目录
1、模拟实现qsort函数
1.1、qsort函数的回顾
要模拟实现qsort函数,就要了解清楚qsort函数的参数以及使用方式。
我们先回顾一下qsort函数:
qsort是一个库函数,底层使用的是快速排序的方式对数据进行排序。头文件:<stdlib.h>
这个函数可以直接使用用来排序任意类型的数据。

qsort函数定义原型:
void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const void*));
- void* base:待排序数组的第一个元素的地址
- size_t num:待排序数组的元素个数
- size_t size:以字节为单位,待排序数组中一个元素的大小。
- int (*compar)(const void*,const void*):函数指针,指向一个比较函数,用来比较两个元素,由用户自行创建并封装。
形参中为什么用的是void*:
void* 是无具体类型的指针,不能进行解引用操作符,也不能进行+-整数的操作,它是用来存放任意类型数据的地址(可以理解为垃圾桶,什么都能装,当需要用时再强制类型转换为需要的类型)。只有void*被允许存放任意类型数据的地址,如果是其他类型的指针编译器会报错。正是因为定义qsort函数时用的是void*,qsort函数才可以排序任意类型的数据。
1.2、模拟实现qsort函数
使用【冒泡排序】的算法,模拟实现一个排序函数 bsort ,可以用来排序任意类型的数据。
首先,先用冒泡排序实现排序整型数据:
void bsort(int arr[], int sz)
{
int i = 0;
for ( i = 0; i < sz - 1; i++)
{
int j = 0;
for ( j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
bsort(arr, sz);
int i = 0;
for ( i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}在这个冒泡排序排序整型数据的代码的基础上进行改造。
首先改造的第一部分就是函数参数,这里的函数参数被写死了只能进行int类型的排序,因此为了让其他类型的数据也能够传入到bsort函数中进行排序,我们这里需要使用指针来接收传入参数。
参数一:而指针的选择上又只有 void* 最为符合,因为它是用来存放任意类型数据的地址(可以理解为垃圾桶,什么都能装,当需要用时再强制类型转换为需要的类型)。
参数二:对照库函数qsort的定义中,第二个参数为待排序数组的元素个数,因此我们也用个 size_t num 存放待排序数组的元素个数。
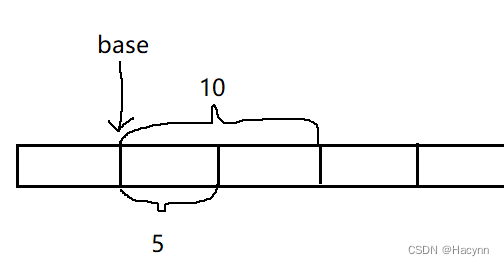
当前,我们可以通过参数一和参数二知道起始位置地址(void* base)和元素个数(num),但是仅仅知道起始地址和元素个数是不够的,因为不知道一个元素有多大的,一次需要跳过多少个字节,5个?10个?
参数三:因此还需要一个参数记录一个元素的大小 size_t size。
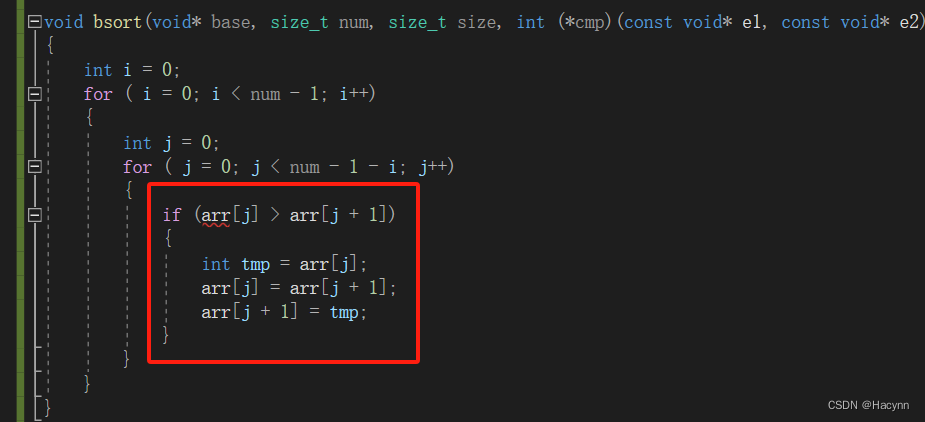
到此,我们先把注意里放在函数内部,函数内部循环的趟数和一趟的次数是不需要改造的,只有红色框框内的交换区域需要改造,因为整数的大小可以用><=号比较,但是结构体数据是不能直接使用><=号来比较的。排序一个整型需要整型的方法,排序一个结构体需要结构体的方法,因此如果需要排序各种各样的类型时,不能固定写死交换区域的比较方式,这就需要用户自行创建比较函数来实现。
参数四:而我们这里只需要使用函数指针 int (*cmp)(const void* e1,const void* e2) 接收用户传递的比较函数即可。e1和 e2都是指针,分别存放着一个要比较的元素的地址。
对红框区域进行修改:
注意,在cmp函数中传入base参数时,需要对base强制类型转换char*,因为只有char的步长最短,可以满足所有类型的交换。假设是int类型的话,+1直接跳过4个字节,那么如果要交换一个char类型或者short类型的数据,那就无法做到交换了。
【交换int类型数据的完整代码】
swap(char* buf1, char* buf2, size_t size)
{
一个字节一个字节地交换
int i = 0;
for ( i = 0; i < size; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
//模拟库函数qsort
void bsort(void* base, size_t num, size_t size, int (*cmp)(const void* e1, const void* e2))
{
int i = 0;
for ( i = 0; i < num - 1; i++)
{
int j = 0;
for ( j = 0; j < num - 1 - i; j++)
{
//if(arr[j]>arr[j+1])
if (cmp((char*)base + size * j, (char*)base + size * (j + 1)) > 0) //大于0时,证明j的元素大于j+1的元素,所以要交换位置
{
//交换
swap((char*)base + size * j, (char*)base + size * (j + 1), size);
}
}
}
}
//用户自行创建
int cmp_in(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
bsort(arr, sz,sizeof(arr[0]),cmp_in);
int i = 0;
for ( i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}【图解】
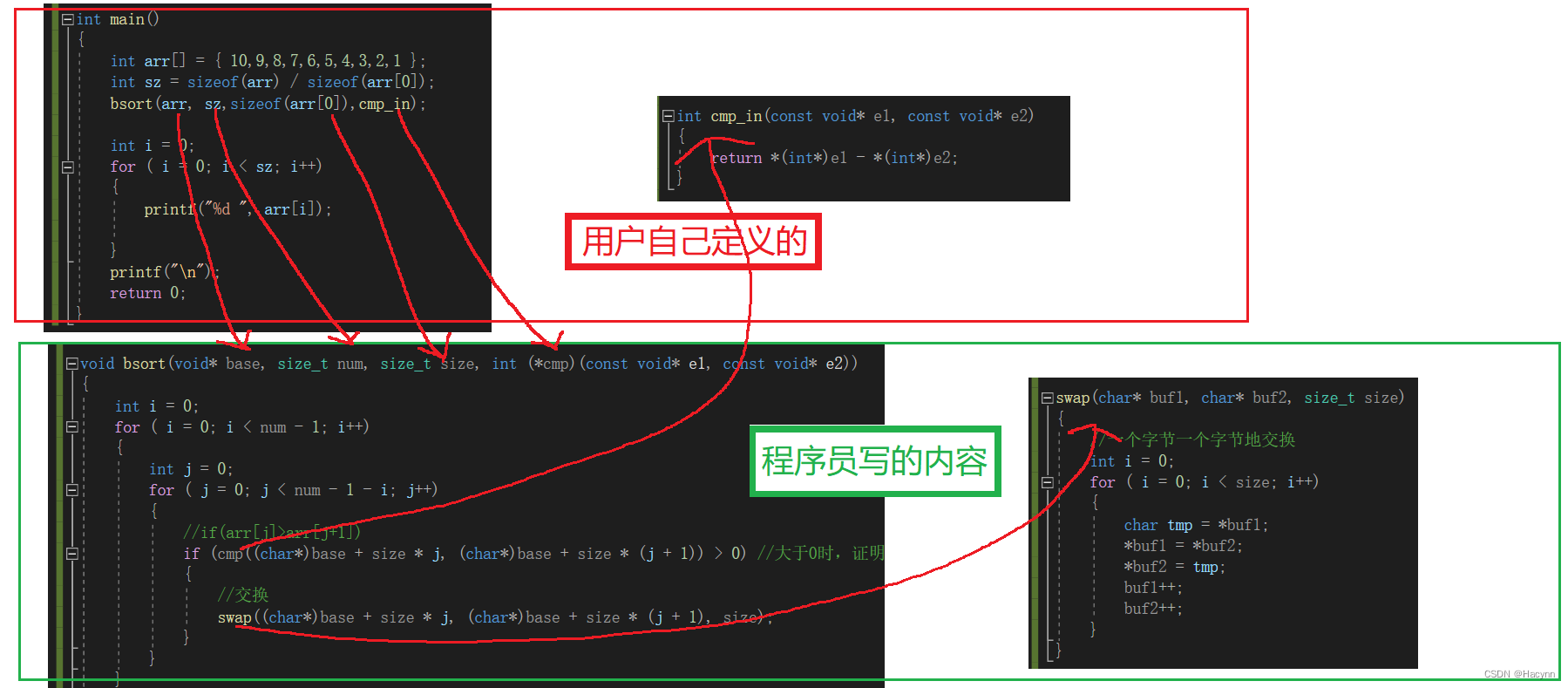
同理,结构体类型数据也能交换。
【交换结构体类型数据的完整代码】
swap(char* buf1, char* buf2, size_t size)
{
//一个字节一个字节地交换
int i = 0;
for ( i = 0; i < size; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bsort(void* base, size_t num, size_t size, int (*cmp)(const void* e1, const void* e2))
{
int i = 0;
for ( i = 0; i < num - 1; i++)
{
int j = 0;
for ( j = 0; j < num - 1 - i; j++)
{
//if(arr[j]>arr[j+1])
if (cmp((char*)base + size * j, (char*)base + size * (j + 1)) > 0) //大于0时,证明j的元素大于j+1的元素,所以要交换位置
{
//交换
swap((char*)base + size * j, (char*)base + size * (j + 1), size);
}
}
}
}
struct Stu
{
char name[20];
int age;
};
int cmp_stu_age(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int main()
{
struct Stu arr[] = { {"zhangsan",22},{"lisi",26},{"wangwu",20} };
int sz = sizeof(arr) / sizeof(arr[0]);
bsort(arr, sz,sizeof(arr[0]),cmp_stu_age);
printf("\n");
return 0;
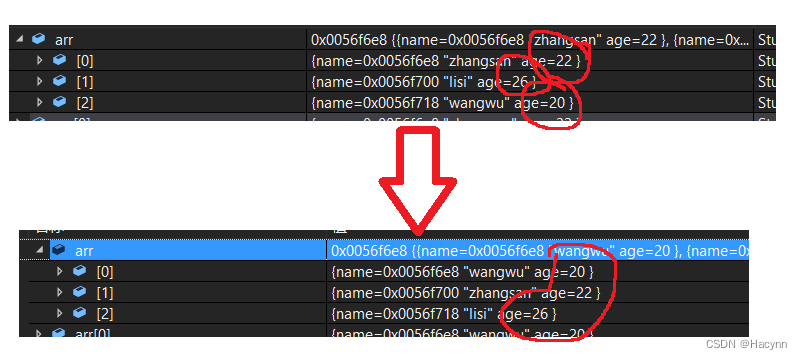
}例子中是按照年龄排序。使用调试检查一下,确实完成了交换:
如果想要进行降序排序的话,只需要将用户自行创建并封装的 cmp函数 中return的e1和e2交换即可,下面以cmp_int为例:
swap(char* buf1, char* buf2, size_t size)
{
//一个字节一个字节地交换
int i = 0;
for ( i = 0; i < size; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bsort(void* base, size_t num, size_t size, int (*cmp)(const void* e1, const void* e2))
{
int i = 0;
for ( i = 0; i < num - 1; i++)
{
int j = 0;
for ( j = 0; j < num - 1 - i; j++)
{
//if(arr[j]>arr[j+1])
if (cmp((char*)base + size * j, (char*)base + size * (j + 1)) > 0) //大于0时,证明j的元素大于j+1的元素,所以要交换位置
{
//交换
swap((char*)base + size * j, (char*)base + size * (j + 1), size);
}
}
}
}
int cmp_in(const void* e1, const void* e2)
{
return *(int*)e2 - *(int*)e1; //进行【降序】排序
}
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
bsort(arr, sz,sizeof(arr[0]),cmp_in);
return 0;
}2、指针和数组笔试题解析
计算下面运算输出的值
2.1、一维数组
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a + 0));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a));
printf("%d\n", sizeof(*&a));
printf("%d\n", sizeof(&a + 1));
printf("%d\n", sizeof(&a[0]));
printf("%d\n", sizeof(&a[0] + 1));
【答案】32位环境下运行的结果
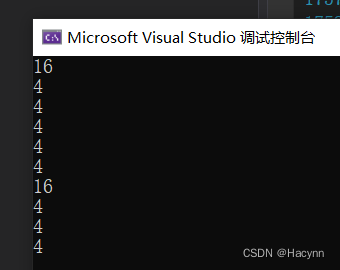
【解析】
printf("%d\n", sizeof(a));sizeof(数组名),这里的数组名表示整个数组,所以计算的是整个数组的大小,4(int字节数)*4=16。
printf("%d\n", sizeof(a + 0));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址,a+0还是首元素的地址,32位环境下,地址大小就是4。
printf("%d\n", sizeof(*a));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址。*a 就是 首元素,大小就是4 ,特别的:*a == *(a+0) == a[0]
printf("%d\n", sizeof(a + 1));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址,a+1就是第2个元素的地址,32位环境下,地址大小就是4。
printf("%d\n", sizeof(a[1]));a[1]就是数组的第二个元素,这里计算的就是第二个元素的大小,int就是4。
printf("%d\n", sizeof(&a));&a - 是取出数组的地址,但是数组的地址也是地址,32位环境下,是地址就是4。数组的地址 和 数组首元素的地址 的本质区别是类型的区别,并非大小的区别。
printf("%d\n", sizeof(*&a));对数组指针解引用访问一个数组的大小,单位是字节,也可以理解成 *&相互抵消,即sizeof(*&a) = sizeof(a),sizeof(数组名),这里的数组名表示整个数组,所以计算的是整个数组的大小。
printf("%d\n", sizeof(&a + 1));&a数组的地址,&a+1还是地址,是地址就是4。
printf("%d\n", sizeof(&a[0]));&a[0]是首元素的地址,计算的是地址的大小4。
printf("%d\n", sizeof(&a[0] + 1));&a[0]是首元素的地址,&a[0]+1就是第二个元素的地址,大小4。
2.2、字符数组
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));【答案】 32位环境下运行的结果
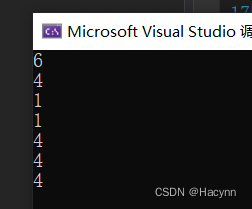
【解析】
printf("%d\n", sizeof(arr));数组名arr单独放在sizeof内部,计算的是整个数组的大小6。
printf("%d\n", sizeof(arr + 0));arr是首元素的地址==&arr[0],是地址就是4。
- 指针变量的大小和类型无关,不管什么类型的指针变量,大小都是4/8个字节
- 指针变量是用来存放地址的,地址存放需要多大空间,指针变量的大小就是几个字节
- 32位环境下,地址是32个二进制位,需要4个字节,所以指针变量的大小就是4个字节
- 64位环境下,地址是64个二进制位,需要8个字节,所以指针变量的大小就是8个字节
printf("%d\n", sizeof(*arr));arr是首元素的地址,*arr就是首元素,大小就是1。
printf("%d\n", sizeof(arr[1]));arr[1]就是第2个元素,大小就是1。
printf("%d\n", sizeof(&arr));&arr是数组的地址,sizeof(&arr)就是4
printf("%d\n", sizeof(&arr + 1));&arr+1 是跳过数组后的地址, 是地址就是4。
printf("%d\n", sizeof(&arr[0] + 1));第二个元素的地址,是地址就是4。
看完sizeof了,再来看一组strlen
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));【答案】32位环境下运行的结果
1、随机值
2、随机值
3、err
4、err
5、随机值
6、随机值-6
7、随机值-1
【解析】
注意:题目中使用的是char arr[] = {'a','b','c','d','e','f'};的创建方式,该方式不会自动在末尾添加\0,而strlen只有遇到\0才会停下
printf("%d\n", strlen(arr));arr是首元素的地址,就是从arr第一个元素开始,找\0,由于不知道后面\0在哪个位置,因此是随机值。
printf("%d\n", strlen(arr + 0));arr是首元素的地址, arr+0还是首元素的地址,与上一题同理,是随机值。
printf("%d\n", strlen(*arr));arr是首元素的地址, *arr就是首元素,srtlen需要接收一个地址,而这里传递的是一个字符,站在strlen的角度,认为传参进去的'a'-97就是地址,97作为地址,直接进行访问,就是非法访问,因此程序会报错。
printf("%d\n", strlen(arr[1]));arr第二个元素地址'b',与上一题同理,非法访问程序报错。
printf("%d\n", strlen(&arr));&arr表示整个数组的地址,向后查找\0,因此是随机值。
printf("%d\n", strlen(&arr + 1));&arr表示整个数组的地址,&arr + 1表示跳过整个数组(6个字节)向后查找\0,因此是随机值-6。
printf("%d\n", strlen(&arr[0] + 1));&arr[0]表示首元素地址,&arr[0] + 1跳过一个元素,向后查找\0,因此是随机值-1。
下面换成char arr[] = "abcdef";再来看看
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));【答案】32位环境下运行的结果

【解析】
printf("%d\n", sizeof(arr));sizeof(数组名)表示整个数组,sizeof是会把\0也计入在内的,因此是7。
printf("%d\n", sizeof(arr + 0));arr+0表示首元素地址,是地址就是4。
printf("%d\n", sizeof(*arr));*arr表示首元素,首元素是char类型,所以就是1。
printf("%d\n", sizeof(arr[1]));第二个元素,所以就是1。
printf("%d\n", sizeof(&arr));&arr表示整个数组的地址, 是地址就是4
printf("%d\n", sizeof(&arr + 1));&arr表示整个数组的地址, &arr + 1表示跳过整个数组,是地址就是4。
printf("%d\n", sizeof(&arr[0] + 1));第一个元素的地址,是地址就是4。
换成srtlen
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));【答案】
1、6
2、6
3、err
4、err
5、6
6、随机值
7、5
【解析】
printf("%d\n", strlen(arr));统计\0前有多少个元素,就是6。
printf("%d\n", strlen(arr + 0));arr+0等于首元素地址,统计\0前有多少个元素,就是6。
printf("%d\n", strlen(*arr));*arr表示首元素,把元素作为地址直接进行访问,就是非法访问,因此程序会报错。
printf("%d\n", strlen(arr[1]));与上一题同理,非法访问程序报错。
printf("%d\n", strlen(&arr));&arr表示整个数组的地址,向后找\0所以是6。
printf("%d\n", strlen(&arr + 1));&arr表示整个数组的地址,&arr + 1表示跳过了一整个数组,跑到了\0之后,无法知道下一个\0在哪里,所以是随机值。
printf("%d\n", strlen(&arr[0] + 1));&arr[0] + 1 表示第二个元素的地址,向后找\0等于5。
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!








