%d\n", strlen(arr));arr是首元素的地址,从首元素向后找,找不到\0,所以它的长度就为随机值
printf("%d\n", strlen(arr+0));arr是首元素的地址,arr+0还是首元素的地址,所以它的长度也为随机值
printf("%d\n", strlen(*arr));arr是首元素的地址,*arr就是首元素-> 'a' -> 97,站在strlen的角度,认为传参进去的 'a' -> 97就是地址,97作为地址,直接进行访问,就是非法访问,所以这是一个错误代码
printf("%d\n", strlen(arr[1]));arr[1]就是第二个元素 'b' -> 98,98作为地址,直接进行访问,就是非法访问,所以这也是一个错误代码
printf("%d\n", strlen(&arr));&arr取出的类型是char (*)[6](数组指针类型),strlen 的类型是const char*,将&arr的类型传给strlen类型必然会进行类型的转换,编译器会报警告,但是传参的时候只是类型发生了变化,值不变,所以还是从第一个元素开始向后找,找不到\0,它的长度也为随机值
printf("%d\n", strlen(&arr+1));&arr取出的是整个数组的地址,+1跳过整个数组,向后找还是找不到\0,所以它的长度也为随机值
printf("%d\n", strlen(&arr[0]+1));&arr[0]取出的是第一个元素的地址,+1后指向第二个元素,从第二个元素向后还是找不到\0,所以它的长度也为随机值
2.2题型二:
int main()
{
char arr[] = "abcdef";//a b c d e f \0
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
return 0;
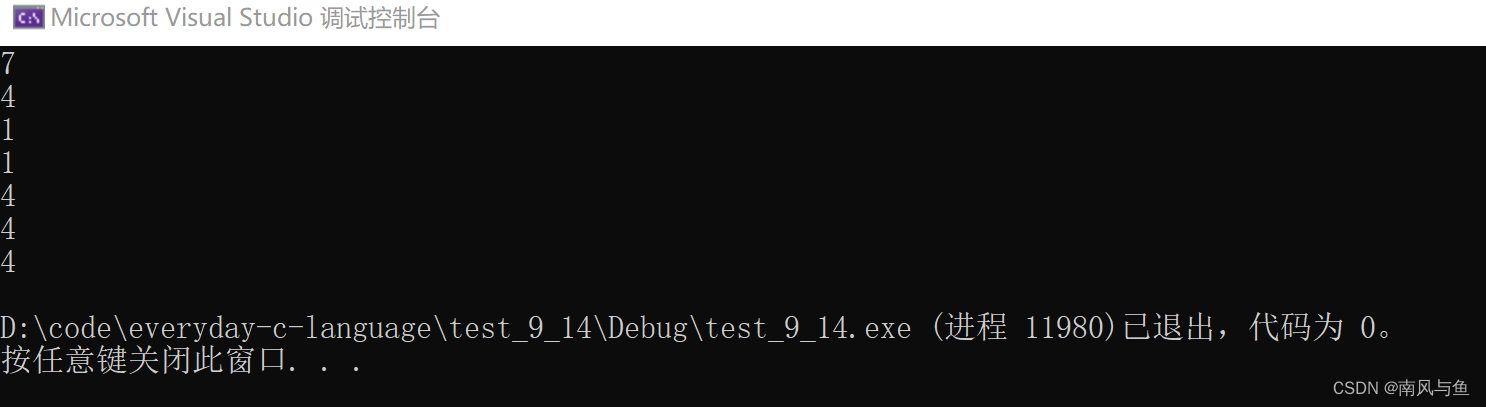
}运行结果:
🎈解析:
printf("%d\n", sizeof(arr));sizeof(arr)计算的是整个数组的大小,加上\0为7个字节
printf("%d\n", sizeof(arr+0));arr是首元素的地址,加0还是首元素的地址,是地址大小就为4/8个字节
printf("%d\n", sizeof(*arr));arr是数组名,是首元素的地址,给它解引用就是首元素 'a' ,它的大小就是1个字节
printf("%d\n", sizeof(arr[1]));arr[1]就是第二个元素,它的大小也是1字节
printf("%d\n", sizeof(&arr));&arr取出的是数组的地址,数组的地址也是地址,是地址就是4/8个字节
printf("%d\n", sizeof(&arr+1));&arr取出的是数组的地址,加1跳过整个数组,还是地址,大小就是4/8个字节
printf("%d\n", sizeof(&arr[0]+1));&arr[0]是第一个元素的地址,加1就是第二个元素的地址,是地址就是4/8个字节
🎈下面我们再来将这个代码变动一下,将sizeof变为strlen
#include <string.h>
int main()
{
char arr[] = "abcdef";
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
//printf("%d\n", strlen(*arr));//err
//printf("%d\n", strlen(arr[1]));///err
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
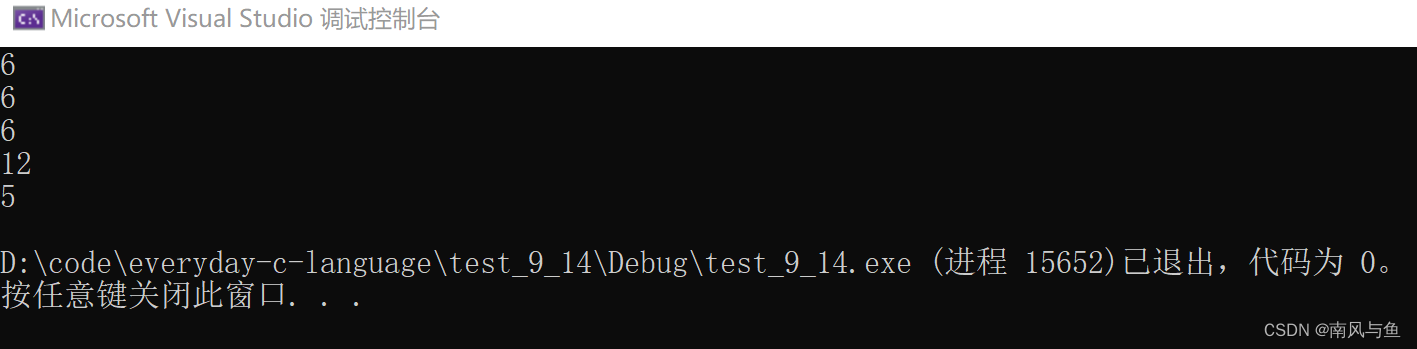
}运行结果:
🎈解析:
printf("%d\n", strlen(arr));arr是数组名,即首元素地址,从首元素向后数,统计\0之前的字符,长度为6
printf("%d\n", strlen(arr+0));arr是数组名,为首元素地址,加0还是首元素地址,从首元素向后数,统计\0之前的字符,长度也为6
printf("%d\n", strlen(*arr));arr是首元素地址,对首元素地址解引用得到的就是首元素,传给strlen的就是字符'a',即97,所以这是个错误代码
printf("%d\n", strlen(arr[1]));arr[1]是这个数组的第二个元素,即把字符'b'传了进去,所以它也是个错误代码
printf("%d\n", strlen(&arr));&arr取出的是整个数组的地址,但它也是从a向后数,直到\0截至,所以它的长度为6
printf("%d\n", strlen(&arr+1));&arr+1是跳过整个数组,包括后边的\0,从\0后边开始数,不确定什么时候会遇到\0,所以它的长度为随机值
printf("%d\n", strlen(&arr[0]+1));&arr[0]+1得到的是第二个元素的地址,从第二个元素开始向后数,得到的长度就是5
2.3题型三:
int main()
{
//把字符串首字符的地址放到了p里边去,也就是说p指向了"abcdef"
char* p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p + 1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p + 1));
printf("%d\n", sizeof(&p[0] + 1));
return 0;
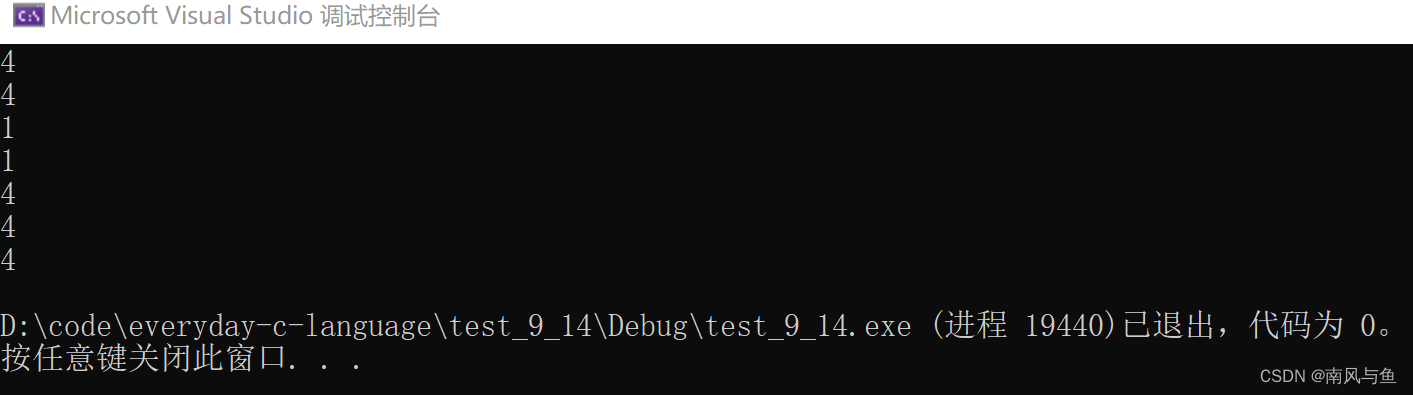
}运行结果:
🎈解析:
printf("%d\n", sizeof(p));p是一个指针变量,计算的就是指针变量的大小,就是4/8字节
printf("%d\n", sizeof(p+1));p是一个char*的指针,+1向后偏移一个字节,但它本质上还是一个地址,大小是4/8个字节
printf("%d\n", sizeof(*p));p是char*的指针,解引用访问一个字节,所以它的大小就是1字节
printf("%d\n", sizeof(p[0]));p[0] ---> *(p+0) ---> *p == 'a',所以它的大小也是1字节
printf("%d\n", sizeof(&p));&p也是地址(指针变量p的起始地址),大小也是4/8个字节
printf("%d\n", sizeof(&p+1));&p是地址,&p+1还是地址,是地址就是4/8个字节
printf("%d\n", sizeof(&p[0]+1));&p[0]是第一个元素的地址,&p[0]+1就是第二个元素的地址,大小就是4/8个字节
🎈 将sizeof变为strlen,我们继续分析:
int main()
{
char* p = "abcdef";//a b c d e f \0
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));
return 0;
}🎈解析:
printf("%d\n", strlen(p));p指向了字符串中的首字符'a',从a向后数,截至到\0,长度就为6
printf("%d\n", strlen(p + 1));p+1跳过一个字节,从第二个元素向后数,长度就是5
printf("%d\n", strlen(*p));p指向字符串中第一个元素的位置,解引用就是'a',所以这是个错误代码
printf("%d\n", strlen(p[0]));p[0]也是第一个元素,传给strlen的也是'a'的ASCII码值,错误代码
printf("%d\n", strlen(&p));&p指向了指针变量p的起始地址,在这个内存里边有没有\0以及什么时候遇到\0完全是不可知的,所以它的长度就是一个随机值
printf("%d\n", strlen(&p + 1));&p+1是跳过p,指向的下一块内存后续空间有什么也是不可知的,所以它的长度也是随机值
printf("%d\n", strlen(&p[0] + 1));&p[0]+1就是第二个元素的地址,从第二个元素向后数长度就是5
3.二维数组 :
二维数组在内存中的存放形式为:

但我们平常可以将它的存放理解成这样:
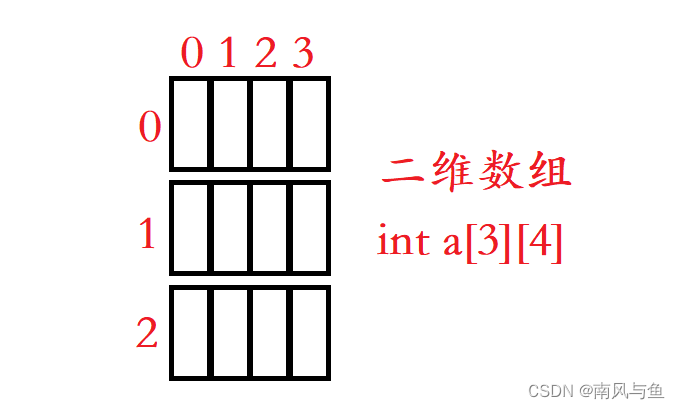
🎈注意:一维数组的数组名通常表示首元素的地址,二维数组的数组名通常表示第一行的地址。二维数组的数组名单独放在sizeof内部表示整个数组。
int main()
{
int a[3][4] = { 0 };
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a[0][0]));
printf("%zd\n", sizeof(a[0]));
printf("%zd\n", sizeof(a[0] + 1));
printf("%zd\n", sizeof(*(a[0] + 1)));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(*(a + 1)));
printf("%zd\n", sizeof(&a[0] + 1));
printf("%zd\n", sizeof(*(&a[0] + 1)));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a[3]));
return 0;
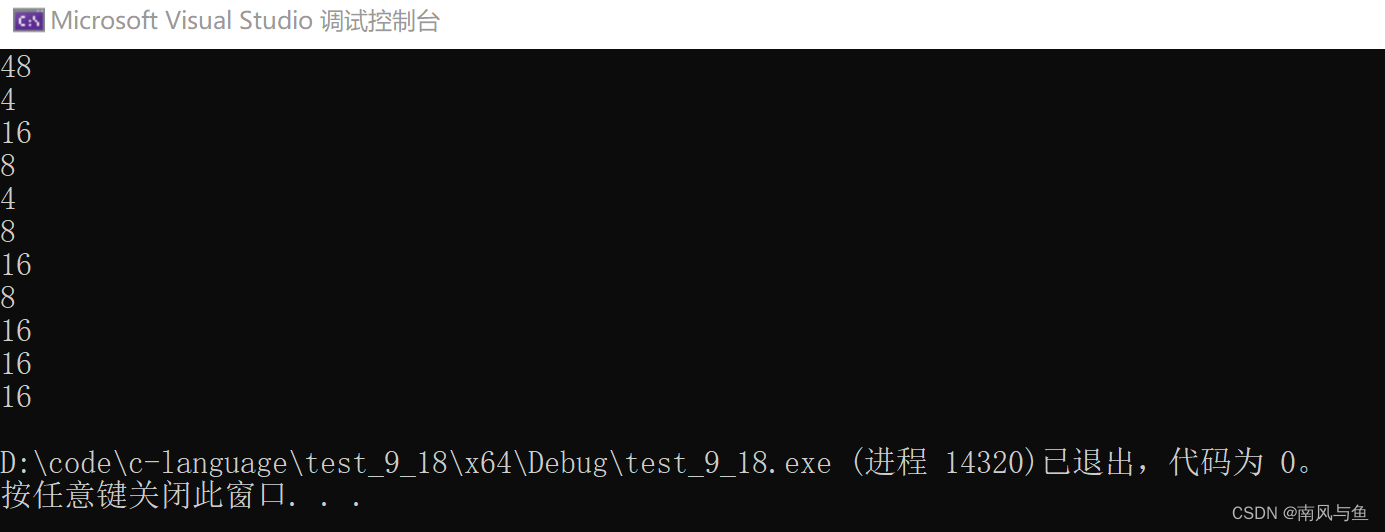
}运行结果:
🎈解析:
printf("%zd\n", sizeof(a));数组名a单独放在了sizeof 内部,表示整个数组,sizeof(a)计算的是数组的大小,单位是字节,所以它的大小就是3x4x12=48字节
printf("%zd\n", sizeof(a[0][0]));a[0][0] 是数组的第一行第一个元素,这里计算的就是一个元素的大小,所以是4字节
printf("%zd\n", sizeof(a[0]));a[0]是第一行这个一维数组的数组名,数组名单独放在sizeof内部,a[0]就表示整个第一行这个一维数组,sizeof(a[0])计算的整个第一行这个一维数组的大小就为4x4=16字节
printf("%zd\n", sizeof(a[0] + 1));a[0]并非单独放在sizeof内部,也没有&, a[0]就表示第一行这个一维数组首元素的地址,也就是第一行第一个元素的地址,+1表示第一行第二个元素的地址,是地址就是4/8个字节
printf("%zd\n", sizeof(*(a[0] + 1)));a[0]+1表示第一行这个一维数组第二个元素的地址,对其进行解引用操作,得到第一行第二个元素,所以大小为4字节
printf("%zd\n", sizeof(a + 1));a作为二维数组的数组名,并没有单独放在sizeof内部,也没有&,那a就是数组首元素的地址,也就是第一行的地址,类型是int(*)[4],a+1就是第二行的地址,大小为4/8字节
printf("%zd\n", sizeof(*(a + 1)));a+1表示第二行的地址,对其解引用,就表示整个第二行数组的大小,为16字节
printf("%zd\n", sizeof(&a[0] + 1));a[0]是第一行的数组名,&a[0]取出的就是第一行这个一维数组的地址,类型为int (*)[4],+1就是第二行的地址,是地址大小就为4/8字节
printf("%zd\n", sizeof(*(&a[0] + 1)));*(&a[0] + 1)得到的是第二行,计算的就是第二行的大小,为16字节
printf("%zd\n", sizeof(*a));a表示数组首元素的地址,也就是第一行的地址,*a就是第一行,相当于第一行的数组名,大小就为16字节
printf("%zd\n", sizeof(a[3]));
表达式有两个属性:1.值属性 2.类型属性;a[3]是二维数组的第四行,虽然这个数组没有第四行,但是它的类型能够确定,大小就是确定的,所以为16字节







