1. 前言
由于工作因素,经常要对多个文档内容进行查重,文字类可以借助查重工具辅助,但图片和表格只能依靠鼠标滚轮还有笔者的打工眼。久而久之,眼睛废了,肩颈也吃不消了(-.-)。于是乎,就想用脚本批量导出,从而提高效率。
笔者非软件专业,所以只能请ChatGPT当导师了,经过多次修改,总算达到了预期效果。
大佬们如果有更好的办法,还请与我联系……下面是操作步骤。
2.安装python环境
官网下载: https://www.python.org/downloads/windows/
网上找个教程安装下去,命令行输入python能回显版本即可。
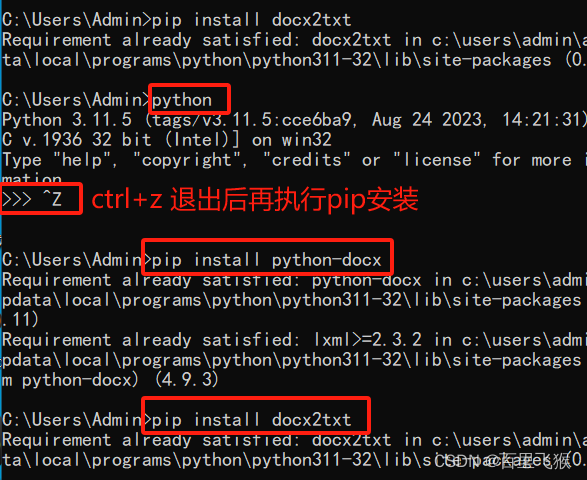
快捷键Ctrl+Z 退出python界面,而后安装pythone的docx、docx2txt 库
pip install python-docx
pip install docx2txt
3. python脚本
import os
from docx import Document
import docx2txt
from docx.enum.table import WD_ALIGN_VERTICAL
def extract_images_and_tables(input_docx_file, output_folder):
# 创建输出文件夹
folder_name = os.path.splitext(os.path.basename(input_docx_file))[0]
output_folder = os.path.join(output_folder, folder_name)
os.makedirs(output_folder, exist_ok=True)
# 提取Word文档中的图片并保存到输出文件夹
docx2txt.process(input_docx_file, output_folder)
# 提取Word文档中的表格并保存到一个单独的文件
doc = Document(input_docx_file)
table_output_path = os.path.join(output_folder, "02-文档表格.docx") # 修改文件名
table_doc = Document()
for table in doc.tables:
new_table = table_doc.add_table(rows=len(table.rows), cols=len(table.columns))
# 复制表格样式和内容
for i, row in enumerate(table.rows):
for j, cell in enumerate(row.cells):
new_cell = new_table.cell(i, j)
# 复制单元格的文本和样式
for paragraph in cell.paragraphs:
new_paragraph = new_cell.add_paragraph(paragraph.text)
new_paragraph.alignment = paragraph.alignment
new_paragraph.vertical_alignment = WD_ALIGN_VERTICAL.CENTER
for run in paragraph.runs:
new_run = new_paragraph.runs[-1] # 使用最后一个Run来避免样式重叠
new_run.bold = run.bold
new_run.italic = run.italic
new_run.underline = run.underline
new_run.font.size = run.font.size
new_run.font.name = run.font.name
new_run.font.color.rgb = run.font.color.rgb
table_doc.save(table_output_path)
print(f"提取了所有表格并保存到 {table_output_path}")
# 提取大纲标题并生成目录文档
outline_output_path = os.path.join(output_folder, "01-文档目录.docx") # 修改文件名
outline_doc = Document()
for paragraph in doc.paragraphs:
if paragraph.style.name.startswith('Heading'):
level = int(paragraph.style.name.split()[-1])
outline_doc.add_paragraph(paragraph.text, style=f'Heading {level}')
outline_doc.save(outline_output_path)
print(f"生成了目录并保存到 {outline_output_path}")
if __name__ == "__main__":
input_folder = r"D:\01-待提取文档文件夹" # 待提取文档的所在路径
output_folder = r"D:\02-保存文档文件夹" # 保存提取后文档的所在路径
docx_files = [os.path.join(input_folder, filename) for filename in os.listdir(input_folder) if filename.endswith(".docx")]
for docx_file in docx_files:
extract_images_and_tables(docx_file, output_folder)
4. 执行效果
================ RESTART: C:\Users\Admin\Desktop\测试脚本.py ================
提取了所有表格并保存到 D:\02-保存文档文件夹\01-我是文档A\02-文档表格.docx
生成了目录并保存到 D:\02-保存文档文件夹\01-我是文档A\01-文档目录.docx
提取了所有表格并保存到 D:\02-保存文档文件夹\02-我是文档B\02-文档表格.docx
生成了目录并保存到 D:\02-保存文档文件夹\02-我是文档B\01-文档目录.docx
提取了所有表格并保存到 D:\02-保存文档文件夹\03-我是文档C\02-文档表格.docx
生成了目录并保存到 D:\02-保存文档文件夹\03-我是文档C\01-文档目录.docx
提取了所有表格并保存到 D:\02-保存文档文件夹\04-我是文档D\02-文档表格.docx
生成了目录并保存到 D:\02-保存文档文件夹\04-我是文档D\01-文档目录.docx