文章目录
- 一、定义
- 二、经典例题
- (一)[21.合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/description/)
- (二)[86.分割链表](https://leetcode.cn/problems/partition-list/description/)
- (三)[23.合并 K 个升序链表](https://leetcode.cn/problems/merge-k-sorted-lists/description/)
- (四)[19.删除链表中的倒数第N个节点](https://leetcode.cn/problems/remove-nth-node-from-end-of-list/)
一、定义
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
二、经典例题
(一)21.合并两个有序链表
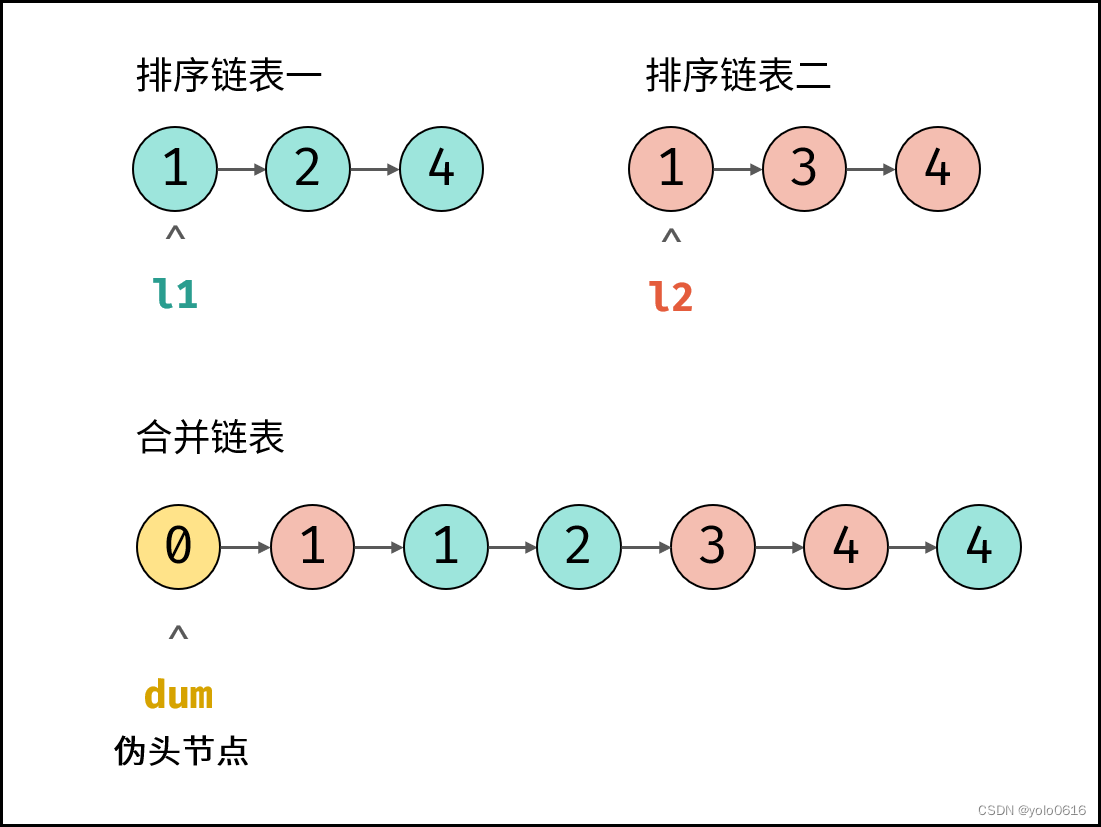
1.思路
根据题目描述,链表l1, l2是递增的,因此容易想到使用双指针cur1和cur2遍历两链表,根据cur1.val和cur2.val的大小关系确定节点添加顺序,两节点指针交替前进,直至遍历完毕。
同时因为两个链表都是有序的,所以,当我们遍历完一个链表,剩下的那个链表如果没到结尾,可以直接跟上。
2.复杂度分析
时间复杂度 O(M+N) : M,N别为两个链表的长度,合并操作需遍历两链表。
空间复杂度 O(1): 节点引用 dum , cur使用常数大小的额外空间。
3.注意
Dummy节点的作用是作为一个虚拟的头前节点。在不知道要返回的新链表的头结点是哪一个,它可能是原链表的第一个节点,可能在原链表的中间,也可能在最后,甚至不存在(nil)。引入Dummy节点可以涵盖所有情况,并且可以使用dummy.next返回最终需要的头结点。
4.代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* cur1 = list1;
ListNode* cur2 = list2;
ListNode* dummy = new ListNode(-1); // 虚拟头结点
ListNode* cur = dummy;
while (cur1 && cur2) {
// 比较 p1 和 p2 两个指针
// 将值较小的的节点接到 p 指针
if (cur1 -> val > cur2 -> val) {
cur -> next = cur2;
cur2 = cur2 -> next;
}
else {
cur -> next = cur1;
cur1 = cur1 -> next;
}
cur = cur -> next; // p 指针不断前进
}
if (cur1) cur -> next = cur1;
if (cur2) cur -> next = cur2;
return dummy -> next;
}
};
(二)86.分割链表
1.思路
具体来说,我们可以把原链表分成两个小链表,一个链表中的元素大小都小于 x,另一个链表中的元素都大于等于 x,最后再把这两条链表接到一起,就得到了题目想要的结果。
2.复杂度分析
时间复杂度 O(N): 其中 N为链表长度;遍历链表使用线性时间。
空间复杂度 O(1) : 假头节点使用常数大小的额外空间。
3.代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
ListNode* dummy1 = new ListNode(-1);
ListNode* dummy2 = new ListNode(-1);
ListNode* small = dummy1;
ListNode* big = dummy2;
// 新建两个链表 small,big,分别用于添加所有节点值<x、节点值>=的节点
ListNode* cur = head;
while (cur) {
if (cur -> val >= x) {
big -> next = cur;
big = big -> next;
}
else {
small -> next = cur;
small = small -> next;
}
cur = cur -> next;
}
small -> next = dummy2 -> next; // 拼接 small 和 big
big -> next = nullptr;
return dummy1 -> next;
}
};
(三)23.合并 K 个升序链表
1.思路
如何快速得到 k 个节点中的最小节点,接到结果链表上?
- 这里我们就要用到 优先级队列(二叉堆) 这种数据结构,把链表节点放入一个最小堆,就可以每次获得 k 个节点中的最小节点:
优先队列 pq 中的元素个数最多是 k,所以一次 poll 或者 add 方法的时间复杂度是 O(logk);所有的链表节点都会被加入和弹出 pq,所以算法整体的时间复杂度是 O(Nlogk),其中 k 是链表的条数,N 是这些链表的节点总数。
2.复杂度分析
时间复杂度:考虑优先队列中的元素不超过 k 个,那么插入和删除的时间代价为 O(logk),这里最多有 kn 个点,对于每个点都被插入删除各一次,故总的时间代价即渐进时间复杂度为 O(kn×logk)。
空间复杂度:这里用了优先队列,优先队列中的元素不超过 k个,故渐进空间复杂度为 O(k)。
3.代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
// 时间复杂度 : O(n ∗ log(k))
ListNode* mergeKLists(vector<ListNode*>& lists) {
if (lists.size() == 0) return nullptr;
ListNode* dummy = new ListNode(-1);
ListNode* p = dummy;
priority_queue<ListNode*, vector<ListNode*>, function<bool(ListNode*, ListNode*)>> pq(
[] (ListNode* a, ListNode* b) { return a->val > b->val; });
for (auto head : lists) {
if (head != nullptr) pq.push(head);
}
while (!pq.empty()) {
ListNode* node = pq.top();
pq.pop();
p -> next = node;
if (node -> next != nullptr)
pq.push(node->next);
p = p -> next;
}
return dummy -> next;
}
};
(四)19.删除链表中的倒数第N个节点
1.思路
假设链表有 n 个节点,倒数第 k 个节点就是正数第 n - k + 1 个节点。
是的,但是算法题一般只给你一个 ListNode 头结点代表一条单链表,你不能直接得出这条链表的长度 n,而需要先遍历一遍链表算出 n 的值,然后再遍历链表计算第 n - k + 1 个节点。
也就是说,这个解法需要遍历两次链表才能得到出倒数第 k 个节点。
2.复杂度分析
3.代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
if (head == nullptr || n == 0) return nullptr;
ListNode* dummy = new ListNode(-1);
dummy -> next = head;
ListNode* x = findFromEnd(dummy, n + 1);
x -> next = x -> next -> next;
return dummy -> next;
}
ListNode* findFromEnd(ListNode* head, int k) {
// 代码见上文
ListNode* slow = head;
ListNode* fast = head;
while (k -- && fast) {
fast = fast -> next;
}
while (fast) {
slow = slow -> next;
fast = fast -> next;
}
return slow;
}
};



